




前言:
📌 本文是我在研究LLM推理优化过程中做的技术梳理,结合了二十多篇论文和实际工程经验。
🔧 技术实战派|AI软硬件一体解决者
🧠 从芯片设计、电路开发、GPU部署 → Linux系统、推理引擎 → AI模型训练与应用
🚀 现在专注用10年工程经验 + 商业认知,赋能AI产品从概念到落地
📩 学AI?做AI项目?搞AI训练推理设备?欢迎关注私信。
正文:
如果你正在开发AI解决方案,部署基于大型语言模型(LLM)的基础模型,那么你就得认真考虑它们的服务成本了。但我跟你说,钱不是唯一的问题 —— 要是你搞不定模型性能的问题,就算你预算再高,也一样跑不顺LLM。这篇文章就是来讲:怎么把LLM推理,从一个“烧钱怪”变成高吞吐的引擎。
目录
- LLM服务中的难题
- 第一主题:聪明的KV缓存管理
- 第二主题:Query稀疏注意力
- 第三主题:猜测式解码
- 第四主题:权重调度
- 第五主题:系统级优化
- 其他主题
- 技术实操:这些招怎么用
LLM服务中的难题
LLM确实很牛,但它们的特点也决定了:部署起来非常难。LLM的推理过程分成两个阶段:
- 预填充(Prefilling):你一输入提示(上下文、聊天记录、问题等等),模型就会一次性处理所有的tokens。
- 解码(Decoding):初始提示处理完后,模型就会一个一个token地往外生成。新的token依赖前面的。
为了让你更容易理解,预填充就像下象棋前摆好棋盘(比较耗时),而解码就像一步一步走棋(每步很快)。
但很遗憾,LLM部署可不是“吃块蛋糕”那么轻松,有几个大坑必须避:
稀疏性(Sparsity)
在神经网络里,尤其是FFN层,很多神经值其实是0。如果我们能跳过这些0值,只处理非零元素,就能省不少计算时间。
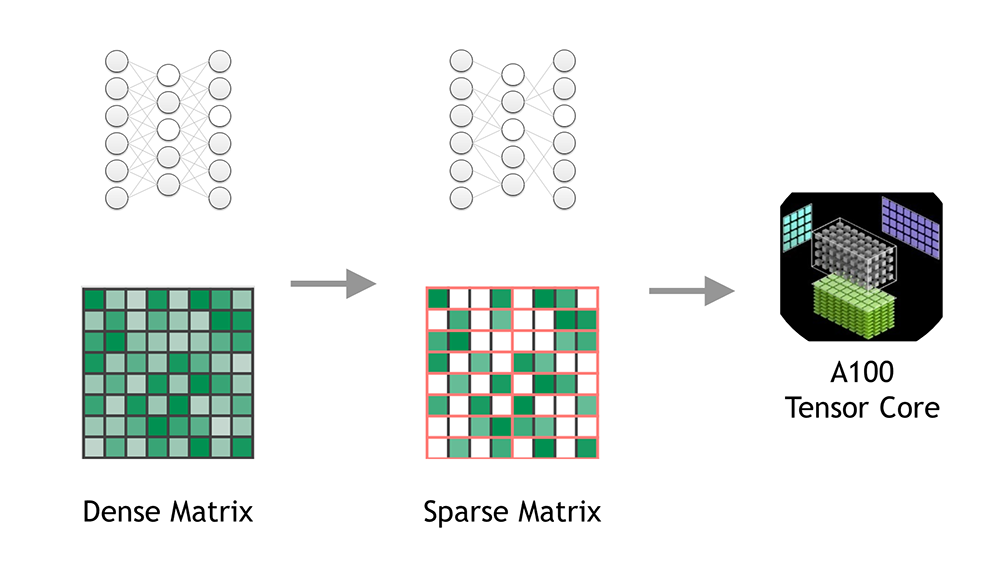 好些LLM神经值是0,导致矩阵乘法里也是零成片
好些LLM神经值是0,导致矩阵乘法里也是零成片
显存带宽瓶颈 & 内存受限(Memory Bandwidth Limits and Memory Bound)
GPU上传/下载数据的时间,常常比计算本身还久。而像ChatGPT这种传说中有一万亿参数的大模型,根本装不进单个GPU。
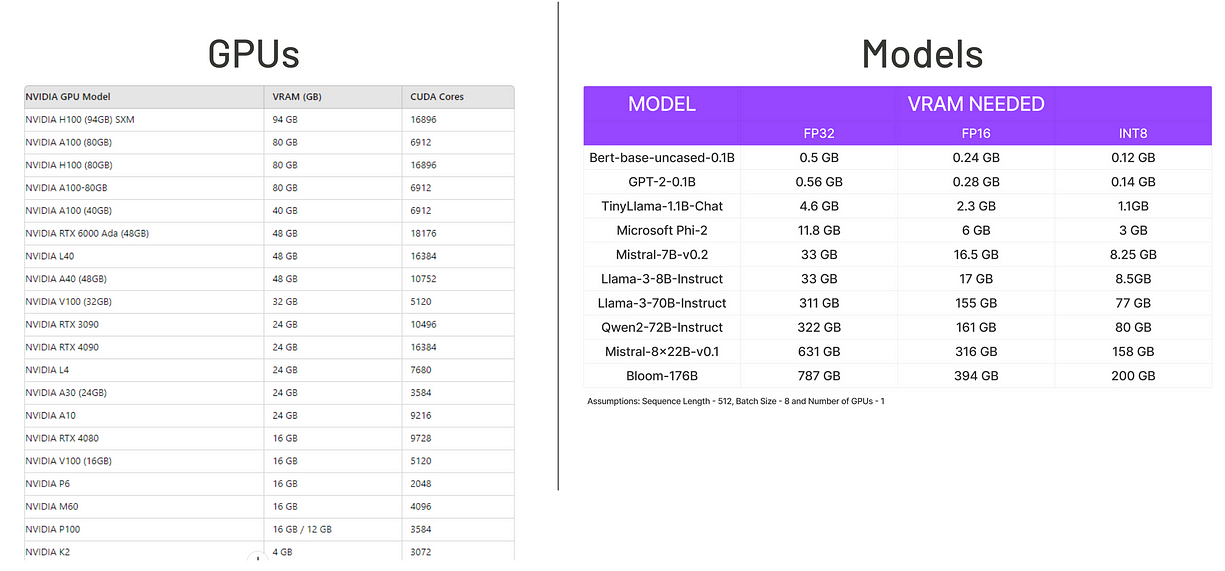 模型规模 vs GPU显存对比。
模型规模 vs GPU显存对比。
调度太差——先来先服务(Poor Scheduling)
LLM通常要同时处理多个请求。结果就是,短请求(比如问天气、时间)要等长请求处理完才轮到。这样平均响应时间全都卡在“等”上了,而不是“算”。
 你再快,也得等别人先来。
你再快,也得等别人先来。
解码是串行的(Sequential Decoding)
你没法并行生成token。每次前向传播只能出一个token(或者一小批)。这就是为啥你问ChatGPT一长段,它是一个词一个词吐出来的 —— 所以“流式输出”其实比“全生成完再给你”还舒服。
一步步解码。图源:ChatGPT
KV缓存增长(KV cache growth)
注意力计算覆盖整个序列,是LLM推理最核心也是最耗资源的操作。每次生成token时,它还要重复前面很多计算。Key-Value缓存就是帮你记住前面步骤里有用的信息。用KV cache,GPT2在T4 GPU上能加速5倍。下面图展示了有缓存和没缓存的区别。
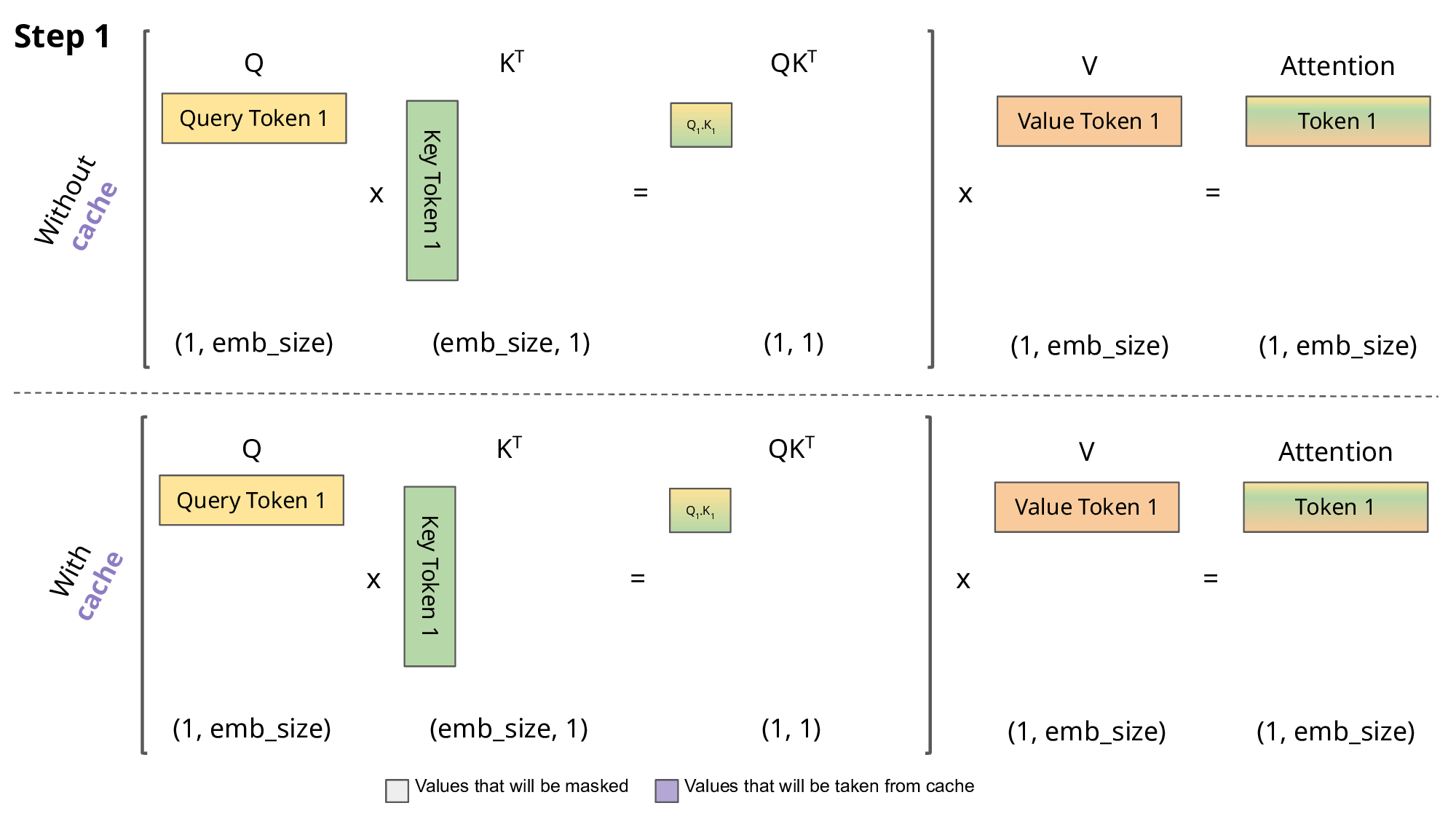
解码[token 1, token 2, token 3, token 4]时KV缓存的操作步骤。
实验表明,KV缓存的使用率在20.4%到38.2%之间。我自己用KV缓存的Qwenvl2.0跑了1万个图片的问题:“Describe the photo. Please answer short, under 20 words!” —— 最后速度提高了20%。
虽然这些机制一开始看上去很复杂,但只要设计得巧,是能变成优势的。下面我就把我从各方收集到的LLM推理优化心得,整理成了几个主题。
第一主题:聪明的KV缓存管理
页面注意力机制(Page attention)
KV缓存特别吃内存。上下文越长,KV缓存占的内存越多。比如说,有个LLM能接2048个token的输入,那它就得给2048个slot预留内存。看下面这张图:

图里是一个7个词的提示:“four, score, and, seven, years, ago, our.” 填满了2048个slot中的前7个。后面模型生成了4个词:“fathers, brought, forth, <eos>” —— 总共才用掉11个slot,剩下的2038个都空着。就这样,内存碎片就出来了。
每一步推理都要生成KV对,在用attention时把它缓存下来。KV缓存通常会被存在连续的内存块里,也就是“页面”。但一轮生成完了、内存释放之后,这些释放的页面很可能就不连续了。而下一轮推理要用的内存,可能又对不上现有的碎块,这就造成了“外部碎片”。
参考操作系统的内存管理思路,Page Attention机制把数据按逻辑块组织,用“页表”监控它们,然后映射到物理内存上。关键点如下:
- 固定大小块:PagedAttention会分配一些定长的小内存块(页)给KV缓存用。
- 块可共享:这些块可以在多个请求之间共享。
- 按需分配:推理过程中,块是边生成边分配的,不用一开始就按最大序列长度来预留。
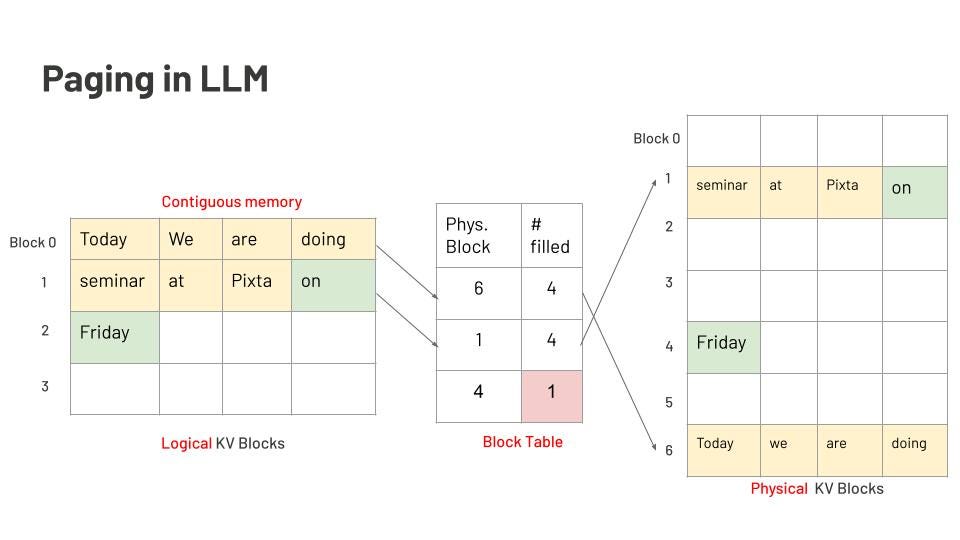
LLM中的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 22万+
22万+


 到【灌水乐园】发言
到【灌水乐园】发言








