





图像由 DALL·E 3 生成
推理型大模型,是当前 AI 研究的热门话题。
我们从最早的 GPT-1 一路走到现在像 Grok-3 这样的高级推理模型。
这段旅程可以说非常精彩,过程中也发现了很多重要的推理方法。
其中之一就是 Chain-of-Thought(CoT)提示法(包括 few-shot 和 zero-shot),它引领了如今大模型推理的革命。
令人兴奋的是,现在又有了一个更强的新技术,由 Zoom Communications 的研究人员提出。
这个方法叫做 Chain-of-Draft(CoD)提示法,在回答问题时,仅用到 7.6% 的推理 token 就能在准确率上超过 CoT。
📌 本文是一线工程实践中挖掘出的前沿提示技术思路。
🔧 技术实战派|AI软硬件一体解决者
🧠 从芯片设计、电路开发、GPU部署 → Linux系统、推理引擎 → AI模型训练与应用
🚀 10年工程经验 + 商业认知,带你看懂真正落地的 AI 技术
📩 学AI?做AI项目?买AI训练推理设备?欢迎关注私信。
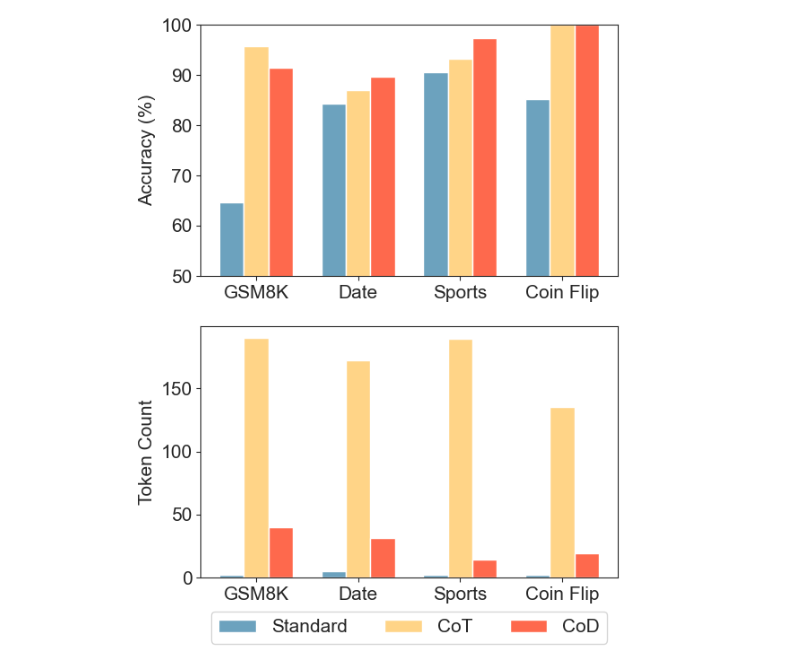
Claude 3.5 Sonnet 在不同推理任务中,使用标准提示(直接回答)、CoT 和 CoD 的准确率与 token 使用量对比
对于目前非常冗长、计算时间多、延迟高的大模型推理来说,这个方法可以说是一个巨大胜利。现实中很多对时间要求高的任务,都会受限于这些瓶颈。
我们下面就来讲个故事,深入看看 Chain-of-Draft(CoD)提示法到底是怎么运作的,以及你要怎么用它让你的 LLM 更加准确、更加省 token,前所未有。
但先说一下提示工程这回事
研究人员一直在不断探索 LLM 中的新行为。
从 Transformer 演变到生成式预训练模型 GPT,我们很快就发现,把模型扩展到 GPT-2(15 亿参数)后,它就能表现出无监督多任务学习能力(无需监督学习/任务专属数据集的微调,也能执行多种任务)。
当进一步扩展到 GPT-3(1750 亿参数)后,人们发现只要在输入中给出几个例子,它就能很快适应并很好地完成新任务(Few-shot 提示法)。
后来又有人发现,如果把问题拆解成中间推理步骤,并让大模型去生成这些步骤,就能在算术、常识、符号推理任务中达到 SOTA(state-of-the-art)性能。
这个方法就是 Chain-of-Thought(CoT)提示法。
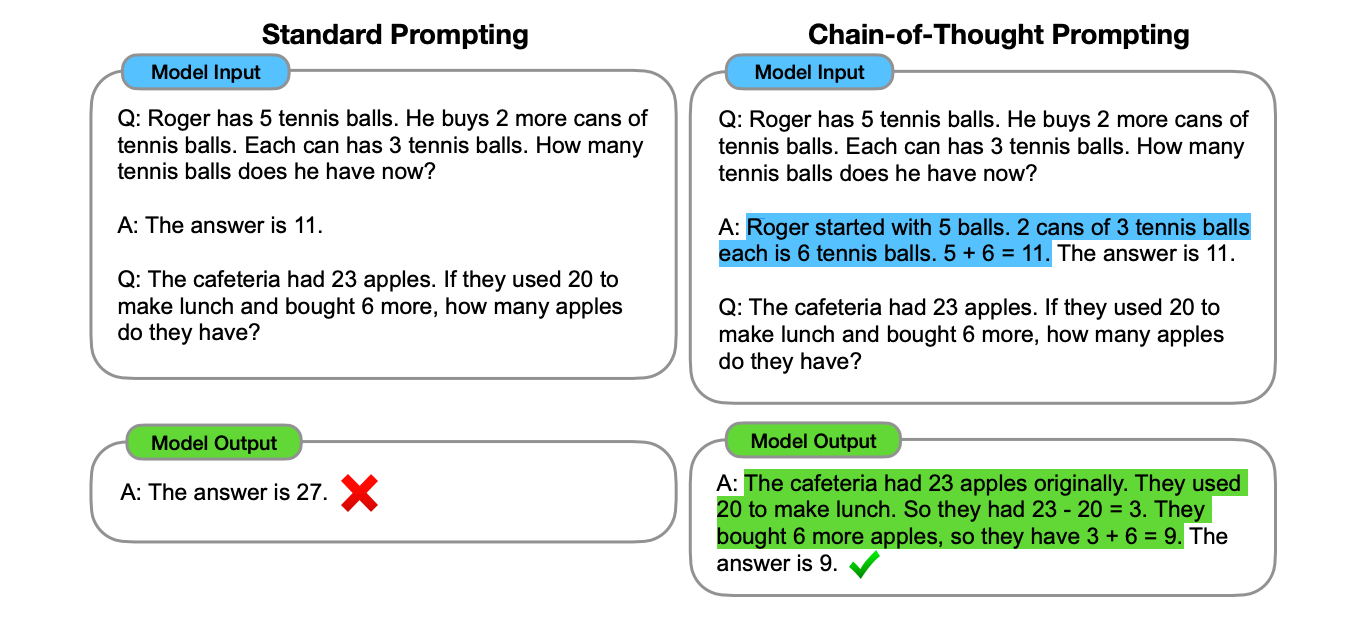
标准提示法 vs CoT 提示法示例(图片来自 ArXiv 论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》)
CoT 提出后,很快就发现其实 LLM 是 Zero-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1251
1251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









