




1、IO 的概念
- 输入 (Input):系统或设备接收的数据。例如,键盘输入的字符、网络接收的数据包,或磁盘读取的文件内容等。
- 输出 (Output):系统或设备输出的数据。例如,屏幕上显示的文本、网络发送的数据包,或写入磁盘的文件内容等
2、IO的示例
- 文件 IO:对文件的读写操作。
- 网络 IO:在网络连接中发送和接收数据。
- 设备 IO:对硬件设备(如硬盘、键盘、显示器等)进行的读写操作。
- 涉及计算机核心与其他设备间数据迁移的过程,就是IO。
3、IO常见问题
IO 操作可能受到硬件的物理限制,因而通常是系统性能的瓶颈之一
4、IO的作用范围
操作系统分为:
用户空间:用户访问的区域
+ 内核空间:操作系统访问的区域
进程(应用程序)在用户空间运行:
- 应用程序的 IO 请求:应用程序会向操作系统发起 IO 请求(例如,文件读取、网络请求等)。这些请求会通过系统调用进入内核空间。
- IO 在内核中执行:真正的 IO 操作(如磁盘读写、网络数据传输等)是在操作系统内核中进行的。操作系统负责将应用程序的请求转化为具体的硬件操作。IO 的过程本质上是在内核空间中执行的,而不是在用户空间。
- 用户空间的 IO:虽然应用程序自己不直接执行 IO 操作,但它通过调用操作系统提供的接口来发起 IO 请求。因此,可以说,用户空间并不直接进行 IO,而是通过操作系统来间接执行这些操作。
总结: 用户空间不存在IO,但是会发送IO请求给内核空间,然后就需要内核空间进行IO操作
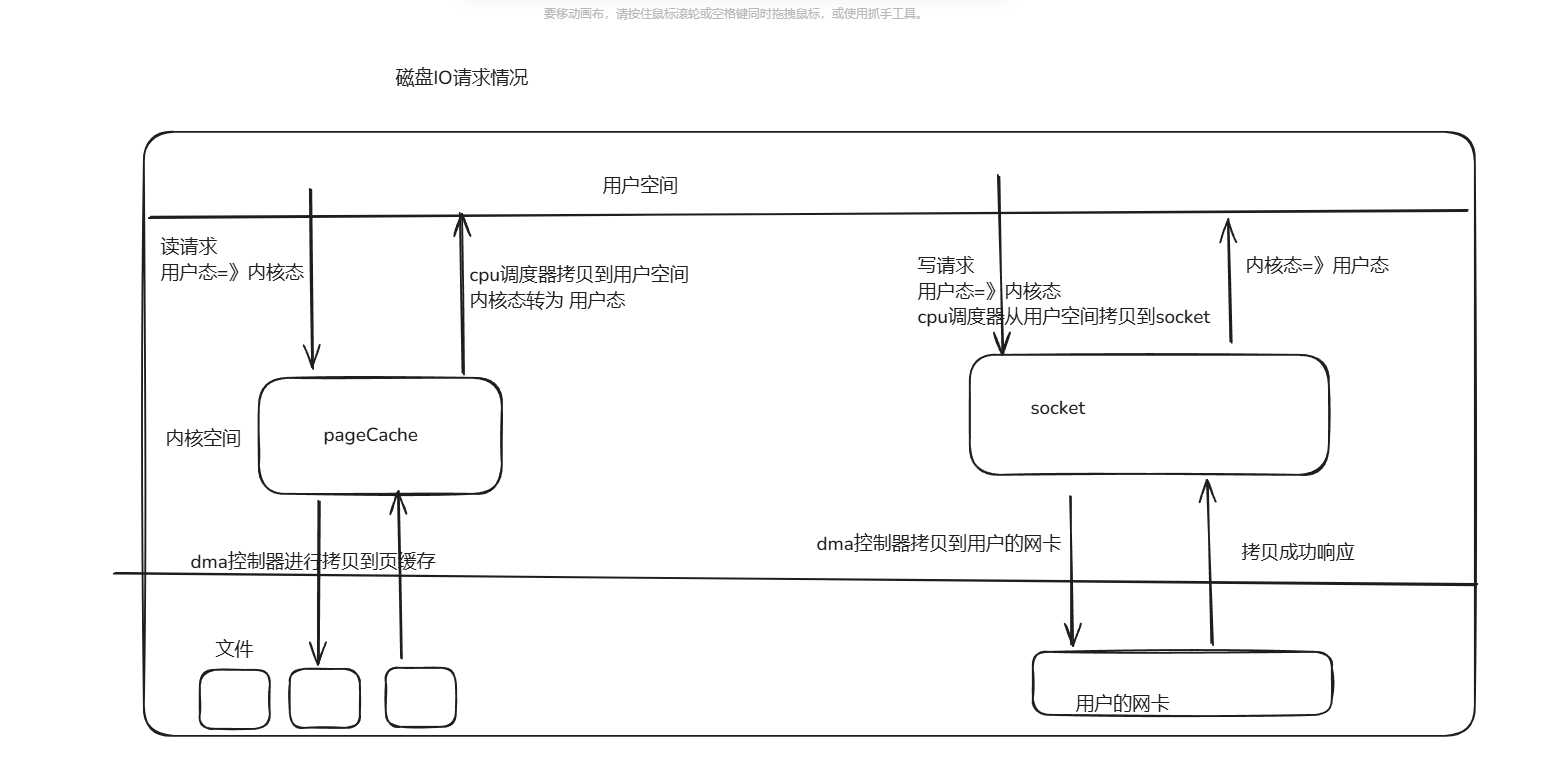
5、IO的几种情形
1、同步IO
概念:在此情况下,程序会等待 IO 操作完成后再继续执行。
实现方式:直接写代码即可
2、异步IO
概念:程序在发起 IO 请求后无需等待 IO 完成,可以继续执行其他任务。IO 完成后,系统会通知程序,或让程序在空闲时自行检查 IO 状态。这种方式提高了系统资源利用率和并发性能
实现方式:new thread() 实现runable接口 future接口的实现(异步编排)线程池 消息队列
3、阻塞IO
概念:在阻塞 IO 模式中,程序在发起 IO 操作后会被“阻塞”,即停止执行其他操作,直到 IO 操作完成。
常用于 IO很快的操作 或则 不在乎快速返回结果的操作
4、非阻塞IO
概念:在非阻塞 IO 模式中,程序发起 IO 操作后,不会等待 IO 操作完成,而是立即返回。程序可以继续执行其他任务,随时检查 IO 状态或等待系统通知 IO 操作的完成。
(所以常与轮询啊,事件通知等可以检测到IO操作是否完成的机制结和使用)
综合:
同步阻塞IO :直接使用 代码实现IO操作
同步非阻塞IO:创建一个监听器,监听io完成状态,执行完操作,等待io操作完成返回结果
异步阻塞IO:使用异步返回请求,但是异步线程的执行需要等IO完成后才能结束(线程池+io操作)
异步非阻塞IO:使用异步的操作,然后搞个监听器,监听管道的状态,然后一旦完成就回调我们的函数(nio包)
5、IO多路复用
IO 多路复用是一种高效的 IO 模型,允许一个线程同时监视多个 IO 操作。它的核心思想是让操作系统帮助检测哪些 IO 资源已经准备好进行读写,而不是让每个 IO 操作都单独等待。
常用的 IO 多路复用方法
select
select 是最早实现 IO 多路复用的系统调用,通过一个文件描述符集合来监控多个 IO 通道。
它的调用会阻塞进程,直到一个或多个文件描述符变为就绪(可读、可写或有异常发生),然后程序可以对就绪的文件描述符执行 IO 操作。
缺点在于文件描述符集合的大小有限,且需要遍历所有的文件描述符,性能较低。
select 是早期的 I/O 多路复用机制,它使用 一个固定大小的集合 来存储文件描述符。这个集合实际上是一个位图(bit map),每个文件描述符都对应一个位(bit),该位表示文件描述符的状态。
文件描述符的最大限制:select 要使用一个固定大小的数组来存储所有的文件描述符,最大容量由 FD_SETSIZE 限制,通常在 Linux 系统中,FD_SETSIZE 的默认值是 1024。也就是说,select 最多可以同时监视 1024 个文件描述符。这是因为在 select 中,文件描述符是通过一个固定大小的位图来表示的,每个文件描述符对应一个位。如果需要支持更多的文件描述符,就需要增加位图的大小,但在实际操作系统中,FD_SETSIZE 通常限制了这一点。
位图的限制:select 内部使用的位图通常是在栈上分配的内存,这限制了可以存储的文件描述符数量。如果文件描述符超过了 FD_SETSIZE,就无法处理更多的连接。
性能问题:当文件描述符的数量非常多时,select 需要在集合中逐个检查每个文件描述符,这样的操作是线性时间复杂度 (O(n)) 的,导致了性能的瓶颈。尤其是当连接数非常大时,性能会急剧下降。
poll
poll 是 select 的改进版,没有文件描述符数量限制,解决了 select 的一些不足。
poll 通过一个数组而非集合来管理文件描述符,但仍然需要轮询所有文件描述符,且每次调用都需要重新构建文件描述符数组。
随着文件描述符数量增加,poll 的性能会下降。
数组可以扩容,只受内存资源的影响
epoll
epoll 是 Linux 下的高效 IO 多路复用方式,针对 select 和 poll 的性能问题进行了优化。
epoll 的文件描述符不需要重复传递,且支持“边缘触发(edge-triggered)”和“水平触发(level-triggered)”两种模式,能够更高效地检测文件描述符的状态变化。
它适合处理大量并发连接,被广泛用于高并发服务器(如 Nginx、Redis)中。
redis的多路IO复用
假设有一个客户端连接到 Redis 并发送请求:
- 客户端连接建立:Redis 启动并进入事件循环,监听端口,等待客户端连接。
- 客户端发送请求:客户端发送一个请求(比如 SET key value)。
- 事件循环检测到 I/O 事件:Redis 的事件循环使用 I/O 复用机制(例如 epoll)监听网络套接字的变化,当发现客户端有请求数据时,触发 read() 操作。
- 回调处理请求:读取到客户端的请求数据后,Redis 将请求交给回调函数进行解析和处理(例如 SET 命令的处理)。
- 生成响应并发送给客户端:完成命令处理后,Redis 将响应数据通过网络写回客户端。
- 事件循环继续:事件循环继续等待新的 I/O 事件,直到下一个请求到达。
6、事件驱动模型
概念:事件驱动模型通过将 I/O 操作和程序的逻辑解耦,允许程序在等待 I/O 操作时继续执行其他任务,而不必阻塞或轮询每个 I/O 操作。
实现流程:非阻塞 I/O 操作:程序发起一个 I/O 请求(例如读取文件或从网络获取数据),但不阻塞等待 I/O 完成。该操作会立即返回,而不是停下来等待数据。
注册事件和回调函数:程序将感兴趣的事件(如数据可读、连接建立、数据可写等)和相应的回调函数注册到事件驱动框架中。回调函数会在事件发生时被调用。
事件循环:事件循环会持续检查是否有 I/O 事件发生。一旦事件发生,事件循环会触发相关的回调函数,处理 I/O 结果。
回调函数执行:当 I/O 事件准备就绪时(如网络数据到达、文件准备就绪等),事件驱动框架会调用之前注册的回调函数。回调函数通常是处理事件的逻辑,如读取数据、处理请求、发送响应等。
继续执行其他任务:事件循环不会因为等待某个 I/O 操作的完成而阻塞,程序可以继续执行其他任务,直到某个 I/O 事件触发回调函数。
实现网络通信的架构方式:
1、线程架构模式:一个io一个线程
2、事件驱动模式:reactor堆反应模式
1、一个线程:io 和cpu 调度都有这个线程执行 最经典的实现场景 redis中的多路io复用
2、一个线程+线程池:
3、多个reator线程+线程池:
实现io通信的模式
1、Bio
同步阻塞IO
2、Nio
取决于IO的操作是同步或则异步,同步就需要轮询得到IO结果,同步非阻塞IO,异步就异步非阻塞IO
3、Aio
完全异步的操作,由内核线程或自定义线程池实现异步,事件回调的方式实现IO
实现多路复用的机制
1、Select
遍历所有文件,将需要IO的文件存入固定值大小的集合(1024)位图思想
2、Poll
遍历所有文件,将需要IO的文件存入动态数组
3、Epoll
由内核实现,需要IO请求实现事件驱动机制,不再是遍历获取

















 4428
4428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









