



 文章探讨了在RocketMQ中如何实施灰度发布。当升级服务时,可以通过灰度发布逐渐引入新版本,以降低风险。对于只升级消费者或同时升级生产者的情况,文章提供了不同的策略,包括在消息中添加灰度标识、使用Tag过滤和SQL92表达式进行消息筛选。这种方法能帮助控制升级的影响范围,但也会带来额外的资源压力。
文章探讨了在RocketMQ中如何实施灰度发布。当升级服务时,可以通过灰度发布逐渐引入新版本,以降低风险。对于只升级消费者或同时升级生产者的情况,文章提供了不同的策略,包括在消息中添加灰度标识、使用Tag过滤和SQL92表达式进行消息筛选。这种方法能帮助控制升级的影响范围,但也会带来额外的资源压力。
今天来聊一聊 RocketMQ 的灰度方案。
灰度发布是指在黑与白之间,平滑过渡的一种发布方式。在大流量的系统中,如果一次升级改造范围比较大,或者影响内容不太确定,一般会采用切量的方式进行升级,这样可以减少生产变更带来的影响。

如上图,对 ServiceA 这个服务进行升级,采用灰度发布,先升级 Server5,一周后如果没有问题,升级 Server4 和 Server 3,再运行一周没有问题,把剩下两个节点都升级。
上面的案例是一个 RPC 的调用。但如果使用消息队列该怎么做呢?使用消息队列,并不能使用网关来进行流量转发。这里需要分不同场景进行分析。
1 只升级消费者
这是最简单的情况,比如只有消费者修改了消费逻辑,就是 RPC 调用的情况类似,我们只要把消费者进行灰度发布就可以。如下图:

2 生产者也升级
下面是一个订单的实体类,我们新加了一个属性,订单生成时间:
public class Order {
private Long id;
private Long userId;
private Long productId;
private Integer count;
private BigDecimal payAmount;
/**订单状态:0:创建中;1:已完结*/
private Integer status;
/**新加属性,订单生成时间*/
private String createTime;
}
消费端的改造是需要对 createTime 这个属性进行处理。
2.1 消费端过滤
在生产者的 Order 类中增加 createTime 属性,如果我们直接使用 createTime 属性来过滤,消费者并不能实现灰度,因为所有的消费者都可能会拉取到带有 createTime 属性的消息。
RocketMQ 中 Message 的定义如下:
public class Message implements Serializable {
private String topic;
private int flag;
private Map<String, String> properties;
private byte[] body;
private String transactionId;
}
可以在 properties 属性中增加一个灰度标识,比如生产者发送消息的时候封装如下:
Message msg = buildMessage(topic);
msg.putUserProperty("gray", "true");
注意:也可以在 SendMessageHook 这个钩子函数中定义。通过这种方式可以在消费端新增加一个灰度 Consumer Group,用来对灰度消息则进行消费。如下图:
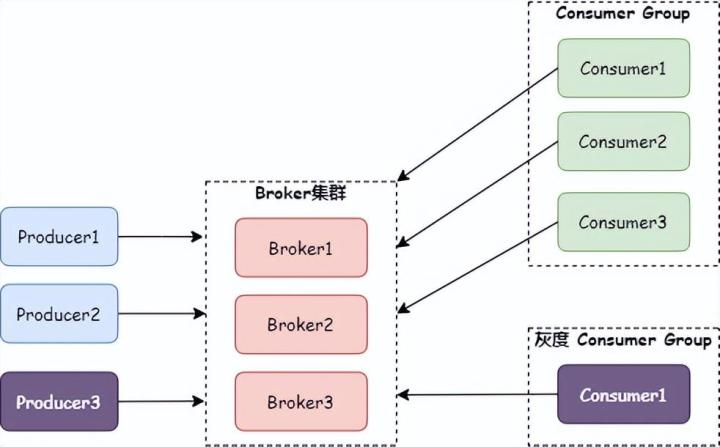
对于灰度 Consumer Group 判断到 gray 属性是 true 时进行消费,而对于普通 Consumer Group,判断到 gray 属性不等于 true 时再进行消费。这里可以借助 RocketMQ 客户端的 FilterMessageHook,代码如下:
defaultMQPushConsumerImpl.registerFilterMessageHook(new FilterMessageHook() {
@Override
public String hookName() {
return "filterHook";
}
@Override
public void filterMessage(FilterMessageContext context) {
List<MessageExt> messages = context.getMsgList();
context.setMsgList(messages.stream().filter(m -> StringUtils.equals(m.getProperty("gray"),"true"))
.collect(Collectors.toList()));
}
});
不过这样会有两个问题,灰度和正常的两个 Consumer Group 相当于是广播组:
-
两个组都要对所有的消息进行拉取,比如本来使用灰度发布计划切 10% 的流量,但实际上全部流量都切过去了,只是根据属性做了判断。这让消费端整体承担了两倍的压力;
-
因为两个消费者组都要去 Broker 拉取消息,Broker 的压力也增加了一倍。
2.2 Broker 过滤
2.2.1 使用 tag 过滤
如果一个 Consumer 不订阅一个 Topic 中的全部消息,可以通过 Tag 来过滤。比如一个 Consumer 订阅了 TopicA 这个 Topic 中的 Tag1 和 Tag2 这两个 tag,那这个 Consumer 的订阅关系如下图:
SubscriptionData 这个对象封装了 Topic、tag 以及所订阅 tag 的 hashcode 集合。
Consumer 发送拉取消息请求时,会把订阅关系传给 Broker(Broker 解析成 SubscriptionData 对象),Broker 使用 consumequeue 获取消息时,首先判断判断最后 8 个字节的 tag hashcode 是否在 SubscriptionData 的 codeSet 中,如果不在就跳过,如果存在把消息返回给 Consumer。如下图:
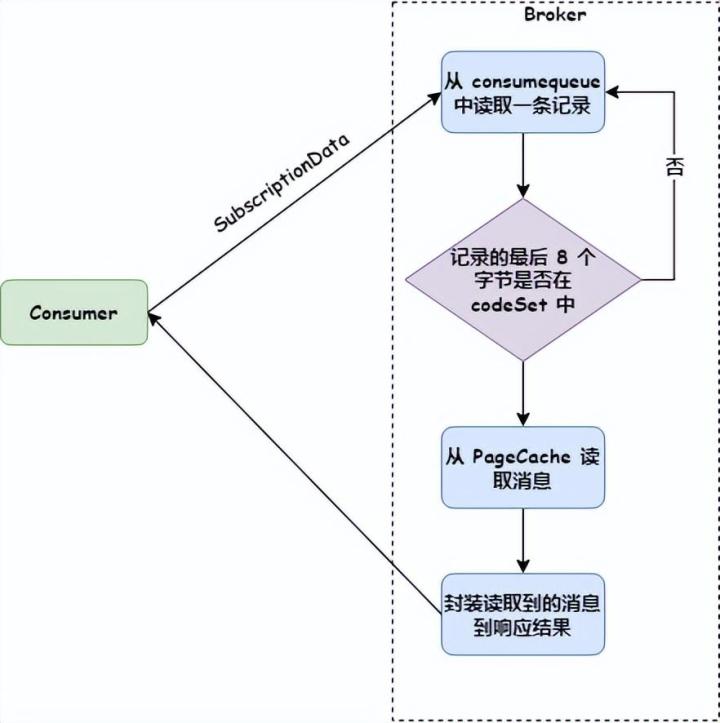
这样可以在灰度 Producer 发送消息时加上 Tag,如下代码:
Message msg = new Message();
msg.setBody("Test");
msg.setTopic("Topic");
msg.setTags("Gray");
而在灰度消费者订阅 Gray 这个 tag。这样就避免了 2.1 节中消息全量拉取的问题。
2.2.2 使用 SQL92 过滤
使用 SQL92 过滤,可以应对更加复杂的场景,不仅可以过滤 Tag,还可以过滤 UserProperty。
比如下面是一个生产者的代码:
Message msg = new Message();
msg.setTopic("testTopic");
msg.setTags("tag1");
msg.putUserProperty("gray","true");
这样消费者初始化的时候,可以定义使用 SQL92 过滤,代码如下:
consumer.subscribe("testTopic",
MessageSelector.bySql("(TAGS is not null and TAGS in TAGS='''''tag1''''')" +
"and (gray is not null gray='true')"));
下面是 bySql 的源代码:
public static MessageSelector bySql(String sql) {
return new MessageSelector(ExpressionType.SQL92, sql);
}
3 总结
本文介绍了 RocketMQ 灰度消息的使用方法,场景比较简单。对于全链路的复杂灰度场景,可以参考使用阿里的微服引擎 MSE。

















 2836
2836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









