



1.我们知道FullGC的触发条件大致情况有以下几种情况:
-
程序执行了System.gc() //建议jvm执行fullgc,并不一定会执行
-
执行了jmap-histo:live pid 命令 //这个会立即触发fullgc
-
在执行minorgc的时候进行的一系列检查
1.执行Minor GC的时候,JVM会检查老年代中最大连续可用空间是否大于了当前 新生代所有对象的总大小。
2.如果大于,则直接执行MinorGC(这个时候执行是没有风险的)。
3.如果小于了,JVM会检查是否开启了空间分配担保机制,如果没有开启则直接改 为执行Full GC。 如果开启了,则JVM会检查老年代中最大连续可用空间是否大于了历次晋升到老 年代中的平均大小,如果小于则执行改为执行FullGC。
4.如果大于则会执行MinorGC,如果MinorGC执行失败则会执行FullGC
5.使用了大对象 //大对象会直接进入老年代
6. 在程序中长期持有了对象的引用 //对象年龄达到指定阈值也会进入老年代 对于我们的情况,可以初步排除1,2两种情况,最有可能是4和5这两种情况。为了 进一步排查原因,我们在线上开启了-XX:+HeapDumpBeforeFullGC。
注意: JVM在执行dump操作的时候是会发生stoptheword事件的,也就是说此 时所有的用户线程都会暂停运行。 为了在此期间也能对外正常提供服务,建议采用分布式部署,并采用合适的负 载均衡算法
2. JVM参数的设置
线上这个dubbo服务是分布式部署,在其中一台机子上开启了
-
-XX:HeapDumpBeforeFullGC,总体 JVM参数如下:
-
-Xmx2g
-
-XX:+HeapDumpBeforeFullGC
-
-XX:HeapDumpPath=.-Xloggc:gc.log-XX:+PrintGC
-
-XX:+PrintGCDetails
-
-XX:+PrintGCDateStamps
-
-XX:+UseGCLogFileRotation
-
-XX:NumberOfGCLogFiles=10
-
-XX:GCLogFileSize=100m
-
-XX:HeapDumpOnOutOfMemoryError
3. Dump文件分析
dump下来的文件大约1.8g,用jvisualvm查看,发现用char[]类型的数据占用了41% 内存,同时另外一个com.alibaba.druid.stat.JdbcSqlStat 类型的数据占用了35%的内 存,也就是说整个堆中几乎全是这两类数据。如下图:

查看char[]类型数据,发现几乎全是sql语句

接下来查看char[]的引用情况:
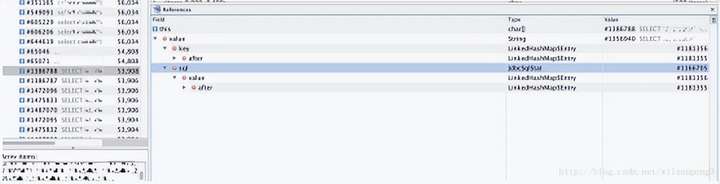
找到了JdbcSqlStat类,在代码中查看这个类的代码,关键代码如下:
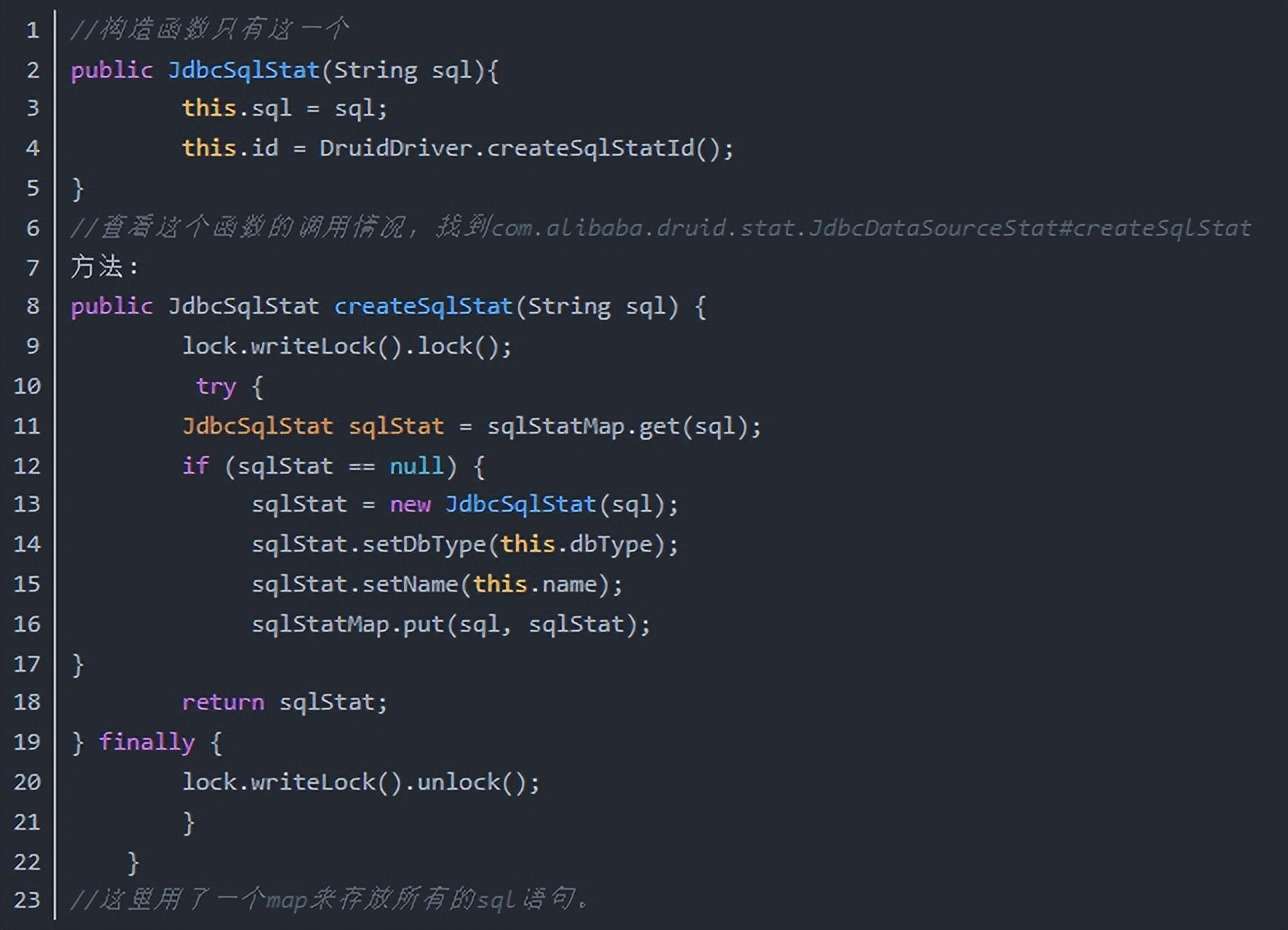
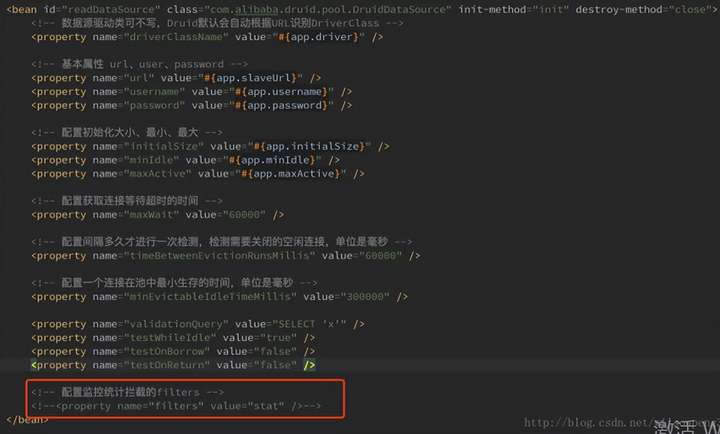
其实到这里也就知道什么原因造成了这个问题,因为我们使用的数据源是阿里巴巴的 druid,这个druid提供了一个sql语句监控功能,同时我们也开启了这个功能。只需 要在配置文件中把这个功能关掉应该就能消除这个问题,事实也的确如此,关掉这个功 能后到目前为止线上没再触发FullGC
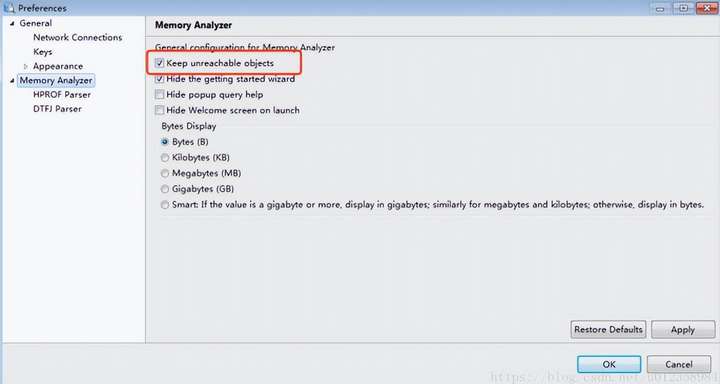
其他 如果用mat工具查看,建议把 “Keepunreachableobjects” 勾上,否则mat会把 堆中不可达的对象去除掉,这样我们的分析也许会变得没有意义。如下图: Window–>References 。另外jvisualvm 对ool 的支持不是很好,如果需要oql建议 使用mat。
粉丝福利
40+最新Java场景题已整理成册,需要的小伙伴点击文末小卡片即可:

近期或者明年有面试需求的小伙伴一定要拿回去在工作之外时间好好刷刷!!!
工作8小时的态度决定的是下限,空闲的8小时才决定上限。人活在世上,要吃饭,要追求物质,功利地讲,我们要做的只有一件事,超越别人就可以了。所以空闲8个小时就是你超越别人的最好的机会。别说上班一天很累,大家都累,你不更累一点,谈啥比别人强?
以上,共勉(手动抱拳)

















 2200
2200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









