







1、批量文件重命名神器在工作中,我们常常需要对大量文件进行批量重命名,Python帮你轻松搞定!
import os
def batch_rename(path, prefix='', suffix=''):
for i, filename in enumerate(os.listdir(path)):
new_name = f"{prefix}{i:03d}{suffix}{os.path.splitext(filename)[1]}"
old_file = os.path.join(path, filename)
new_file = os.path.join(path, new_name)
os.rename(old_file, new_file)
# 使用示例:
batch_rename('/path/to/your/directory', 'file_', '.txt')
2、自动发送邮件通知告别手动发送,用Python编写定时发送邮件的自动化脚本。
import smtplib
from email.mime.text import MIMEText
def send_email(to_addr, subject, content):
smtp_server = 'smtp.example.com'
username = 'your-email@example.com'
password = 'your-password'
msg = MIMEText(content)
msg['Subject'] = subject
msg['From'] = username
msg['To'] = to_addr
server = smtplib.SMTP(smtp_server, 587)
server.starttls()
server.login(username, password)
server.sendmail(username, to_addr, msg.as_string())
server.quit()
# 使用示例:
send_email('receiver@example.com', '每日报告提醒', '今日报告已生成,请查收。')
3、定时任务自动化执行使用Python调度库,实现定时执行任务的自动化脚本。
import schedule
import time
def job_to_schedule():
print("当前时间:", time.ctime(), "任务正在执行...")
# 定义每天9点执行任务
schedule.every().day.at("09:00").do(job_to_schedule)
while True:
schedule.run_pending()
time.sleep(1)
# 使用示例:
# 运行此脚本后,每天上午9点会自动打印当前时间及提示信息
4、数据库操作自动化简化数据库管理,Python帮你自动化执行CRUD操作。
import sqlite3
def create_connection(db_file):
conn = None
try:
conn = sqlite3.connect(db_file)
print(f"成功连接到SQLite数据库:{db_file}")
except Error as e:
print(e)
return conn
def insert_data(conn, table_name, data_dict):
keys = ', '.join(data_dict.keys())
values = ', '.join(f"'{v}'" for v in data_dict.values())
sql = f"INSERT INTO {table_name} ({keys}) VALUES ({values});"
try:
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
print("数据插入成功!")
except sqlite3.Error as e:
print(e)
# 使用示例:
conn = create_connection('my_database.db')
data = {'name': 'John Doe', 'age': 30}
insert_data(conn, 'users', data)
# 在适当时候关闭数据库连接
conn.close()
5、网页内容自动化抓取利用BeautifulSoup和requests库,编写Python爬虫获取所需网页信息。
import requests
from bs4 import BeautifulSoup
def fetch_web_content(url):
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# 示例提取页面标题
title = soup.find('title').text
return title
else:
return "无法获取网页内容"
# 使用示例:
url = 'https://example.com'
web_title = fetch_web_content(url)
print("网页标题:", web_title)
6、数据清洗自动化使用Pandas库,实现复杂数据处理和清洗的自动化。
import pandas as pd
def clean_data(file_path):
df = pd.read_csv(file_path)
# 示例:处理缺失值
df.fillna('N/A', inplace=True)
# 示例:去除重复行
df.drop_duplicates(inplace=True)
# 示例:转换列类型
df['date_column'] = pd.to_datetime(df['date_column'])
return df
# 使用示例:
cleaned_df = clean_data('data.csv')
print("数据清洗完成,已准备就绪!")
7、图片批量压缩用Python快速压缩大量图片以节省存储空间。
from PIL import Image
import os
def compress_images(dir_path, quality=90):
for filename in os.listdir(dir_path):
if filename.endswith(".jpg") or filename.endswith(".png"):
img = Image.open(os.path.join(dir_path, filename))
img.save(os.path.join(dir_path, f'compressed_{filename}'), optimize=True, quality=quality)
# 使用示例:
compress_images('/path/to/images', quality=80)
8、文件内容查找替换Python脚本帮助你一键在多个文件中搜索并替换指定内容。
import fileinput
def search_replace_in_files(dir_path, search_text, replace_text):
for line in fileinput.input([f"{dir_path}/*"], inplace=True):
print(line.replace(search_text, replace_text), end='')
# 使用示例:
search_replace_in_files('/path/to/files', 'old_text', 'new_text')
9、日志文件分析自动化通过Python解析日志文件,提取关键信息进行统计分析。
def analyze_log(log_file):
with open(log_file, 'r') as f:
lines = f.readlines()
error_count = 0
for line in lines:
if "ERROR" in line:
error_count += 1
print(f"日志文件中包含 {error_count} 条错误记录。")
# 使用示例:
analyze_log('application.log')
10、数据可视化自动化利用Matplotlib库,实现数据的自动图表生成。
import matplotlib.pyplot as plt
import pandas as pd
def visualize_data(data_file):
df = pd.read_csv(data_file)
# 示例:绘制柱状图
df.plot(kind='bar', x='category', y='value')
plt.title('数据分布')
plt.xlabel('类别')
plt.ylabel('值')
plt.show()
# 使用示例:
visualize_data('data.csv')
11、邮件附件批量下载通过Python解析邮件,自动化下载所有附件。
import imaplib
import email
from email.header import decode_header
import os
def download_attachments(email_addr, password, imap_server, folder='INBOX'):
mail = imaplib.IMAP4_SSL(imap_server)
mail.login(email_addr, password)
mail.select(folder)
result, data = mail.uid('search', None, "ALL")
uids = data[0].split()
for uid in uids:
_, msg_data = mail.uid('fetch', uid, '(RFC822)')
raw_email = msg_data[0][1].decode("utf-8")
email_message = email.message_from_string(raw_email)
for part in email_message.walk():
if part.get_content_maintype() == 'multipart':
continue
if part.get('Content-Disposition') is None:
continue
filename = part.get_filename()
if bool(filename):
file_data = part.get_payload(decode=True)
with open(os.path.join('/path/to/download', filename), 'wb') as f:
f.write(file_data)
mail.close()
mail.logout()
# 使用示例:
download_attachments('your-email@example.com', 'your-password', 'imap.example.com')
12、定时发送报告自动化根据数据库或文件内容,自动生成并定时发送日报/周报。
import pandas as pd
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
def generate_report(source, to_addr, subject):
# 假设这里是从数据库或文件中获取数据并生成报告内容
report_content = pd.DataFrame({"Data": [1, 2, 3], "Info": ["A", "B", "C"]}).to_html()
msg = MIMEMultipart()
msg['From'] = 'your-email@example.com'
msg['To'] = to_addr
msg['Subject'] = subject
msg.attach(MIMEText(report_content, 'html'))
server = smtplib.SMTP('smtp.example.com', 587)
server.starttls()
server.login('your-email@example.com', 'your-password')
text = msg.as_string()
server.sendmail('your-email@example.com', to_addr, text)
server.quit()
# 使用示例:
generate_report('data.csv', 'receiver@example.com', '每日数据报告')
# 结合前面的定时任务脚本,可实现定时发送功能
13、自动化性能测试使用Python的locust库进行API接口的压力测试。
from locust import HttpUser, task, between
class WebsiteUser(HttpUser):
wait_time = between(5, 15) # 定义用户操作之间的等待时间
@task
def load_test_api(self):
response = self.client.get("/api/data")
assert response.status_code == 200 # 验证返回状态码为200
@task(3) # 指定该任务在总任务中的执行频率是其他任务的3倍
def post_data(self):
data = {"key": "value"}
response = self.client.post("/api/submit", json=data)
assert response.status_code == 201 # 验证数据成功提交后的响应状态码
# 运行Locust命令启动性能测试:
# locust -f your_test_script.py --host=http://your-api-url.com
14、自动化部署与回滚脚本使用Fabric库编写SSH远程部署工具,这里以部署Django项目为例:
from fabric import Connection
def deploy(host_string, user, password, project_path, remote_dir):
c = Connection(host=host_string, user=user, connect_kwargs={"password": password})
with c.cd(remote_dir):
c.run('git pull origin master') # 更新代码
c.run('pip install -r requirements.txt') # 安装依赖
c.run('python manage.py migrate') # 执行数据库迁移
c.run('python manage.py collectstatic --noinput') # 静态文件收集
c.run('supervisorctl restart your_project_name') # 重启服务
# 使用示例:
deploy(
host_string='your-server-ip',
user='deploy_user',
password='deploy_password',
project_path='/path/to/local/project',
remote_dir='/path/to/remote/project'
)
# 对于回滚操作,可以基于版本控制系统实现或创建备份,在出现问题时恢复上一版本的部署。
这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
运维副业方向
运维,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
网络安全顾问与渗透测试
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
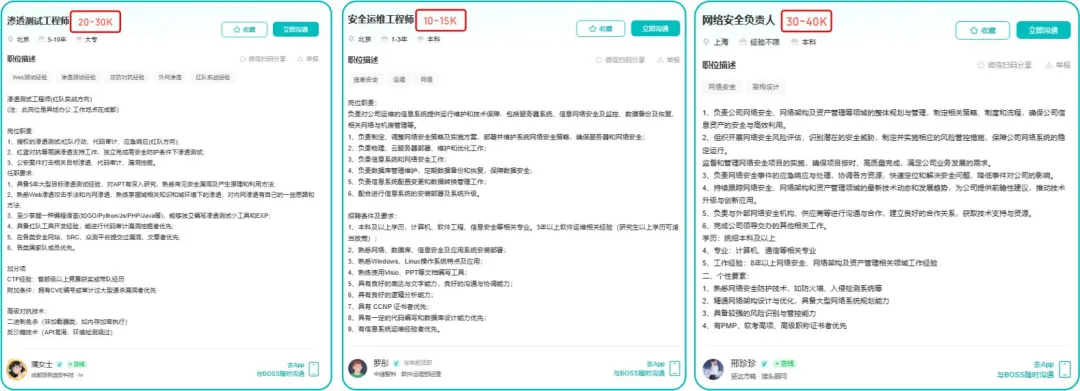
为什么我会推荐你网安是运维人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
运维转行学习路线
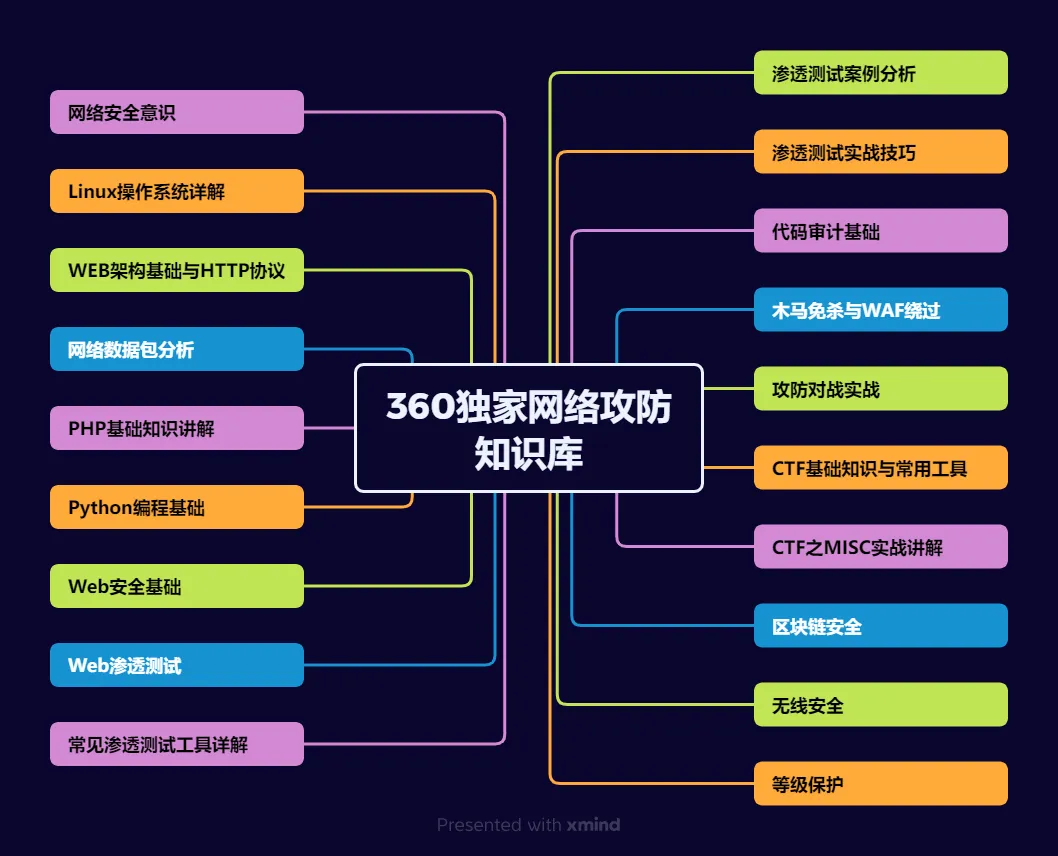
(一)第一阶段:网络安全筑基
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
(二)第二阶段:漏洞挖掘与 SRC 漏扫实战
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取