




 本文介绍了MapReduce编程模型,源自Google的分布式数据处理方式。它包括MapReduce简介、优缺点、系统架构、数据流以及Flume配置。重点讲解了如何使用MapReduce统计文本中单词出现次数,详细阐述了Map和Reduce阶段的工作原理,以及Word Count的Java API实现。文章还提及了Combiner在减少网络传输中的作用。
本文介绍了MapReduce编程模型,源自Google的分布式数据处理方式。它包括MapReduce简介、优缺点、系统架构、数据流以及Flume配置。重点讲解了如何使用MapReduce统计文本中单词出现次数,详细阐述了Map和Reduce阶段的工作原理,以及Word Count的Java API实现。文章还提及了Combiner在减少网络传输中的作用。
MapReduce(一)
MapReduce简介
什么是MapReduce?
-
是一种大规模数据处理的编程模型
-
源自于2004年Google发布的论文
-
MapReduce in Hadoop
- 开源社区实现版本,核心代码使用Java实现

- 开源社区实现版本,核心代码使用Java实现
MapReduce计算场景
- 数据查找
- 分布式Grep
- Web访问日志分析
- 词频统计
- 网站PV UV统计
- TOP K问题
- 倒排索引
- 建立搜索引擎索引
- 分布式排序
MapReduce优缺点
- 优点
- 模型简单
- Map + Reduce
- 高伸缩性
- 支持横向扩展
- 灵活
- 结构化和非结构化数据
- 速度快
- 高吞吐离线处理数据
- 并行处理
- 编程模型天然支持并行处理
- 容错能力强
- 模型简单
- 缺点
- 流式数据-MapReduce处理模型就决定了需要静态数据
- 实时计算-不适合低延迟数据处理,需要毫秒级别响应
- 复杂算法-例如SVM支持向量机
- 迭代运算-例如斐波那契数列
系统架构

数据流

Flume配置
# 配置Agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置Source
a1.sources.r1.type = exec
a1.sources.r1.channels = c1
a1.sources.r1.deserializer.outputCharset = UTF-8
# 配置需要监控的日志输出目录
a1.sources.r1.command = tail -F
/data/log/nginx/nginx_access.log
# 配置Channel
a1.channels.c1.type = memory
# channel中的最大event数目
a1.channels.c1.capacity = 1000
# channel中允许事务的最大event数目
a1.channels.c1.transactionCapacity = 100
# 配置Sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# hdfs的上传路径
a1.sinks.k1.hdfs.path = hdfs://master:8020/user/jeremy/opencart_nginx_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = %Y-%m-%d-%H
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
# 为了让flume感知不到hdfs的块复制
a1.sinks.k1.hdfs.minBlockReplicas = 1
# 间隔多久产生新文件
a1.sinks.k1.hdfs.rollInterval = 600
# 文件到达多大再产生一个新文件 bytes
a1.sinks.k1.hdfs.rollSize = 1000000
# event达到多大再产生一个新文件
a1.sinks.k1.hdfs.rollCount = 10000
运行flume
nohup bin/flume-ng agent -n a1 -c conf -f conf/flume-nginx-log-hdfs.properties 2>&1 &
MapReduce编程模型
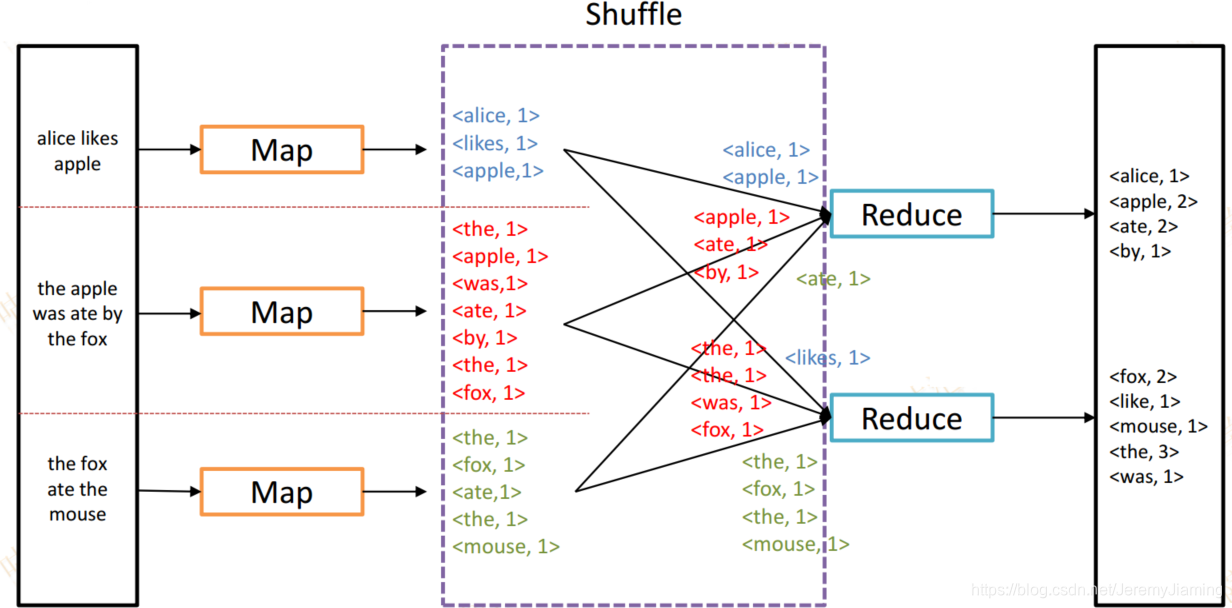
如何统计一个文本中单词的出现次数?
- Bash命令实现
- tr -s " " “\n”
- sort file
- uniq –c
- cat wordcount.txt | tr -s " " “\n” | sort | uniq -c
- 单机版实现
- 使用HashMap统计
- 如果数据量极大如何在分布式的机器上计算?
- MapReduce使用了分治思想简化了计算处理模型为两步:
- Map阶段
- 获得输入数据
- 对输入数据进行转换并输出
- Reduce阶段
- 对输出结果进行聚合计算
- Map阶段
MapReduce-Map
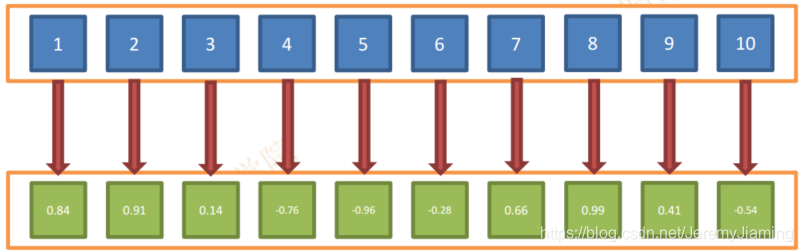
- 对输入数据集的每个值都执行函数以创建新的结果集合
- 例如:
- 输入数据[1,2,3,4,5,6,7,8,9,10]
- 定义Map方法需要执行的变换为f(x)=sin(x)
- 则输出结果为[0.84,0.91,0.14,-0.76,-0.96,-0.28,0.66,0.99,0.41,-0.54]
- 形式化的表达:
- each <key, value> in input
- map <key, value> to <intermediate key, intermediate value>
MapReduce-Reduce
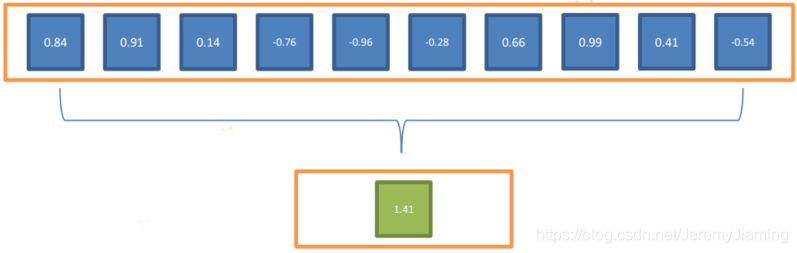
- 对Map输出的结果进行聚合,输出一个或者多个聚合结果
- 例如:
- Map的输出结果为[0.84,0.91,0.14,-0.76,-0.96,-0.28,0.66,0.99,0.41,-0.54]
- 使用求和+作为聚合方法
- 则输出结果为[1.41]
- 形式化的表达:
- each <intermediate key,List> in input
- reduce<reduce key, reduce value>
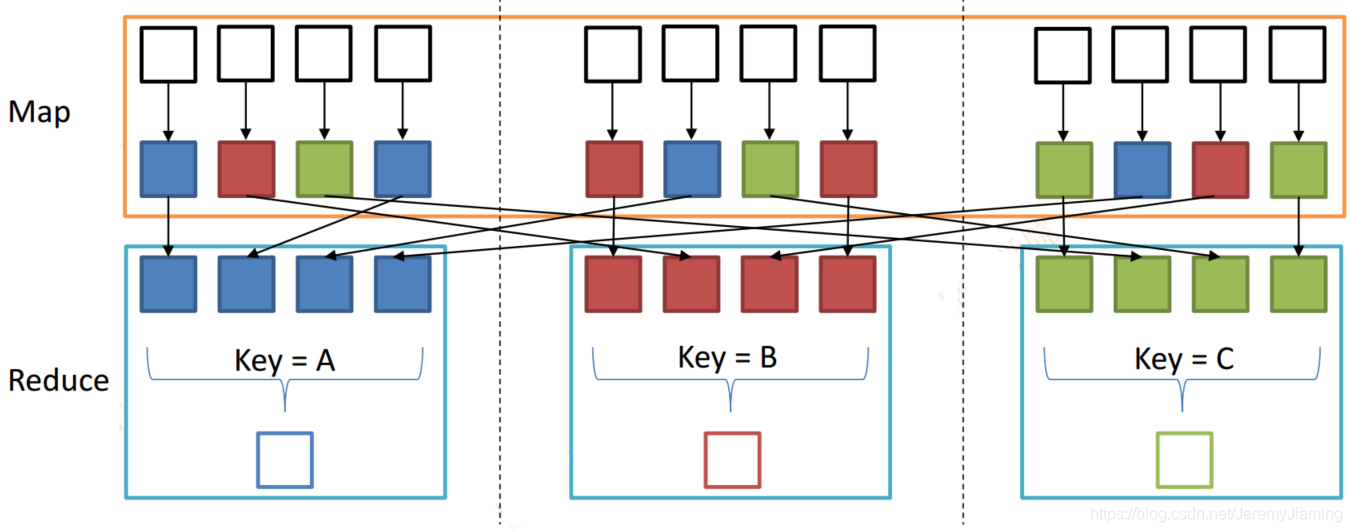
- 相同的key会被划分到同一个Reduce上
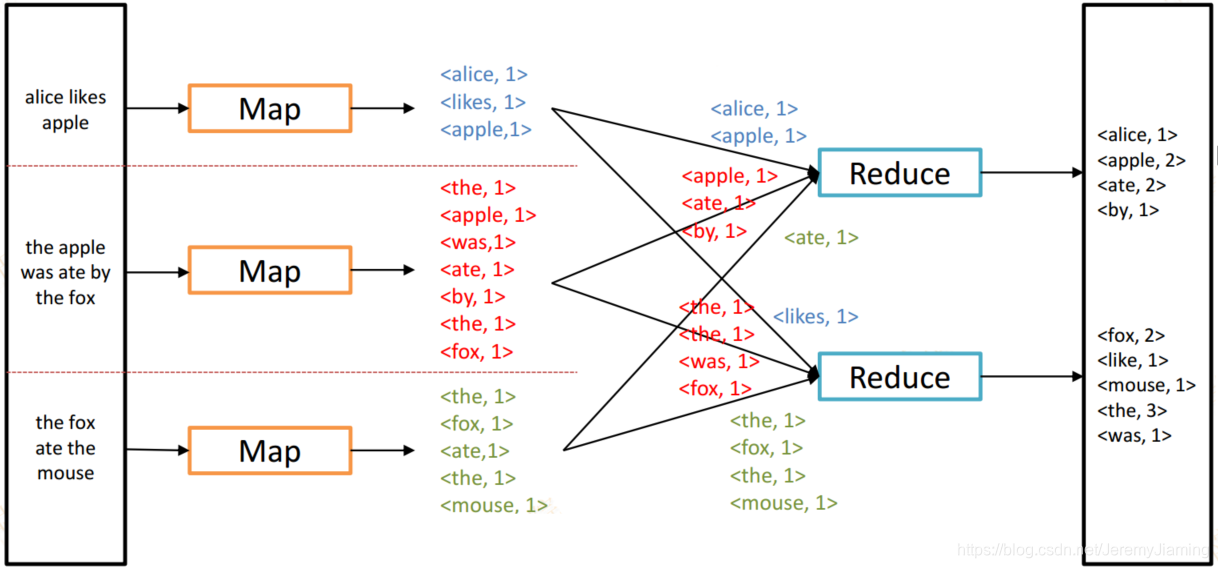
Word Count Example
Map数据输入
- Map阶段由一定的数量的Map Task组成
- 文件分片
- 输入数据会被split切分为多份
- HDFS默认Block大小
- Hadoop 1.0 = 64MB • Hadoop 2.0 = 128MB
- 默认将文件解析为<key,value>对的实现是TextInputFormat
- key为偏移量
- value为每一行内容
- 输入数据会被split切分为多份
- 因此有多少个Map Task任务?
- 一个split一个Map Task,默认情况下一个block对应一个split
- 例如一个文件大小为10TB,block大小设置为128MB,则一共会有81920 个Map Task任务(10 * 1024 * 1024 / 128 = 81920)
Reduce 数据输入
- Partitioner决定了哪个Reduce会接收到Map输出的<key, value>对
- 在Hadoop中默认的Partitioner实现为HashPartitioner
- 计算公式
- Abs(Hash(key)) mod NR 其中 NR等于Reduce Task数目
- Partitioner可以自定义
- 例如
- 有3个Reduce Task
- 那么Partitioner会返回0 ~ 2
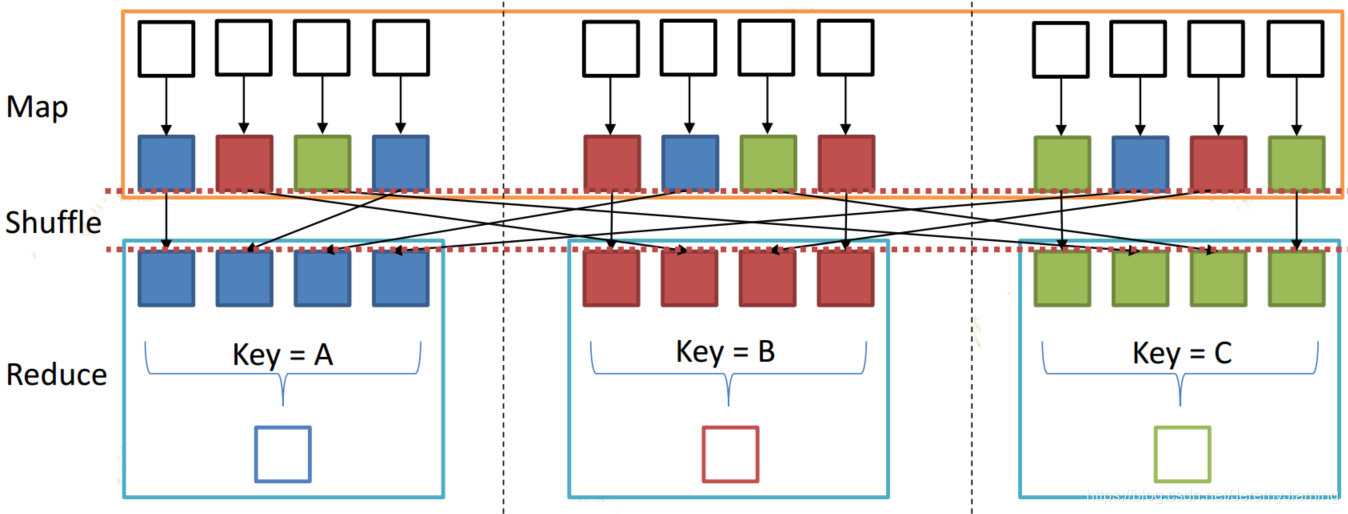
MapReduce-Shuffle
Word Count中的shuffle
shuffle
- 为何需要shuffle
- Reduce阶段的数据来源于不同的Map
- Shuffle由Map端和Reduce端组成
- Shuffle的核心机制
- 数据分区+排序
- Map端
- 对Map输出结果进行spill(溢写)
- Reduce端
- 拷贝Map端输出结果到本地
- 对拷贝的数据进行归并排序
Shuffle Map端
- Map端会源源不断的把数据输入到一个环形内存缓冲区
- 达到一定阈值时
- 新启动一个线程
- 内存缓冲区中的数据会溢出到磁盘
- 在溢出的过程中
- 调用Partitioner进行分组
- 对于每个组,按照Key进行排序
- Map处理完毕后
- 对溢出到磁盘上的多个文件进行Merge操作
- 合并为一个大的文件和一个索引文件
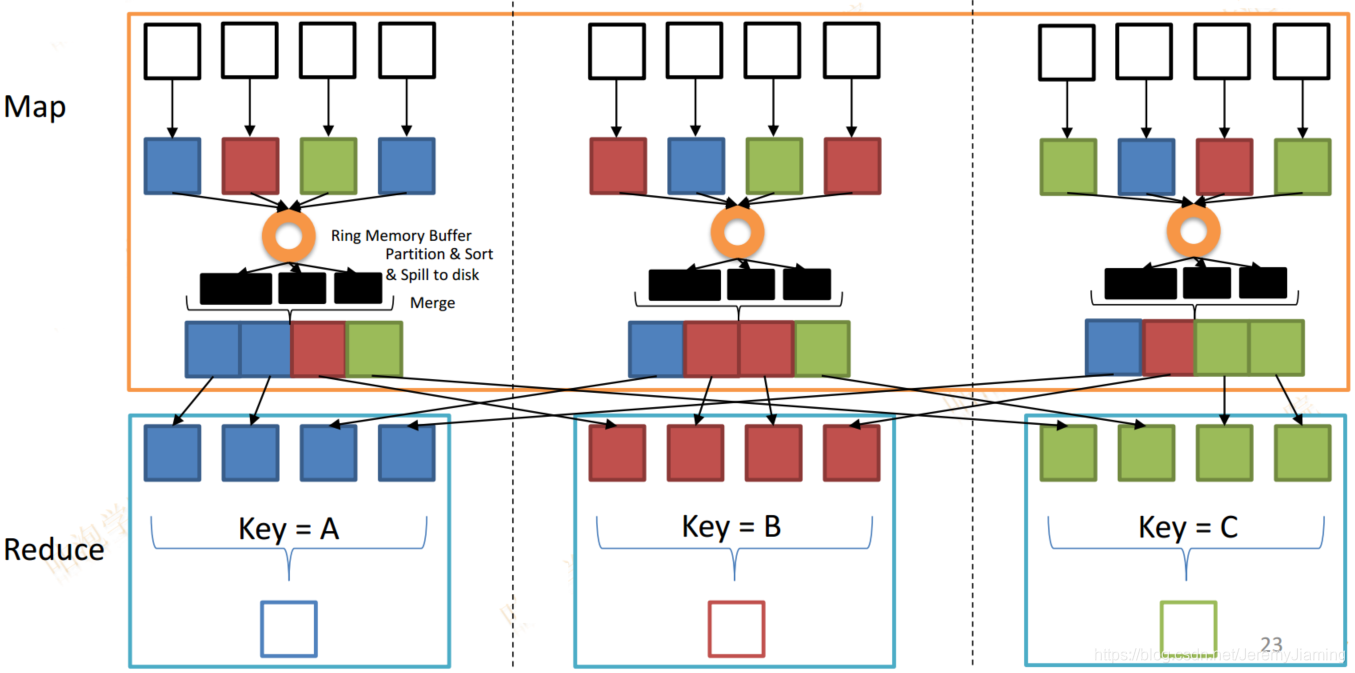
Shuffle Reduce端
- Map端完成之后会暴露一个Http Server共Reduce端获取数据
- Reduce启动拷贝线程从各个Map端拷贝结果
- 有大量的网络I/O开销
- 一边拷贝一边进行Merge操作(归并排序)
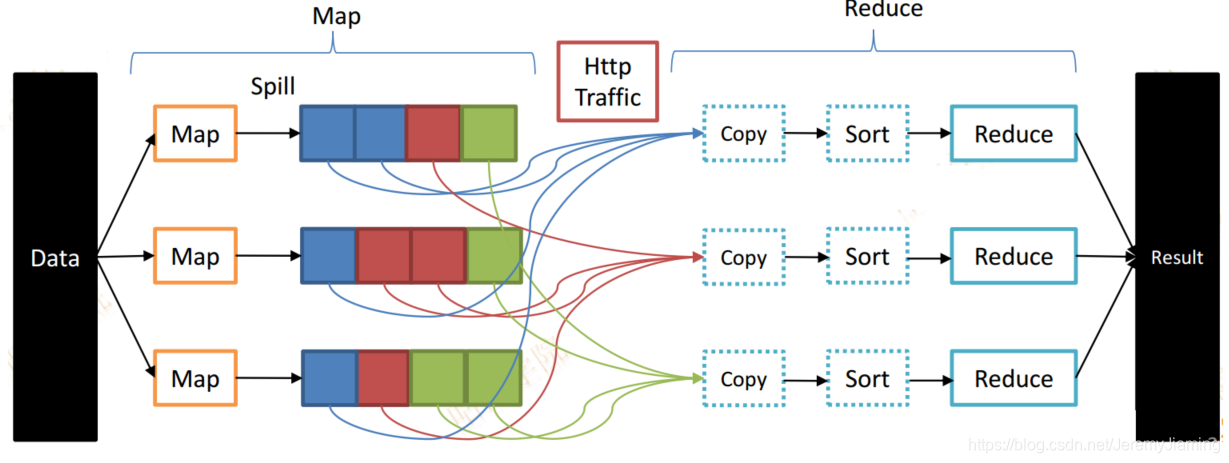
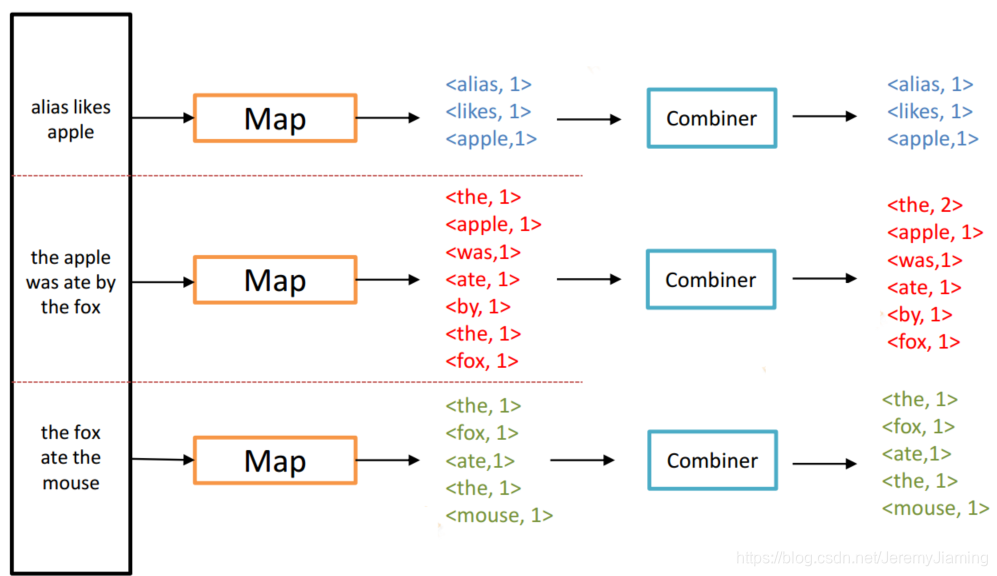
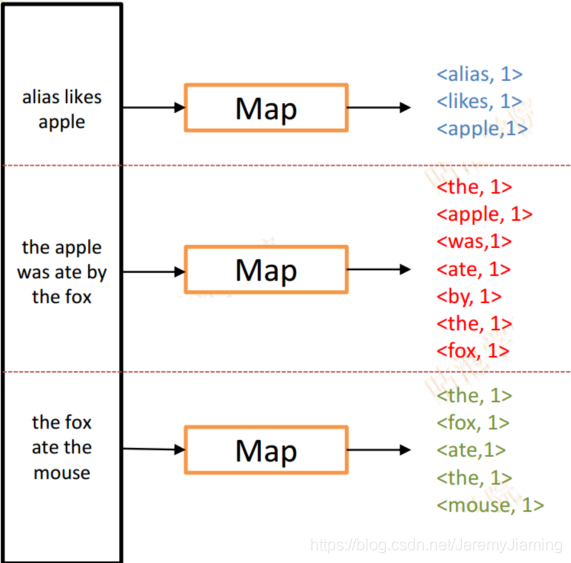
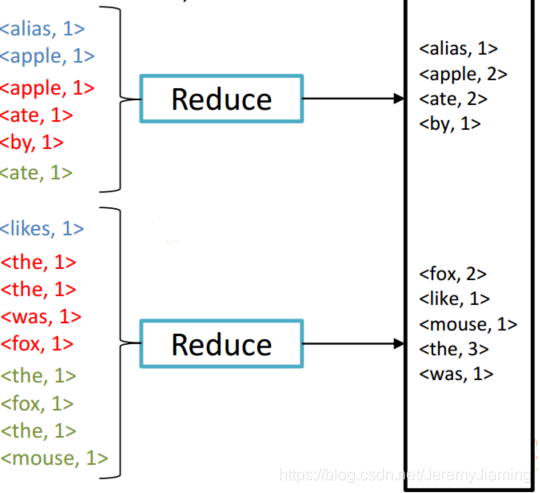
Combiner
- Map端本地Reducer
- 合并了Map端输出数据 => 减少Http Traffic
- Combiner可以自定义
- 例如Word Count中
- 对同一个Map输出的相同的key,直接对其value进行reduce
- 可以使用Combiner的前提
- 满足结合律:求最大值、求和
- 不适用场景:计算平均数
Combiner Example
MapReduce Java API
- 基于Hadoop 2.6.0版本
- 新版本API均在包org.apache.hadoop.mapreduce下面
- 编写MapReduce程序的核心
- 继承Hadoop提供的Mapper类并实现其中的map方法
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> - 继承Hadoop提供的Reducer类并实现其中的reduce方法
public class Reducer<KEYIN,VALUEIN, KEYOUT,VALUEOUT>
- 继承Hadoop提供的Mapper类并实现其中的map方法
WordCount Mapper实现
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
WordCount Reducer实现
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
WordCount Main方法实现
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
WordCount 编译和执行
- 通过mvn compile package将code打包成jar
- 将example数据上传至HDFS
- hadoop fs -mkdir /user/bill/wordcount/input
- hadoop fs -put example.txt /user/bill/wordcount/input
- 使用hadoop jar命令执行
- hadoop jar命令格式:
hadoop jar [job jar file path] [main class] [arg1] [arg2] …
hadoop jar example.jar wordcount /user/bill/wordcount/input /user/bill/wordcount/output

















 1104
1104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









