




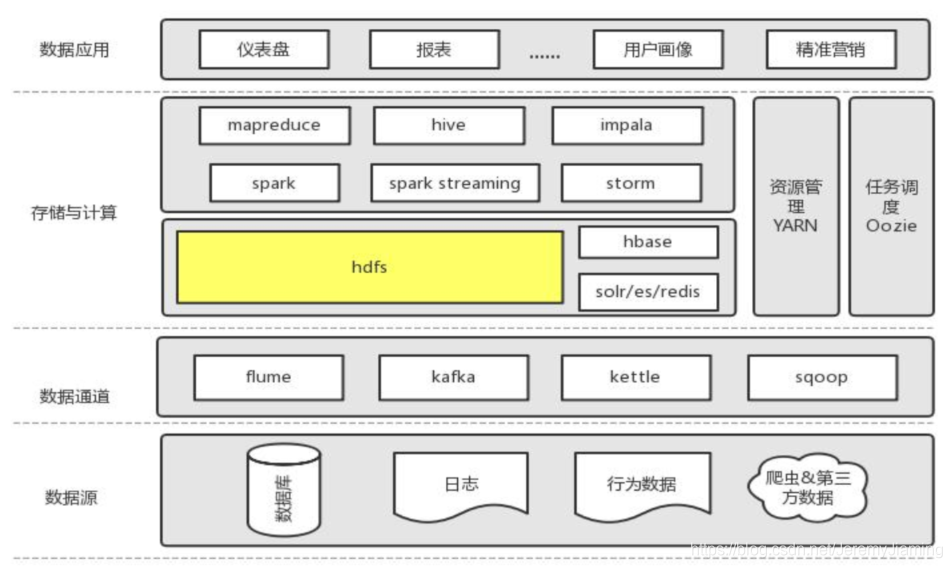
 本文详细介绍了HDFS的分布式存储基石,包括其基本概念、工作原理、数据读写过程、Namenode的深入解析、HDFS HA机制以及常见问题。HDFS设计目标是存储超大文件和海量文件,支持顺序写入,强调硬件容错和高吞吐量。文中还讨论了小文件问题、NameNode管理以及如何扩展存储容量。
本文详细介绍了HDFS的分布式存储基石,包括其基本概念、工作原理、数据读写过程、Namenode的深入解析、HDFS HA机制以及常见问题。HDFS设计目标是存储超大文件和海量文件,支持顺序写入,强调硬件容错和高吞吐量。文中还讨论了小文件问题、NameNode管理以及如何扩展存储容量。
HDFS 分布式存储基石
HDFS简介
HDFS是Hadoop 分布式文件系统。
所处角色
基本概念
- 基于JAVA实现的一个分布式文件系统
- 基于unix/linux
- 是Hadoop最重要的核心组件
- 支持顺序写入,而非随机定位读写
HDFS前提和设计目标
-
存储超大文件
HDFS 适合存储大文件,单个文件大小通常在百MB以上
HDFS适合存储海量文件 -
硬件容错
基于普通机器搭建,硬件错误是常态而不是异常,因此错误检测和快速、自动的恢复是HDFS最核心的架构目标 -
流式数据访问
为数据批处理而设计,关注数据访问的高吞吐量 -
简单的一致性模型
一次写入,多次读取
一个文件经过创建、写入、关闭之后就不需要改变 -
本地计算
将计算移动到数据附近
HDFS构成及工作原理解析
基本构成
- 数据块
- 文件以块为单位进行切分存储,块通常设置的比较大(最小6M,默认128M)
- 块越大,寻址越快,读取效率越高,但同时由于MapReduce任务也是以块为最小单位来处理,所以太大的块不利于对数据的并行处理
- 一个文件至少占用一个块(逻辑概念)
- Namenode与Datanode
- namenode负责维护整个文件系统的信息,包括:整个文件树,文件的块分布信息,文件系统的元数据,数据复制策略等
- datanode存储文件内容存储文件内容,负责文件实际的读写操作,保持与namenode的通信,同步文件块信息
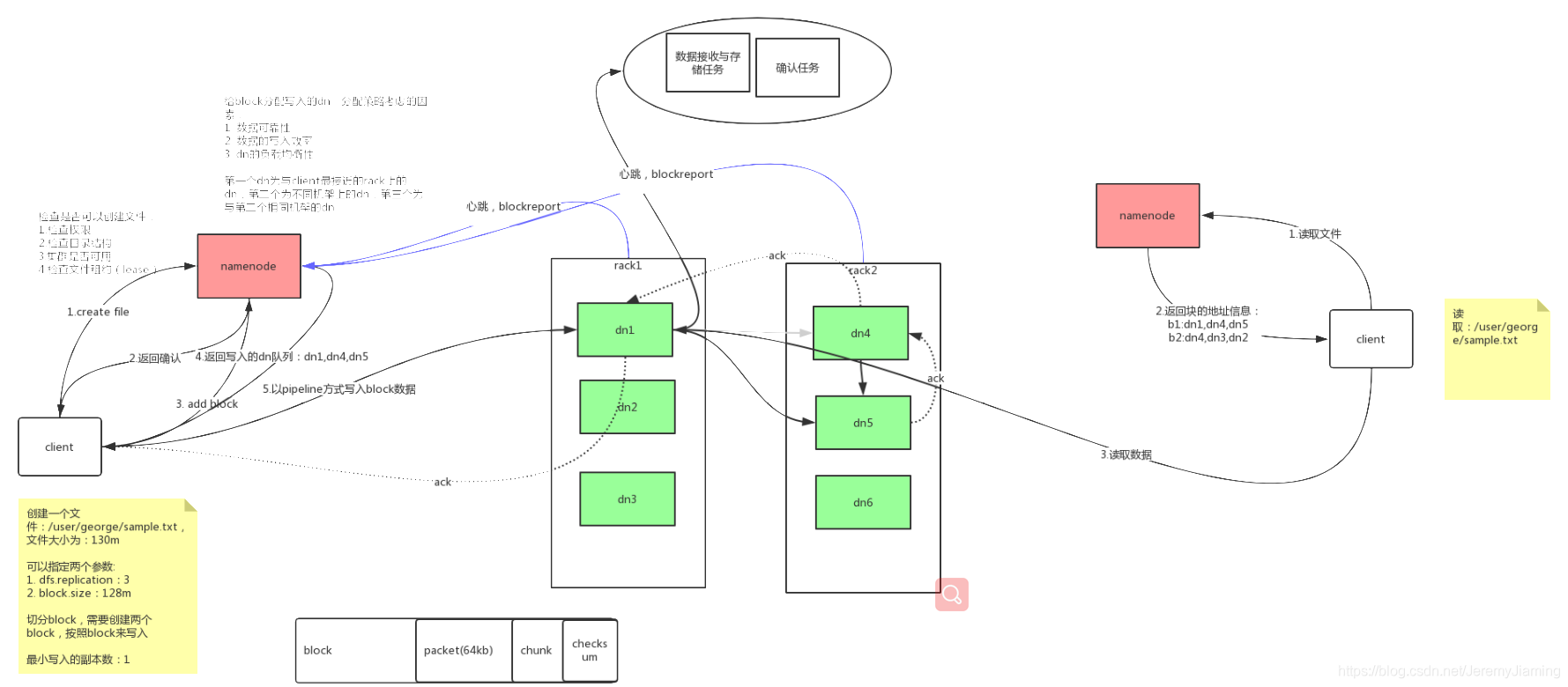
数据读写过程
集群结构

HDFS读取写入过程
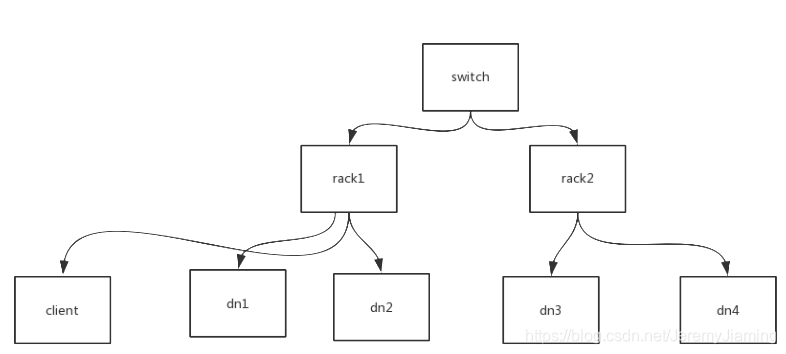
通过网络拓扑图判断距离
namenode深入
作用:
- Namespace管理:负责管理文件系统的树状目录结构以及文件与数据块的映射关系
- 块信息管理:负责管理文件系统中文件的物理块与实际存储位置的映射关系BlocksMap
- 集群信息管理:机架信息,datanode信息
- 集中式缓存管理:从Hadoop2.3开始,支持datanode将文件缓存到内存中,这部分缓存通过NN集中管理
存储结构:
- 内存:Namespace数据,BlocksMap数据,其他信息
- 文件:
- 已持久化的namespace数据:FsImage
- 未持久化的namespace操作:Edits
启动过程:
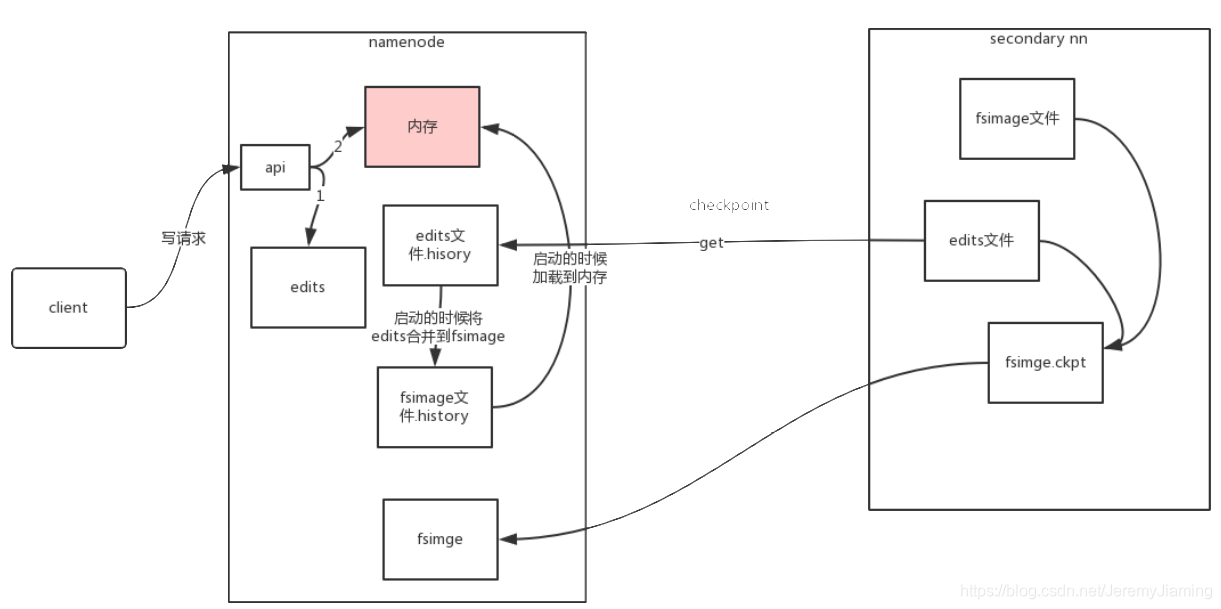
- 开启安全模式:不能执行数据修改操作
- 加载fsimage
- 逐个执行所有Edits文件中的每一条操作将操作合并到fsimage,完成后生成一个空的edits文件
- 接受datanode发送来的心跳消息和块信息
- 根据以上信息确定文件系统状态
- 退出安全模式
- 安全模式:文件系统只接受读数据请求,而不接受删除、修改等变更请求
- 什么情况下进入:NameNode主节点启动时,HDFS进入安全模式
- 什么时候退出:系统达到安全标准时,HDFS退出安全模式
- dfs.namenode.safemode.min.datanodes : 最小可用datanode数量
- dfs.namenode.safemode.threshold-pct : 副本数达到最小要求后的block占系统总block数的百分比
- dfs.namenode.safemode.extention : 稳定时间
- 相关命令:
- hdfs dfsadmin -safemode get : 查看当前状态
- hdfs dfsadmin -safemode enter : 进入安全模式
- hdfs dfsadmin -safemode leave : 强制离开安全模式
- hdfs dfsadmin -safemode wait : 一直等待直到安全模式结束
HDFS HA
- Datanode:通过数据冗余保证数据可用性
- Namenode:在2.0之前存在SPOF风险,从2.0后:
1.把name.dir指向NFS(Network File System)——冷备
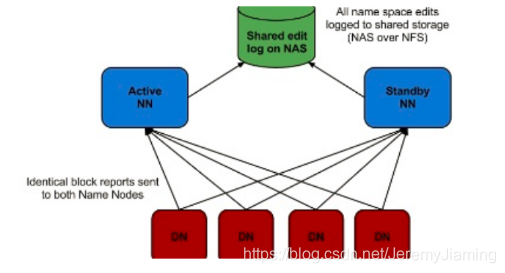
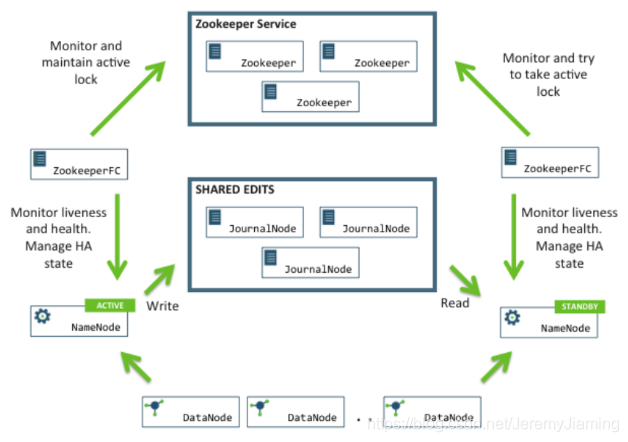
2.QJM方案(公司常用)——热备
HDFS文件格式
HDFS支持任意文件格式
HDFS文件类型
列式与行式存储
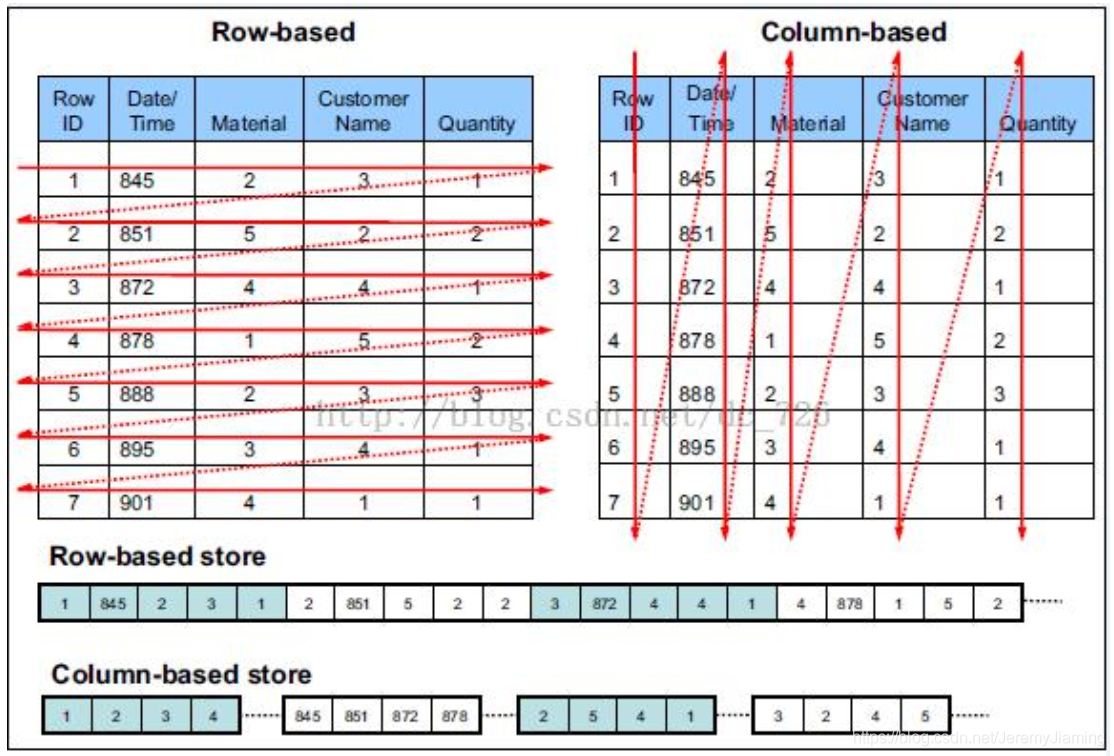
HDFS文件类型
常用文件类型
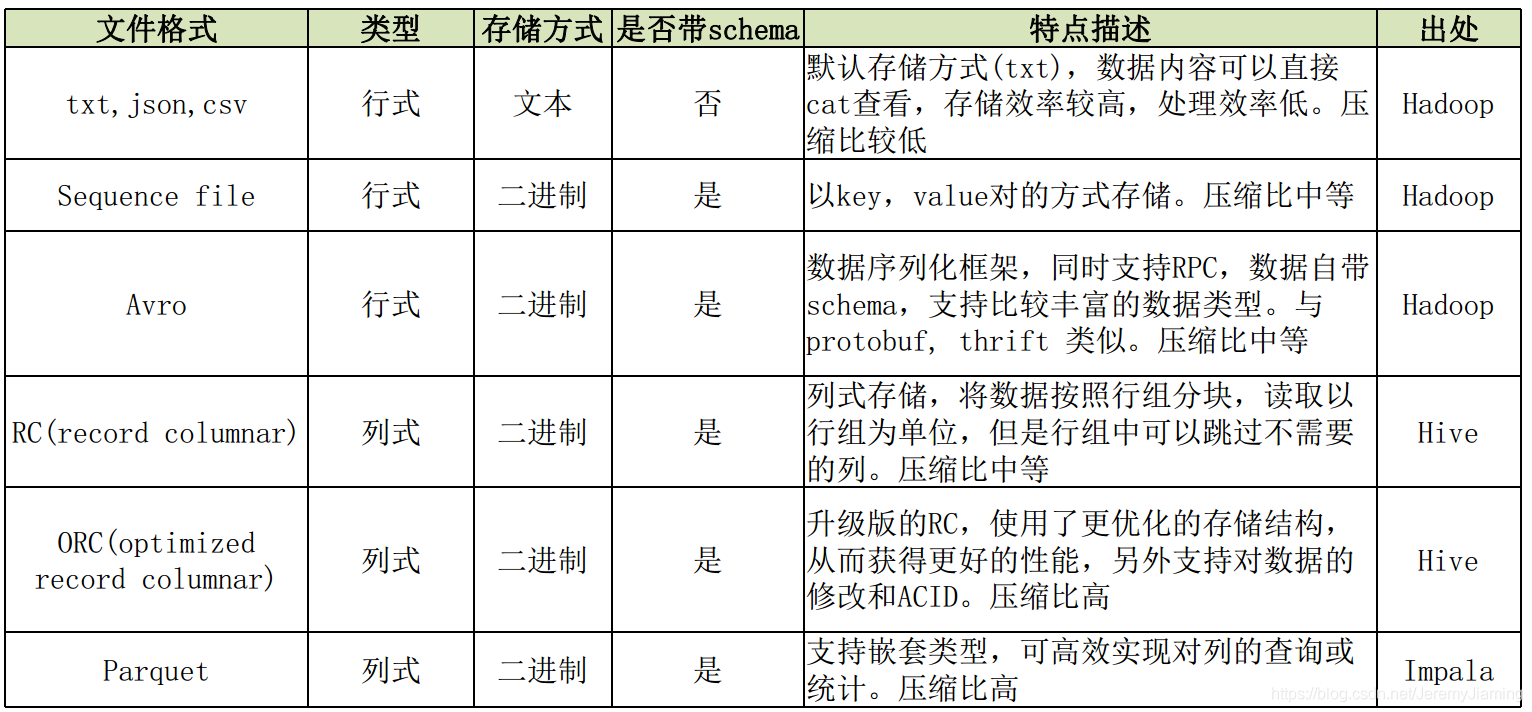
如何使用?
ALTER TABLE table_name SET FILEFORMAT PARQUET;
CREATE TABLE table_name (x INT, y STRING) STORED AS PARQUET;
SET hive.default.fileformat=Orc
HDFS常用设置及常见问题
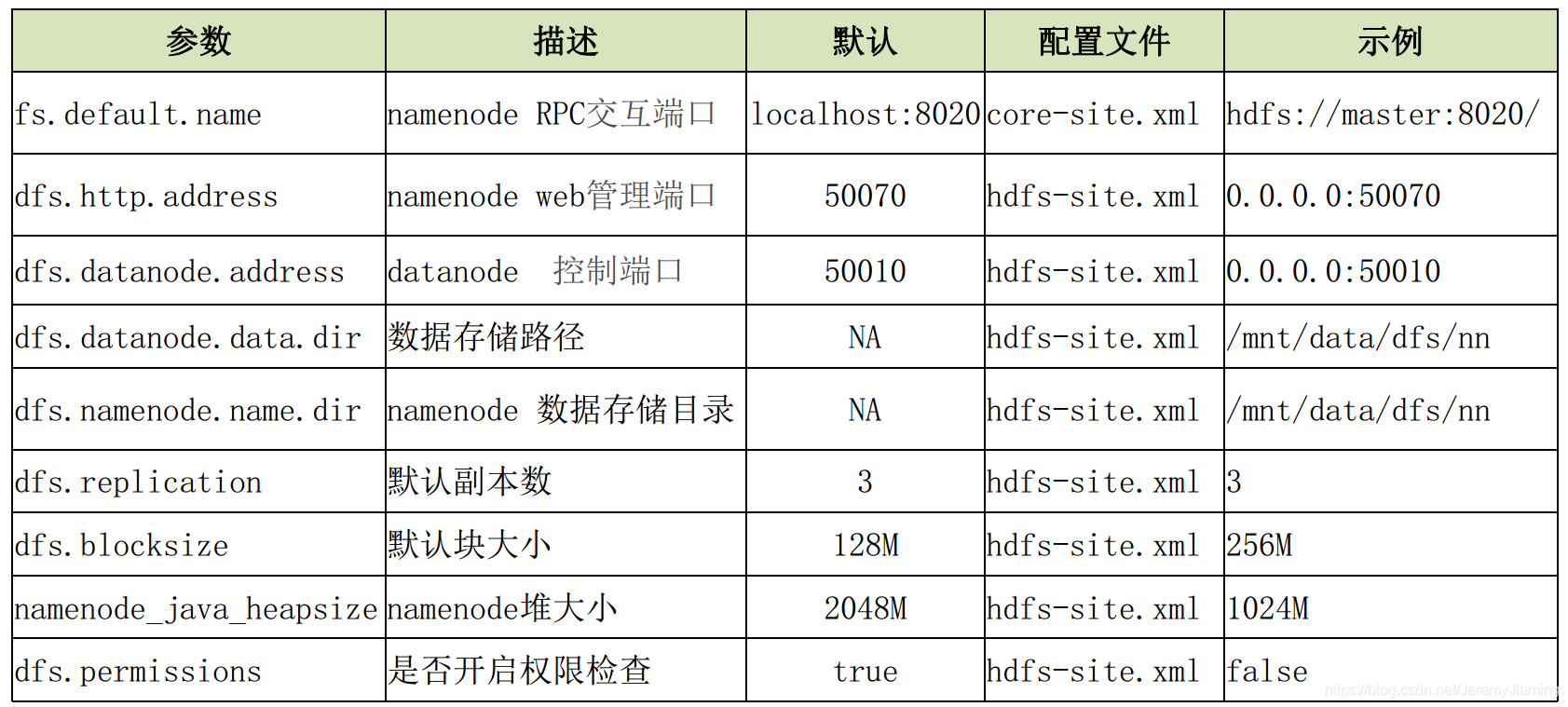
常用配置
配置文件路径:$ HADOOP_HOME $/etc/hadoop
主要配置文件:
- hdfs-site.xml
- core-site.xml
常见问题
- 小文件问题
- 定义: 大量大小小于块大小的文件
- 实际场景: 网页, Hive动态分区插入数据等
- 背景: 每个文件的元数据对象约占150byte, 所以如果有1千万个小文件,
- 每个文件占用一个block, 则NameNode大约需要2G空间。 如果存储1亿个文件, 则NameNode需要20G空间; 数据以块为单位进行处理。
- 影响: 占用资源, 降低处理效率
- 解决方案:
- 从源头减少小文件
- 使用archive打包
- 使用其他存储方式, 如Hbase, ES等
Namenode管理
大数据量下的namenode问题:
- 启动时间边长
- 性能开始下降
- NameNode JVM FGC风险较高
解决方案:
- 根据数据增长情况,预估namenode内存需求,提前做好预案
- 使用HDFS Federation,扩展NameNode分散单点负载
- 引入外部系统支持NameNode内存数据
- 合并小文件
- 调整合适的BlockSize
反思问题
- 数据块的复制策略?
- 调整块的大小会造成哪些影响?
- namenode 启动过程?
- namenode HA方案?
- secondary namenode 的作用?
- hdfs常用文件格式有哪些? 各有什么优缺点?
- 如何扩展HDFS的存储容量?

















 2345
2345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









