







一、前言
因运维过程中,经常会借助于很多工具来实现我们的监控、备份、校验,安全测试,批量操作,可视化辅助,集中管理等,甚至AI相关,本文特对常用工具进行梳理记录,以备不时之需及后来者参考应用,欢迎留言补充和建议。
二、文件管理或备份工具
2.1、Rclone
它是一款免费的云存储管理工具,Rclone是一个采用 Go 语言开发的命令行程序,具有与unix命令rsync、cp、mv、mount、ls、ncdu、tree、rm和cat相当的强大功能,主用于管理云存储上的文件,超过70种云存储产品支持rclone,包括S3对象存储、商业的文件存储服务以及标准传输协议(支持复制,同步,移动,删除文件。它还支持文件加密和压缩,支持分块上传和分块下载,可以暂停和恢复传输,支持文件的校验和合并。),它允许在文件系统和云存储服务之间或在多个云存储服务之间访问和同步文件,它具有单向同步功能,使目录完全相同,它具有加密、缓存和联合后端,支持 Fuse 安装,并且可以通过 HTTP、WebDAV、FTP、SFTP 或 DLNA 服务本地或远程文件。它可以用来做很多事情,包括备份,文件同步,数据迁移等,它可以在各种平台上运行,包括 Windows,macOS,Linux,FreeBSD,NetBSD 等。在云存储场景,我们能够像使用本地文件一样便捷的使用云存储,它也被誉为“云存储界的瑞士军刀”。我们可以使用Rclone工具,对移动云对象存储EOS进行数据导入、数据同步、迁移备份或者挂载等操作。

注:rclone sync 只支持本地向远程无条件的同步,远程的永远会被覆盖;
相关资源:官网、rclone GitHub、rclone Gitee、软件下载
1)配置说明
默认配置完成的后配置文件都保存在:/root/.config/rclone/rclone.conf 目录下:
#查看默认配置文件位置
rclone config paths
# 编辑配置,配置对象存储EOS数据源
[EOS] #配置项名称,用户自定义
type = s3
provider = ChinaMobile
access_key_id = XXXXXXXX
secret_access_key = XXXXXXXXXXXXXXXX
endpoint = XXXXXXXX.cmecloud.cn #对象存储服务接口地址,一般endpoint地址设置的是内网地址,注意对应资源池是否支持https,否者使用http
location_constraint = XXXXXXXX #需与接口一致,仅在创建桶时使用,如无需创建桶,可不设置
acl = private #默认值:private,可选值: private、public-read、public-read-write、authenticated-read
#向导配置
rclone config --config [config-file-path] #初始如下
No remotes found - make a new one
n) New remote
s) Set configuration password
q) Quit config
n/s/q> n
#列举桶内的对象
rclone ls [config-name]:[bucket-name] --config [config-file-path]
2)部署安装
curl -O https://downloads.rclone.org/rclone-current-linux-amd64.rpm
curl -O https://downloads.rclone.org/rclone-current-linux-amd64.zip
#或直接
curl https://rclone.org/install.sh | sudo bash
sudo unzip rclone-current-linux-amd64.zip
sudo cp rclone /usr/bin/
sudo chown root:root /usr/bin/rclone
sudo chmod 755 /usr/bin/rclone
rclone version
#生产配置文件,默认路径为:/root/.config/rclone/rclone.conf
rclone config --config /etc/.config/rclone/rclone.conf
vim /etc/.config/rclone/rclone.conf #修改如下内容
[source-region]
type = s3 #移动云对象存储 EOS、阿里云 OSS、腾讯云 COS 均为 s3
provider = Alibaba #移动云对象存储为 ChinaMobile,阿里云为 Alibaba,腾讯云为 TencentCOS
access_key_id = XXXXXXXX
secret_access_key = XXXXXXXX
endpoint = oss-xxx.aliyuncs.com #cos.xxx.myqcloud.com
[target-region]
type = s3
provider = ChinaMobile
access_key_id = XXXXXXXX
secret_access_key = XXXXXXXX
endpoint = eos-xxx.cmecloud.cn
#数据迁移同步
#命令格式:rclone copy 源名称(配置文件内的名称):源数据桶 目标名称:目标桶
# source-region 复制到 target-region
#其中,copy 指令与 sync 指令在多数场景下迁移效果是一样的,唯一的区别是 copy 指令不会删除目的桶中的对象。如果期望迁移前后数据完全一致,建议使用 sync 指令;--checkers N,表示同时有 N 个 checker 并发执行。在迁移/同步的过程中,checker 用于比较源端和目的端的对象是否相同,默认值为 8。--transfers N,表示同时有 N 个 transfer 并发执行。在迁移/同步的过程中,transfer 用于实际的对象传输,默认值为 4。--retries N,表示如果操作失败,重试 N 次,默认值为 3。--checksum,携带此参数时,checker 通过对象的哈希值和大小来判断两个对象是否相同。不携带不会报错。--fast-list,携带此参数时,迁移工具会尝试一次性地读取所有的对象信息并索引到内存中,此时对象数据会处理的更快, 代价是使用更多的内存。实际使用中,对于以桶为单位的迁移任务,可以按照桶中每个对象占用 1k 内存进行粗略估计,如果估算值不超过物理内存,建议携带此参数。
#其他:--s3-upload-cutoff,对象大于这个值时会使用分块上传。默认值是 200Mi,最大值是 5GiB,最小值是 0 表示永远使用分块上传。--s3-chunk-size,在对象大小大于 s3-upload-cutoff 时,使用分块上传,这个值用来指定分块大小。默认值是 5Mi。
#如果需要对迁移任务中间状态、带宽使用等进行管控,或者调试命令
#--dry-run,执行一次尝试性的操作;该操作不会产生实际的影响;
#--progress,携带此参数时,在迁移过程中会在终端上打印传输的实时概况,每 500ms 刷新一次;可以用于追踪迁移/同步进度
#--bwlimit,此参数用来控制迁移服务的带宽使用。上行和下行的带宽可以一起控制,比如:--bwlimit 10M 表示限制上下行带宽为 10 MiByte/s;也可以对上行和下行的带宽分开控制,比如:--bwlimit 10M:100k,表示限制上行带宽为 10 MiByte/s,下行带宽为100 KiByte/s。也可以使用off表示不限制带宽,比如:--bwlimit 10M:off,表示只限制上行带宽为 10 MiByte/s
rclone copy source-region:bucketName target-region:bucketName --progress --checksum --fast-list --checkers 32 --transfers 16 --retries 5 --config /etc/.config/rclone/rclone.conf --log-file /etc/.config/rclone/eos.log
3)常用命令
rclone config - 以控制会话的形式添加rclone的配置,配置保存在rclone.conf文件中。
rclone copy - 将文件从源复制到目的地址,默认跳过已复制完成的。
rclone sync - 将源数据同步到目的地址,只更新目的地址的数据。可添加–dry-run标志来检查要复制、删除的数据
rclone move - 将源数据移动到目的地址。
rclone delete - 删除指定路径下的文件内容。
rclone purge - 清空指定路径下所有文件数据。
rclone mkdir - 创建一个新目录。
rclone rmdir - 删除空目录。
rclone check - 检查源和目的地址数据是否匹配。
rclone ls - 列出指定路径下所有的文件以及文件大小和路径。
rclone lsd - 列出指定路径下所有的目录/容器/桶。
rclone lsl - 列出指定路径下所有文件以及修改时间、文件大小和路径。
rclone md5sum - 为指定路径下的所有文件产生一个md5sum文件。
rclone sha1sum - 为指定路径下的所有文件产生一个sha1sum文件。
rclone size - 获取指定路径下,文件内容的总大小。
rclone version - 查看当前版本。
rclone cleanup - 清空remote。
rclone dedupe - 交互式查找重复文件,进行删除/重命名操作。
rclone mount - 挂载云盘为本地硬盘
fusermount -qzu LocalFolder - 卸载挂载的云盘
### 同步本地目录或文件到远端bucket
rclone sync <LOCAL_PATH> romote:bucket-name/target-path/
# 同步远端bucket目录到本地
rclone sync romote:bucket-name/target-path/ <LOCAL_PATH>
#两个桶之间数据同步
rclone sync source:bucket-name target:bucket-name
# 将本地文件同步到远端,并备份过程中被删除或修改的文件到备份存储桶中,加 --progress 显示迁移的进度及校验的结果
rclone sync <LOCAL_PATH> romote:bucket-name --backup-dir romote:backup-bucket-name/backup-dir
# 数据校验:-P = --progress可显示实时传输进度,500 ms刷新一次,否则默认1分钟刷新一次
rclone check source:bucket-name/source-path/ target:bucket-name/target-path/ -P
rclone命令常用参数:
| 参数 | 说明 |
|---|---|
| -n = --dry-run | 测试运行,查看 rclone 在实际运行中会进行哪些操作 |
| -P = --progress | 显示实时传输进度,500 ms刷新一次,否则默认1分钟刷新一次 |
| –cache-chunk-size 5M | 块的大小,默认 5M 越大上传越快,占用内存越多,太大可能会导致进程中断 |
| –onedrive-chunk-size 100M | 提高 OneDrive 上传速度适用于G口宽带服务器 |
| –drive-chunk-size 64M | 提高 Google Drive 上传速度适用于G口宽带服务器 |
| –cache-chunk-total-size SizeSuffix | 块可以在本地磁盘上占用的总大小 |
| –transfers=N | 并行文件数,默认为4。在比较小的内存的VPS上建议调小这个参数,比如 128M 的小鸡上使用建议设置为1。 |
| –config string | 指定配置文件路径,string为配置文件路径 |
| –ignore-errors | 跳过错误 |
| –size-only | 根据文件大小校验,不校验hash |
| –drive-server-side-across-configs | 服务端对服务端传输 |
| –exclude-from | 排除文件或目录列表来自某个文件指定 |
| –include-from | 包含文件或目录来自某个文件指定 |
| –filter-from | 文件过滤规则来自某个文件指定 |
| –exclude | 排除文件或目录;–exclude “{Video,Software}/” 排除所有目录下的 Video 和 Software 目录 |
| –include | 包含文件或目录 |
| –filter | 文件过滤规则,相当于上面两个选项的其它使用方式。包含规则以+开头,排除规则以-开头;–filter "+ *.{png,jpg}"等同于–include “*.{png,jpg}” |
| –min-size num | 过滤小于指定大小的文件。比如 --min-size 50 表示不会传输小于 50k 的文件。 |
| –max-size num | 过滤大于指定大小的文件。比如 --max-size 1G 表示不会传输大于 1G 的文件。 |
| -q | -rclone将仅生成 ERROR 消息。 |
| -v | rclone将生成 ERROR,NOTICE 和 INFO 消息,推荐此项。 |
| -vv | -rclone 将生成 ERROR,NOTICE,INFO和 DEBUG 消息。 |
| –log-level LEVEL | 标志控制日志级别 |
4)应用场景
案例1:对象存储间(多云之间)数据源迁移
使用rclone将第三方数据源,如:阿里云 OSS、腾讯云 COS、AWS S3 等数据迁移至移动云对象存储 EOS,注一,在线迁移服务并不会对源端数据执行解冻操作,对于归档类型的数据,需要先进行解冻操作,待解冻完成后再创建迁移任务。
1、总对象数少于 1000w 的桶迁移
#使用 rclone copy 将源数据桶信息复制至目标桶下
rclone copy source-region:bucketName target-region:bucketName -P -v --checksum --update --checkers 32 --transfers 16 --retries 5 --config ./rclone.conf --log-file ./eos.log
#或
#使用 rclone move 将源数据桶信息移动至目标桶(同时也对源数据桶数据进行删除),但源数据桶的目录结构需要后续手动删除
rclone move source-region:bucketName target-region:bucketName -P -v --checksum --update --checkers 32 --transfers 16 --retries 5 --config ./rclone.conf --log-file ./eos.log
2、总对象数大于 1000w 的桶迁移
注:总对象数大于 1000w 的桶,需要先梳理出桶内目录文件,有目录且文件分布比较均匀的可以按照目录分任务进行迁移,否则的需要您先导出该桶的文件列表,然后按照文件列表进行迁移。 导出文件列表可以使用桶清单功能或使用 SDK 列举文件功能。
#按照目录进行迁移
rclone copy source-region:bucketName/目录名/ target-region:bucketName/目录名/ -P -v --checksum --update --checkers 32 --transfers 16 --retries 5 --config ./rclone.conf --log-file ./eos.log
#按照文件名进行迁移;--files-from ./object.txt 表示仅迁移/同步文件列表 object.txt 中的所有文件,object.txt 的格式为每个源文件全称占用一行;当待迁移的文件数量较多时,可对导出的文件列表进行拆分,同时使用多台服务器同时迁移来提高迁移速度;分块上传的对象不能保证迁移后分块大小与原对象一致(Rclone 默认分块大小为 128Mi);软链接按文件迁移时会当成正常对象被迁移过去
#注意:追加对象在迁移后会变成普通对象,如果源对象一直在追加写,迁移后的目标资源池下该对象为迁移时刻该文件内容;
rclone copy source-region:bucketName target-region:bucketName -P -v --checksum --update --checkers 32 --transfers 16 --retries 5 --files-from ./object.txt --config ./rclone.conf --log-file ./eos.log
#查看迁移日志验证
tail -f ./eos.log #或迁移过程中使用--progress参数
#增量迁移
rclone copy source-region:bucketName target-region:bucketName -P -v --checksum --update --checkers 32 --transfers 16 --retries 5 --config ./rclone.conf --log-file ./eos.log
2.2、Restic
Restic 是一款 GO 语言开发的开源免费快速、高效、安全的跨平台备份工具。Restic 使用AES-256加密技术来保证我们的数据安全性和完整性,可以将本地数据加密后传输到指定的存储。Restic 支持增量备份,还可利用重复数据删除来节省宝贵的存储空间。Restic 目前可与大多数主要的云提供商兼容,支持常见操作系统(Linux、macOS、Windows、FreeBSD、OpenBSD)。Restic备份时,默认它通常必须扫描每个文件的全部内容,会进行下载比较如果文件较大会产生的代价非常昂贵,因此restic还使用基于文件元数据的更改检测规则来确定文件是否可能自上次备份以来未发生更改。如果是,则不会再次扫描该文件。仅对常规文件(而不是特殊文件、符号链接或目录)执行更改检测,这些文件的路径与同一位置的先前备份中的路径完全相同。如果文件或其包含目录之一被重命名,则会将其视为其他文件,并且将再次扫描其全部内容。

关联资源:restic GitHub、文档、软件下载、restic设计原理
Restic优势:
Restic 每次备份都会生成一个快照,记录当前时间点的文件结构,因此可以找回特定时间点的文件。通常可以实现在不清理快照时同一个文件的版本记录。
Restic 配置信息直接写在仓库,只要有仓库密码,在任何安装了Restic的计算机上都可以操作仓库。
Restic 面向的是文件备份和加密,文件先加密再传输备份,而且是增量备份,即每次只备份变化的部分。
Restic 可以备份数据到不同的类型的数据仓库如本地存储、SFTP、Minio等。
Restic 支持多种操作系统。
Restic 备份与恢复操作相对简单。
Restic 可实现备份验证,因此restic让我们轻松验证所有数据是否可以恢复。
Restic 可实现备份数据加密,假设存储备份数据的位置不是受信任的环境(例如,系统管理员等其他人能够访问您的备份的共享空间)。
Restic 备份时可实现重复文件的去重以达到节省备份空间的目的
1)部署安装
#YUM
yum install yum-plugin-copr -y #或apt-get install restic
yum enable copart/restic -y #copr enable启用 Copr 存储库,该存储库包含 Restic 备份工具的最新版本
yum install restic -y
#二进制包方式
bzip2 -d restic_0.13.1_linux_amd64.bz2
#添加执行权限
chmod +x restic_0.13.1_linux_amd64
#拷贝到PATH路径
mv restic_0.13.1_linux_amd64 /usr/bin/restic
## REST存储库创建,用于通过HTTP或HTTPS协议将数据备份到远程服务
git clone https://github.com/restic/rest-server
tar xf rest-server_0.11.0_linux_amd64.tar.gz
mv rest-server_0.11.0_linux_amd64 /usr/local/rest-server
#生成认证文件
htpasswd -B -c .htpasswd zhangzhuo
mv htpasswd /data1/rest-server/.htpasswd
#创建数据目录
mkdir /data1/rest-server -p
#创建服务启动文件
cat /etc/systemd/system/rest-server.service
[Unit]
Description=rest-server
Wants=network-noline.target
After=network-noline.target
[Service]
WorkingDirectory=/data1/rest-server
ExecStart=/usr/local/rest-server/rest-server --path /data1/rest-server
Restart=always
[Install]
WantedBy=multi-user.target
#启动设置开机自启
systemctl enable --now rest-server.service
#访问测试,端口默认8000
$ curl 127.0.0.1:8000
#初始化
restic -r rest:http://bcadmin:passwd@172.18.1.101:8000/ init
#验证
restic version
2)使用
#创建一个备份仓库,即在本地文件系统初始化新建一个存储库,如桶中已存在文件,可能会导致仓库初始化失败或者原有文件丢失,建议创建新桶用于备份;注意:密码丢失会导致文件无法访问和找回
restic init --repo /data1/backup #--repo: 指定本地文件系统目录;输出
enter password for new repository:
enter password again:
created restic repository a6801fab57 at ./backup
Please note that knowledge of your password is required to access
the repository. Losing your password means that your data is
irrecoverably lost.
#可将密码配置到环境变量
export RESTIC_PASSWORD=123456
#创建快照,restic多次备份是依据主机名称与备份目标目录名称区别是否备份的是之前备份过的,-r:指定备份存储库的位置;创建备份时会遵循默认检测规则,但如果见改变,可使用如下参数:
# --force:关闭更改检测并重新扫描所有文件
# --ignore-ctime:需要 mtime 才能匹配,但允许 ctime 不同
# --ignore-inode:需要 mtime 才能匹配,但允许 inode 编号和 ctime 不同
restic -r [存储库] --verbose backup [备份目录]
#验证备份结果:输出“no errors were found”时,表示备份成功;也可通过退出状态代码来验证,说明如下:
# 备份成功时为 0(创建所有源文件的快照)
# 1 出现致命错误时(未创建快照)
# 3 当某些源文件无法读取时(不完整的快照,其余文件已创建)
restic check
echo $?
#查看备份库中的所有备份快照
restic -r /data1/backup snapshots
restic -r s3:http://ip/restic snapshots --password-file pass #或指定密码文件
restic -r /data1/backup ls <snapshot-id> #查看指定快照的文件列表
#排除文件
restic -r s3:http://ip/restic backup /etc --exclude="*.c" --exclude-file=excludes.txt
#指定备份文件列表来备份:当想要从许多不同的位置备份文件时,或者当使用其他一些软件来生成要备份的文件列表时,很有用
restic -r s3:http://ip/restic backup --files-from back_list
#快照比较: diff 子命令,它能显示两个快照之间的差异并显示一个小的统计信息,只需传递两个快照 ID
restic -r s3:http://ip/restic diff 7629554a 29328031
#定期检查源和备份呢存储库是否正常且一致
# 结构一致性和完整性,例如快照、树和包文件(默认)restic -r [存储库] check
# 备份的实际数据的完整性restic -r [存储库] check --read-data
restic -r s3:http://ip/restic check
restic -r s3:http://ip/restic check --read-data #过程中需下载存储库中的所有包文件,会导致流量和带宽耗费
#使用快照还原
# 语法:restic -r [存储库] restore [快照id] --target [恢复到哪里]
# 恢复时可以使用dump将整个文件夹结构的内容输出到标准输出,Restic 将以 tar(默认)或 zip 格式输出内容;也可使用--exclude和--include过滤,只恢复单个文件
restic -r [存储库] dump -a zip [快照id] [快照备份路径] > [压缩包名称].zip
restic -r /data1/backup restore snapshot_ID --target /opt/restore
#恢复单个文件:/opt/etc/fstab
restic -r s3:http://ip/restic restore ff00e6a6 --target /tmp/restore --include /opt/etc/fstab
#备份文件目录结构导出到压缩包
restic -r s3:http://ip/restic dump -a zip ff00e6a6 /opt/etc > restore.zip
#删除快照
# forget删除快照
# prune删除仅由已删除快照引用的剩余数据
restic -r s3:http://ip/restic forget 95a8af65 #快照删除后此快照中的文件引用的数据仍存储在存储库中
restic -r s3:http://ip/restic prune #清理上述命令清理快照后遗留未引用的数据
restic -r s3:http://ip/restic forget 95a8af65 --prune
#保留同一个主机同一个备份目标的最新3个快照其余全部删除
restic -r s3:http://ip/restic forget --keep-last 3 --prune
3)术语
- 存储库(Repository):备份过程中生成的所有数据都以结构化形式发送并存储在存储库中,例如:存储在文件系统中,文件系统中可以创建多级目录。
\- Blob: Blob是将数据与识别信息(如数据的 SHA-256 哈希值及其长度)组合在一起。
\- 包(Pack): 一个Pack将多个Blobs进行组合,例如在一个文件中
\- 快照(Snapshot): 一个快照是文件和目录在某个备份时间点的状态。状态的含义是内容以及元数据(metadata)信息,如:文件或目录及其内容的名称、修改时间(mtime),元数据(ctime)。
\- 存储ID(Storage ID):存储ID是存储库中存放内容的SHA-256。只有得到此ID才能从存储库中加载文件。
4)命令参数
–dry-run 模拟运行,仅比较文件,不做实际的上传
–exclude pattern 排除匹配 pattern 的文件,可设置多个
–exclude-file file 根据文件 file 中的 pattern 排除文件
–exclude-larger-than size 排除尺寸超过指定 size 的文件
–host host 指定备份的 host
–iexclude pattern 排除匹配 pattern 的文件,忽略大小写,可设置多个
–iexclude-file file 根据文件 file 中的 pattern 排除文件,忽略大小写
–ignore-ctime 比较文件时,允许创建时间不一致 Windows 系统不支持
–ignore-inode 比较文件时,允许创建时间和 inode number 不一致 Windows 系统不支持
–tag tags 指定备份的 tags
–group-by group 分组显示查询结果 group 的值域:host, paths, tags
–host host 查询指定 host 的快照
–latest n 查询最近的 n 条快照
–path path 查询指定 path 的快照
–tag tags 查询指定 tag 的快照
–exclude pattern 排除匹配 pattern 的文件,可设置多个
–iexclude pattern 排除匹配 pattern 的文件,忽略大小写,可设置多个
–include pattern 还原匹配 pattern 的文件,可设置多个
–iinclude pattern 还原匹配 pattern 的文件,忽略大小写,可设置多个
–path path 还原指定 path 的快照
–host host 还原指定 host 的快照
–tag tags 还原指定 tags 的快照
–target path 指定还原路径
–keep-last n:保留n最后(最近的)快照。
–keep-hourly n对于有一个或多个快照的最后n几个小时,每个小时只保留最近的一个。
–keep-daily n对于有一个或多个快照的最后n几天,每天只保留最近的一个。
–keep-weekly n对于有一个或多个快照的最后n几周,每周只保留最近的一个。
–keep-monthly n对于有一个或多个快照的最后n几个月,每个月只保留最近的一个。
–keep-yearly n对于有一个或多个快照的最后n几年,每年只保留最近的一个。
–keep-tag保留具有此选项指定的所有标签的所有快照(可以指定多次)。
–keep-within duration将所有具有时间戳的快照保留在最新快照的指定持续时间内,其中duration是年数、月数、天数和小时数。例如2y5m7d3h,将保留在最近(最近)快照之前两年、五个月、7 天和三个小时内制作的所有快照。
–keep-within-hourly duration保留在最新快照的指定持续时间内制作的所有每小时快照。的duration指定方式与 for 相同–keep-within,确定每小时快照的方法与 for 相同–keep-hourly。
–keep-within-daily duration保留在最新快照的指定持续时间内制作的所有每日快照。
–keep-within-weekly duration保留在最新快照的指定持续时间内制作的所有每周快照。
–keep-within-monthly duration保留在最新快照的指定持续时间内制作的所有月度快照。
–keep-within-yearly duration保留在最新快照的指定持续时间内制作的所有年度快照
删除快照:高危操作,请谨慎操作
-l n 只保留最近 n 次快照
-H n 最近 n 小时内,只保留每小时最新的快照
-d n 最近 n 天内,只保留每天最新的快照
-w n 最近 n 周内,只保留每周最新的快照
-m n 最近 n 个月内,只保留每月最新的快照
-y n 最近 n 年内,只保留每年最新的快照
–keep-within duration 只保留最近 duration 内的快照 duration 样例:1y5m7d2h
–keep-within-hourly duration 最近 duration 内,只保留每小时最新的快照 duration 样例:1y5m7d2h
–keep-within-daily duration 最近 duration 内,只保留每天最新的快照 duration 样例:1y5m7d2h
–keep-within-weekly duration 最近 duration 内,只保留每周最新的快照 duration 样例:1y5m7d2h
–keep-within-monthly duration 最近 duration 内,只保留每月最新的快照 duration 样例:1y5m7d2h
–keep-within-yearly duration 最近 duration 内,只保留每年最新的快照 duration 样例:1y5m7d2h
–keep-tag tag 保留指定 tag 的快照,可设置多个
–host host 指定 host
–tag tag 指定 tag
–path path 指定 path
–dry-run 模拟运行,不做实际的删除
–prune 删除快照的同时也删除数据
2.3、Rsync远程复制(备份)和增量迁移工具

Rsync(Remote Sync,远程同步)是一个快速且非常通用的文件复制工具。它可以用来本地不同磁盘/位置进行文件复制,也可通过任何远程shell与另一台主机交互来进行文件复制,或与远程rsync守护进程进行复制。Rsync提供了大量参数选项,用以控制其行为的各个方面,并允许对要复制的文件集进行非常灵活的规范化批量配置。它以其**增量传输算法**而闻名,该算法通过仅发送源文件和目标中现有文件之间的差异来减少通过网络发送的数据量。Rsync广泛用于备份和镜像并作为日常使用的高效复制工具。
1)Rsync增量传输
rsync默认使用“quic check”算法,它会比较源文件和目标文件(如果存在)的文件大小和修改时间mtime,如果两端文件的大小或mtime不同,则发送端会传输该文件,否则将忽略该文件。
如果“quick check”算法决定了要传输文件A,它不会传输整个文件A,而是只传源文件A和目标文件A所不同的部分,即增量传输。也就是,rsync的增量传输可做到:文件级的增量传输和数据块级别的增量传输(只传输两文件所不同的那一部分数据);更多参见 how-rsync-works。
- remote shell:指Rsync客户端和远程系统中Rsync服务器之间连接的一个或多个进程。
- generator进程:生成器进程用来识别更改的文件并管理文件级逻辑
- Rsync协议:采用字节流形式传输所有内容,不像传统传输协议那样都已经定义了良好的数据包形式发送,比如数据包中有一个报头和一个可选的正文或数据有效载荷;且在每个数据包的报头中都指定一个类型和/或命令,每个数据包也都有固定的长度;此外,还可能定义些不同程度的状态性、数据包间独立性、友好可读性以及重建断开连接会话等;Rsync协议中除了不匹配的文件数据外,没有长度说明符或计数。相反,每个字节的含义则取决于协议级别定义的上下文。
- 文件列表:文件列表不仅包括路径名,还包括所有权、模式、权限、大小和modtime。如果指定了–checksum选项,则它还包括文件校验和。rsync启动完成后的第一件事就是发送方将创建文件列表。
2)工作原理
当我们发起rsync连接远程主机时,这时会在远程主机fork出一个rsync服务端,即远程shell,client和这个server通过remote shell的管道进行通信,就 rsync而言并不算真正网络联通;本地Rsync 连接也是通过管道进行通信的;另一种情况是,当Rsync是与远程主机的rsysnc daemon守护进程通信时,它是直接通过网络套接字通信的,不再是管道连接了;这是唯一 一种可以称为网络感知的Rsync通信;在此模式下,必须通过套接字发送rsync选项(options)。在客户端和服务器之间的通信开始时,它们各自向另一方发送它们支持的最大协议版本。然后,每一方都使用最小值作为传输的协议级别。Rsync是高度流水线化(高度依赖管道)的。这意味着它基本是一组以单向方式进行通信的进程,它也只受管道失速,磁盘IO和cpu的影响;生成器进程会将文件列表与目标本地目录树进行比较,为了实现数据的远程匹配,生成器进程会为基础文件创建块校验和,并按照文件索引号立即发送给发送方,块校验和的大小是根据每个文件的大小计算的,然后发送方进程会从生成器中一次读取文件索引号和相关块校验和集,对于生成器发送的每个文件id,该进程都会存储块校验和,并为它们构建一个哈希索引,以便快速查找。然后读取本地文件,并为从本地文件的第一个字节开始的块生成校验和。在生成器发送的集合中查找此块校验和,如果找不到匹配,则将不匹配的字节附加到不匹配的数据上,并从下一个字节开始的块继续,这就是所谓的“滚动校验和”。通过接收器文件中匹配块的偏移量和长度,如发现块校验和匹配,则将其视为匹配块,而任何累积的不匹配数据都将被发送到接收器,块校验和生成器将继续到匹配块后的下一个字节生成。发送方将向接收方发出如何将源文件重建为新的目标文件的指令。在每个文件处理结束时,发送一个完整的文件校验和,发送方继续处理下一个文件。接收方将从发送方读取由文件索引号标识的每个文件的数据。它将打开本地文件(称为基础)并创建一个临时文件。
三、容器管理
3.1、 Watchtower(瞭望塔)工具
背景:当我们是通过docker hub上拉取镜像进行容器创建时,当docker hub上镜像版本更新后,本地容器兵不会自动升级镜像版本,依然保持在旧版本,如果我们想要升级只能重新拉取最新的latest版本,然后重新部署容器,这比较麻烦,这是我们就可利用Watchtower工具来完成。

Watchtower 是一个开源项目,它监视正在运行的容器以及相关的镜像,当检测到 registry 中的镜像与本地的镜像有差异时,它会拉取最新镜像优雅地关闭现有容器并使用最初部署时相同的参数重新启动相应的容器以完成镜像更新,即实现自动化更新 Docker 基础镜像;这对于需要持续部署和集成的项目来说非常有用,可以简化管理工作并确保我们的应用始终运行最新的镜像上。
关联资源:watchtower官网、GitHub
1)部署配置
实际,Watchtower本身就有一个镜像可以像其他容器一样运行:它可将docker的进程映射到容器内进行监控(即映射socket);默认watchtower会每5分钟检查更新一次,可以通过–interval, -i或者–schedule, -s设置更新间隔。 --interval, -i - 设置更新检测时间间隔,单位为秒。当然也可设置定时监测,使用–schedule, -s - 设置定时检测更新时间。格式为 6 字段 Cron 表达式,而非传统的 5 字段,即第一位是秒。
docker pull containrrr/watchtower
#启动Watchtower容器: watchtower 需要与 Docker API 进行交互以监控正在运行的容器,所以在使用时需要加上 -v 参数将 /var/run/docker.sock 映射到容器内
docker run -d --name watchtower \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower
#使用身份验证凭据和环境变量 REPO_USER 和 REPO_PASS
docker run -d --name watchtower -e REPO_USER=username \
-e REPO_PASS=password \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower container_to_watch --debug
#自动清除旧镜像,使用-c参数,即--cleanup
docker run -d --name watchtower \
--restart unless-stopped \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower \
--cleanup
#指定更新nginx容器,用于其他容器不使用经常更新的场景
docker run -d --name watchtower \
--restart unless-stopped \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower -c nginx
#配置自定义更新频率,比如每1h检查一次
docker run -d --name watchtower \
--restart unless-stopped \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower -c --interval 3600
#定时检查:秒 分 时 日期 月份 星期
docker run -d --name watchtower \
--restart unless-stopped \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower -c \
--schedule "0 0 2 * * *"
#立即更新:发送一个 SIGHUP 信号给 Watchtower 容器来让它立即检查更新
docker kill -s SIGHUP watchtower
3.2、docker-gc工具
它能够帮助你清理Docker宿主机,删除不再需要的容器和镜像。它会移除存在超过1小时的所有容器。同时,它会删除不属于任何遗留容器的镜像。它会执行一系列的检查和装配步骤,最终创建一个瘦身版本的镜像。
相关资源:docker-gc文档
3.3、docker-slim工具
docker-slim工具使用静态和动态分析方法来为你臃肿的镜像瘦身。
3.4、Rocker工具
代替dockerfile,Rocker传递Rockerfile来构建镜像运行容器。
3.5、ctop:容器的类Top界面
ctop能够提供多个容器的实时指标视图。
相关资源:GitHub
三、包管理和软件/镜像源
3.1、Snap 包管理命令

Snap是由 Ubuntu 的母公司 Canonical 推出的一种通用软件包格式,旨在简化软件分发,且与具体的 Linux 发行版无关。不同的 Linux 发行版中,通常会使用各自的包管理器和格式,比如:Debian 系使用的 APT;Fedora/RHEL 系使用的 DNF;Arch Linux 系使用的 Pacman。而 Snap 类似于 Flatpak,它通过容器化技术,将应用程序及其依赖项打包成一个独立的包,来解决兼容性问题。除了 Snap,另一个关键组件是 snapd,它是管理 Snap 包的后台服务,负责安装、更新和删除 Snap 包。它们都源自开源项目 Snapcraft,旨在帮助开发者创建、分发和更新适用于Linux的容器化软件包——Snaps。Snaps不仅包含了应用本身,还将其依赖项一并打包,这意味着它们可以在不修改的情况下,在各种主流Linux发行版中直接运行,这大大节省了大量适配工作,但实际工作中改工具并不好用,存在后期修改困难,软件源自由度缺失等问题。现在的Ubuntu 桌面中,我们几乎都使用的是 debian 包. 有的 Linux 系统上是使用 rpm 包.在 Snappy Ubuntu 上,我们使用的包叫做 snap 包.它的包的扩展名叫做.snap。Snapcraft的核心理念是“一次构建,到处运行”。其技术原理基于容器化,每个Snap都是一个独立的环境,运行在沙盒中,包含了所有运行应用所需的组件。snap 使用的命令有两个,分别是snap(属于snapd软件包)和snapcraft,前者用来管理软件包,后者用来创建软件包。
sudo apt install snapd #安装snap
sudo snap install snapcraft #安装snapcraft,使用 snapcraft 命令自己打包 snap 软件包;当想修改包时,可借用软件包叫squashfs-tools ,我们可以利用里面的unsquashfs命令解开 snap 的软件包,修改后,再使用mksquashfs命令重新打包
#snap不能换源,这个软件源的地址是直接写死;snap 安装的软件包都放在/var/lib/snapd/snaps目录,每个软件包都是一个单独的镜像,然后mount到了/snap目录下
sudo snap list #查看我们系统中安装了哪些软件包且是由 snap 安装的
sudo snap find 查找可用的软件包
sudo snap install 安装软件包
sudo snap remove 卸载软件包
sudo aptitude purge snapd
四、文件中转工具
4.1、Nginx配置下载目录
mkdir -p /datas/share
# 把需要分发的文件放进去
cp *你的文件 /datas/share/
printf "user:$(openssl passwd -crypt passwd)\n" > /etc/nginx/.down
vi /etc/nginx/conf.d/download.conf
server {
listen 80;
server_name hostname; # 写你的 IP 或域名
location / {
auth_basic "Login";
auth_basic_user_file /etc/nginx/.down;
root /datas/share; # f发布目录
allow 172.18.20.0/24;
deny all;
autoindex on/off; # 允许/禁止列目录
autoindex_exact_size off;
autoindex_localtime on;
charset utf-8;
# 1 GB 以上文件直接 sendfile,跳过用户态缓冲
sendfile on; #是否启用sendfile()
tcp_nopush on;
#从0.8.11版本开始, nginx 开始支持Linux native aio,需要2.6.22及以后版本的内核
directio 512k; # 可以设置为off或一个大小值,表示当文件大小大于等于这个值时启用directio,如果某处请求的文件大于等于512k,那么将启用directio,从而aio生效,进而sendfile不生效; 如果某处请求的文件小于512k,那么将禁用directio,从而aio也就不生效,转而使用sendfile(),即sendfile生效;对于大文件采用aio,节省cpu,而对于小文件,采用sendfile,减少拷贝;并且对于大文件aio采用directio,避免挤占文件系统缓存,让文件系统缓存更多的小文件;这种配置比较适合系统内存有限、小文件请求比较多、间隔有几个大文件请求的Web环境;如果内存足够大,那么应该充分利用文件系统缓存,而directio使得aio无法使用缓存是衡量最终是否需要采用aio的一个需要仔细考虑的因素;据nginx官网论坛来看,在linux系统的大部分场景下,目前因使用aio功能附加的限制而带来的实际效果估计并不太理想,按需开启,内核≥2.4 有效;
}
}
nginx -t # 检查语法
systemctl reload nginx
# 浏览目录
wget -r -np -nH --cut-dirs=1 http://<nginx-ip>/
# 测试下载单个文件
wget http://<nginx-ip>/yourfile
4.2、制作U盘(共享挂载云主机)
这里我们需要创建一个在 Linux 和 Windows 系统下都能读写的分区,且像 U 盘一样方便使用,那么最好就是选格式化为 exFAT 的文件系统。

其中,exFAT全称扩展文件分配表(Extended File Allocation Table File System),是微软为了解决 FAT32 不支持大文件问题而推出的新型文件格式。它专为闪存设备设计,最大可支持 1EB(18,446,744,073,709,551,616 字节 ,理论值:16×1024×1024TB ,1TB = 1024G)的文件大小,大文件读写快且损耗低,完全能满足日常像 4K 高清视频、大型 3D 模型等大容量文件存储和传输的需求,而FAT32 : 小文件读写尚可且受限单文件4GB ,大文件效率低且易产生碎片,长期使用性能下降明显;NTFS 支持大文件读写高效单跨设备兼容性不好。另exFAT 在 Mac 和 Windows 、Linux操作系统上都能通用,在跨平台使用时无需借助第三方软件,非常便捷,但exfat没有文件日志功能,在操作系统出现故障时,数据恢复的难度相对较大。LInux平台需借助exfatprogs进行支持, 它需要从源码编译安装。
# 安装依赖
sudo yum install autoconf automake libtool
# 克隆源码
git clone https://github.com/exfatprogs/exfatprogs.git
# 编译安装
cd exfatprogs
./autogen.sh
#如果报错:Can't exec "aclocal": No such file or directory at /usr/share/autoconf/AutomAte/FileUtils.pm line 274. autoreconf: error: aclocal failed with exit status: 2
#执行:
dnf install automake libtool
./configure
make
sudo make install
#完成后
fdisk /dev/sdk #t后选0b或0c 代表 W95 FAT32,W95 FAT32 LBA 最通用,Windows/Linux 都认;但实际对 exFAT 来说任何“数据分区”代码都行(07、0b、0c、b、e 均可),因为 exFAT 没有专属 MBR ID
mkfs.exfat /dev/sdk1 #之后挂载使用即可
这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
运维副业方向
运维,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
网络安全顾问与渗透测试
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
为什么我会推荐你网安是运维人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
运维转行学习路线
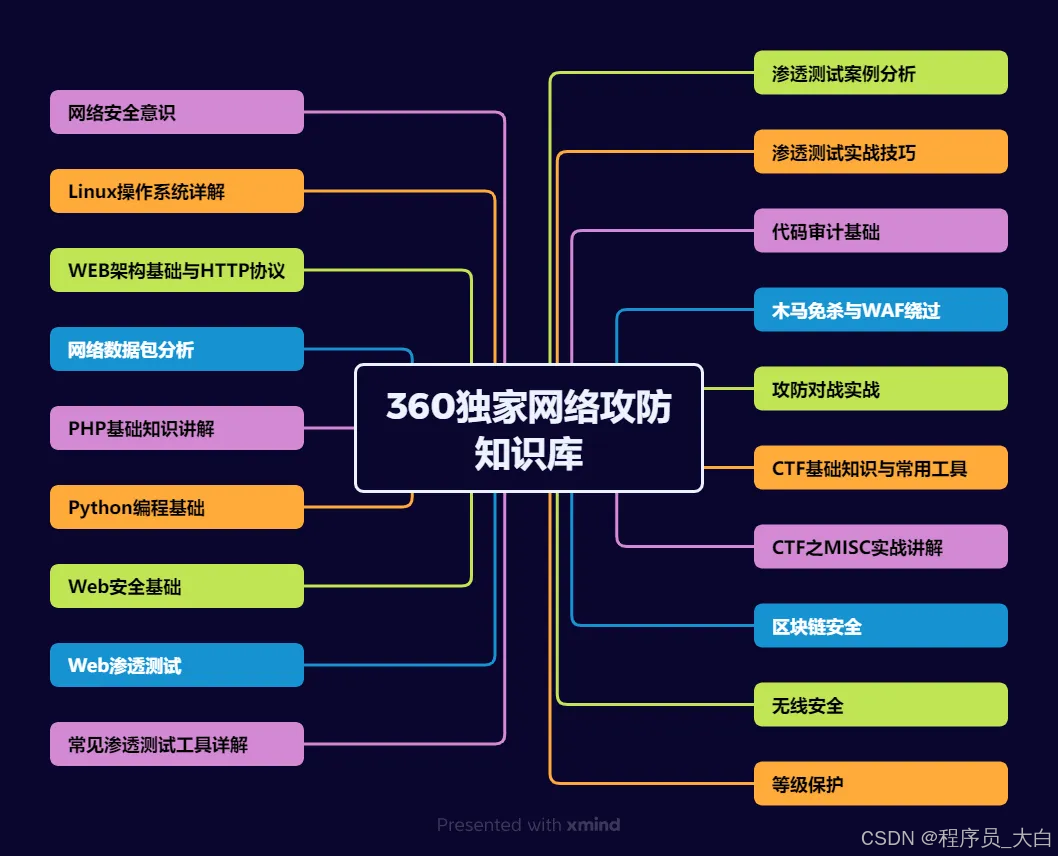
(一)第一阶段:网络安全筑基
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
(二)第二阶段:漏洞挖掘与 SRC 漏扫实战
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
(三)第三阶段:渗透测试技能学习
1. 阶段目标
全面掌握渗透测试理论与实战技能,能够独立完成渗透测试项目,编写规范的渗透测试报告,具备渗透测试工程师岗位能力,为护网红蓝对抗及应急响应提供技术支撑。
2. 学习内容
渗透测试核心理论:系统学习渗透测试流程、方法论及法律法规知识,明确渗透测试边界与规范(与红蓝对抗攻击边界要求一致)。
实战技能训练:开展漏洞扫描、漏洞利用、电商系统渗透测试、内网渗透、权限提升(Windows、Linux)、代码审计等实战训练,结合运维中熟悉的系统环境设计测试场景(强化红蓝对抗攻击端技术能力)。
工具开发实践:基于 Python 编程基础,学习渗透测试工具开发技巧,开发简单的自动化测试脚本(可拓展用于 SRC 漏扫自动化及应急响应辅助工具)。
报告编写指导:学习渗透测试报告的结构与编写规范,完成多个不同场景的渗透测试报告撰写练习(与 SRC 漏洞报告、应急响应报告撰写逻辑互通)。
(四)第四阶段:企业级安全攻防(含红蓝对抗)、应急响应
1. 阶段目标
掌握企业级安全攻防、护网红蓝对抗及应急响应核心技能,考取网安行业相关证书。
2. 学习内容
护网红蓝对抗专项:
-
红蓝对抗基础:学习护网行动背景、红蓝对抗规则(攻击范围、禁止行为)、红蓝双方角色职责(红队:模拟攻击;蓝队:防御检测与应急处置);
-
红队实战技能:强化内网渗透、横向移动、权限维持、免杀攻击等高级技巧,模拟护网中常见攻击场景;
-
蓝队实战技能:学习安全设备(防火墙、IDS/IPS、WAF)联动防御配置、安全监控平台(SOC)使用、攻击行为研判与溯源方法;
-
模拟护网演练:参与团队式红蓝对抗演练,完整体验 “攻击 - 检测 - 防御 - 处置” 全流程。
应急响应专项: -
应急响应流程:学习应急响应 6 步流程(准备 - 检测 - 遏制 - 根除 - 恢复 - 总结),掌握各环节核心任务;
-
实战技能:开展操作系统入侵响应(如病毒木马清除、异常进程终止)、数据泄露应急处置、漏洞应急修补等实战训练;
-
工具应用:学习应急响应工具(如 Autoruns、Process Monitor、病毒分析工具)的使用,提升处置效率;
-
案例复盘:分析真实网络安全事件应急响应案例(如勒索病毒事件),总结处置经验。
其他企业级攻防技能:学习社工与钓鱼、CTF 夺旗赛解析等内容,结合运维中企业安全防护需求深化理解。
证书备考:针对网安行业相关证书考试内容(含红蓝对抗、应急响应考点)进行专项复习,参加模拟考试,查漏补缺。
运维转行网络攻防知识库分享
网络安全这行,不是会几个工具就能搞定的。你得有体系,懂原理,能实战。尤其是从运维转过来的,别浪费你原来的经验——你比纯新人强多了。
但也要沉得住气,别学了两天Web安全就觉得自己是黑客了。内网、域渗透、代码审计、应急响应,要学的还多着呢。
如果你真的想转,按这个路子一步步走,没问题。如果你只是好奇,我劝你再想想——这行要持续学习,挺累的,但也是真有意思。
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
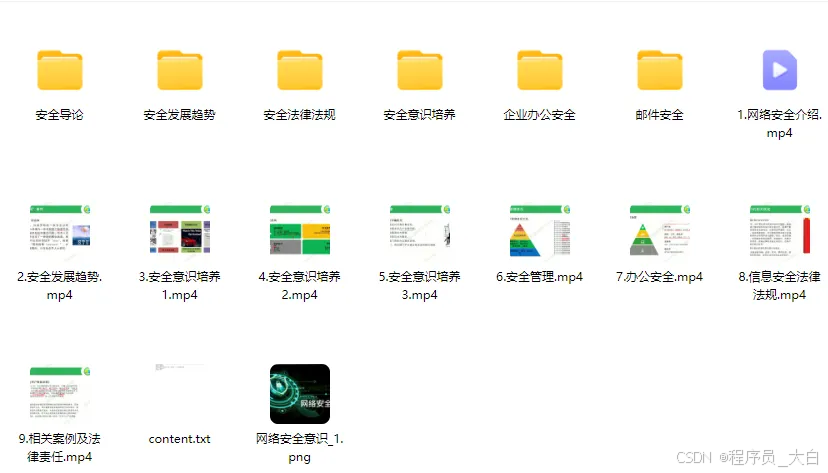
1、网络安全意识
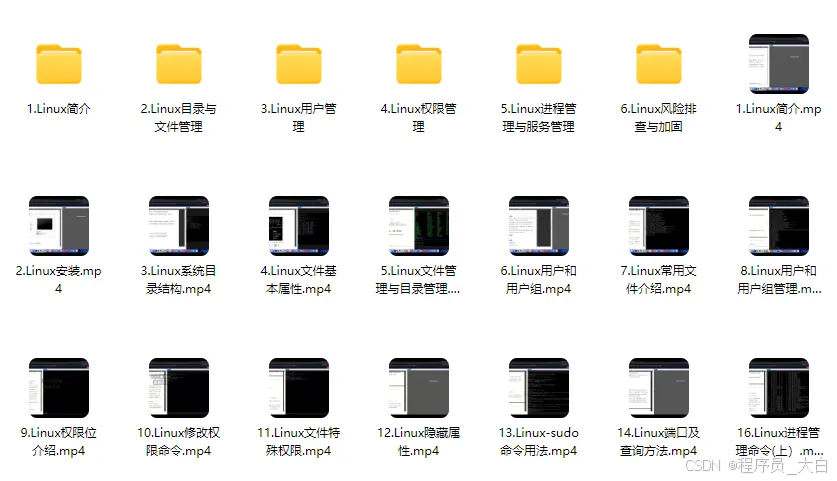
2、Linux操作系统
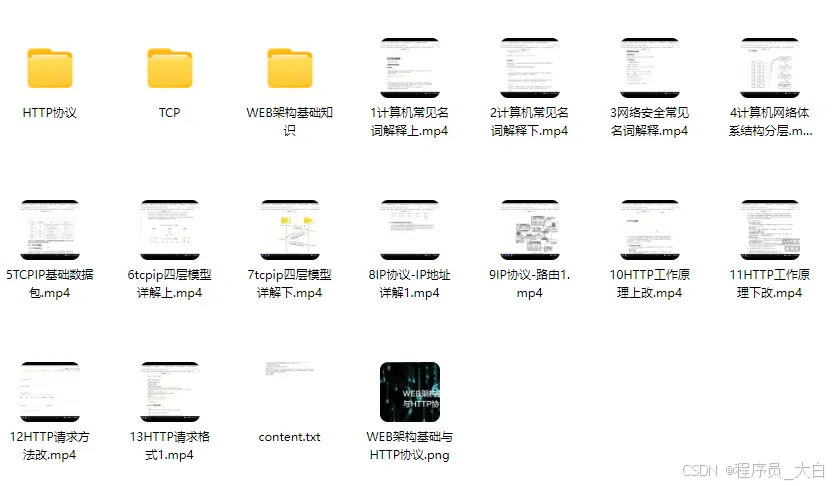
3、WEB架构基础与HTTP协议
4、Web渗透测试
5、渗透测试案例分享
6、渗透测试实战技巧

7、攻防对战实战
8、CTF之MISC实战讲解
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 2046
2046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









