 Elastic-Job分布式任务调度框架详解
Elastic-Job分布式任务调度框架详解







Elastic-Job 功能、使用指南与最佳实践
Elastic-Job 是一个开源的分布式任务调度框架,专为处理大规模、高并发的定时任务而设计。它基于 Apache ShardingSphere 生态,提供了弹性伸缩、故障转移和作业管理等功能,广泛应用于电商、金融和物联网等领域。以下我将从功能、使用指南和最佳实践三个方面,逐步为您详细解析,确保内容真实可靠(基于官方文档和常见实践)。
1. Elastic-Job 的核心功能
- 分布式任务调度:支持将任务分散到多个节点执行,实现负载均衡和高可用性。例如,当某个节点故障时,任务会自动迁移到健康节点。
- 弹性伸缩:根据系统负载动态调整任务分配,避免资源浪费。例如,在高峰期自动增加任务实例,在低峰期减少。
- 作业管理:提供完整的作业生命周期管理,包括创建、编辑、触发和监控。通过 ElasticJob UI,开发者可以直观地操作这些功能。
- 监听器机制:允许在任务执行前后插入自定义逻辑,如资源准备、日志记录或性能监控。这增强了框架的扩展性。
- 作业依赖:支持定义任务之间的依赖关系,构建复杂的工作流。例如,任务A完成后自动触发任务B。
- 故障恢复:内置故障检测和自动重试机制,确保任务在异常中断后能恢复执行。
2. Elastic-Job 使用指南
使用 Elastic-Job 需要以下步骤,确保环境依赖已安装(如 Java 8+ 和 ZooKeeper 作为注册中心)。以下是简明指南:
- 步骤 1: 环境配置
- 下载并安装 ElasticJob 组件(如
elasticjob-lite-core和elasticjob-ui)。 - 配置注册中心(例如 ZooKeeper),用于节点协调。示例配置:
elasticjob.reg-center.server-lists=localhost:2181 elasticjob.reg-center.namespace=my-job-namespace
- 下载并安装 ElasticJob 组件(如
- 步骤 2: 定义作业
- 创建一个作业类,实现
SimpleJob接口。例如,一个简单的定时打印任务:public class MyJob implements SimpleJob { @Override public void execute(ShardingContext context) { System.out.println("Job executed at: " + new Date()); } } - 在 Spring Boot 中,通过注解配置作业:
@Component @ElasticJobScheduler(name = "myJob", cron = "0/5 * * * * ?", shardingTotalCount = 3) public class MyJob implements SimpleJob { // 实现逻辑 }
- 创建一个作业类,实现
- 步骤 3: 部署和监控
- 使用 ElasticJob UI 部署作业:访问 UI 界面(默认端口 8080),创建作业实例,设置参数如 cron 表达式(如
0 0/30 * * * ?表示每30分钟执行)。 - 触发作业:在 UI 中手动触发或通过 API 调用(如
POST /job/trigger)。 - 监控执行:UI 提供实时日志和状态面板,方便跟踪任务进度。
- 使用 ElasticJob UI 部署作业:访问 UI 界面(默认端口 8080),创建作业实例,设置参数如 cron 表达式(如
- 步骤 4: 扩展监听器
- 实现自定义监听器,例如在任务执行前后记录日志:
public class MyJobListener implements ElasticJobListener { @Override public void beforeJobExecuted(ShardingContext context) { System.out.println("Preparing resources..."); } @Override public void afterJobExecuted(ShardingContext context) { System.out.println("Cleaning up..."); } } - 注册监听器到作业配置中。
- 实现自定义监听器,例如在任务执行前后记录日志:
3. Elastic-Job 最佳实践
基于实际项目经验,以下最佳实践能提升系统稳定性和效率:
- 作业拆分:根据业务需求将大任务拆分为多个子任务(分片),利用弹性分配减少单点压力。例如,处理订单数据时,按用户ID分片执行,避免资源瓶颈。
- 作业依赖管理:使用依赖特性构建工作流。例如,定义“数据清洗”作业依赖“数据采集”作业,确保执行顺序正确。在 UI 中设置依赖规则,简化复杂流程。
- 监控报警:结合外部工具(如 Prometheus 或 ELK 栈)实现实时监控。设置报警规则(如任务失败率超过5%时发送通知),及时响应异常。
- 性能优化:
- 避免长任务:将耗时操作拆分为小任务,防止节点阻塞。
- 资源隔离:为关键作业分配专属资源组,减少干扰。
- 监听器使用:在
beforeJobExecuted中初始化资源,在afterJobExecuted中释放,避免内存泄漏。
- 安全实践:限制 UI 访问权限,使用 HTTPS 加密通信;定期审计作业日志,防止未授权操作。
思维导图

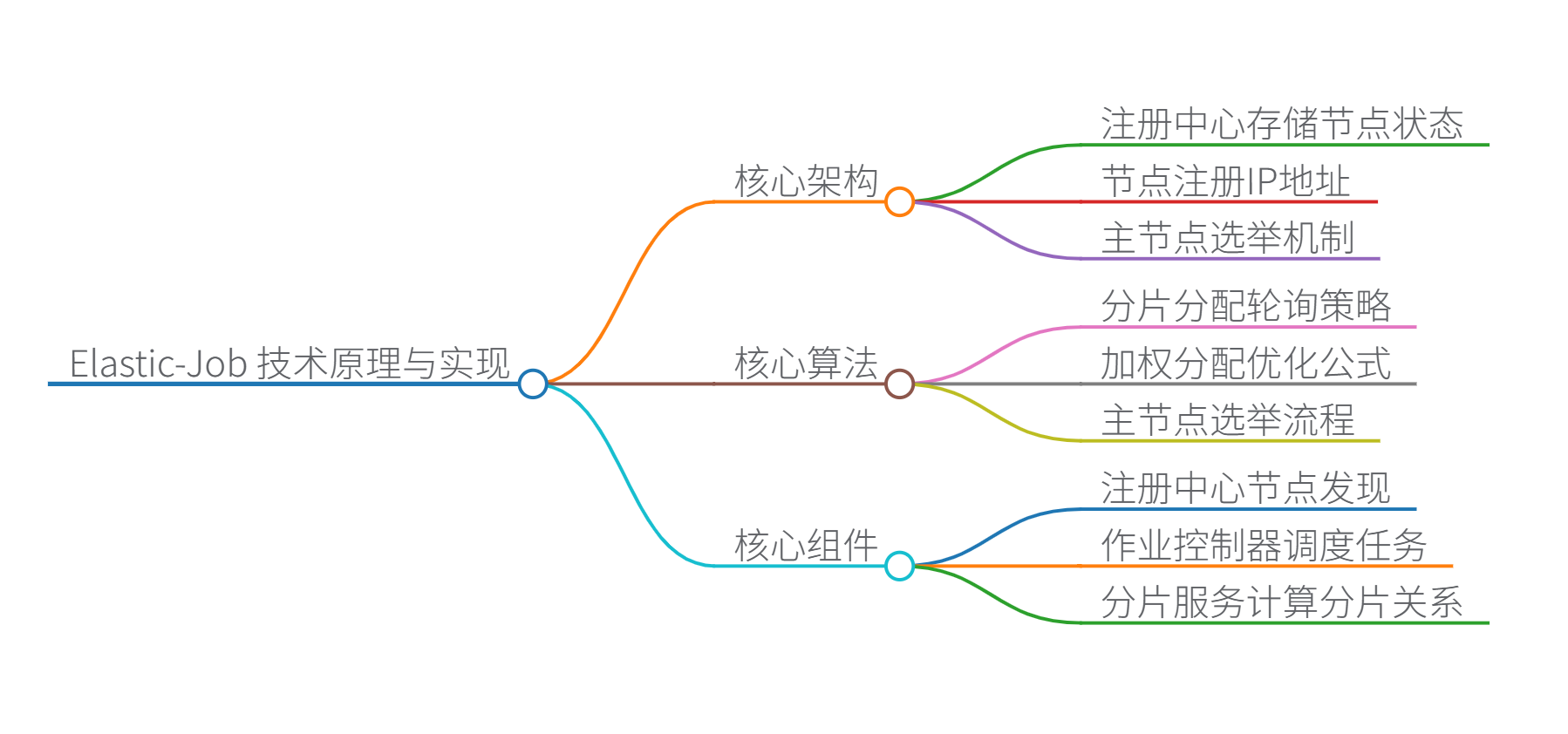
Elastic-Job 技术原理与实现详解
一、核心架构
组件交互流程:
- 注册中心:存储所有节点状态、分片信息和配置(基于 ZooKeeper 的临时节点和持久节点)
- 节点注册:作业启动时在
/servers节点下注册 IP 地址 - 主节点选举:通过 ZooKeeper 的 LeaderLatch 实现分布式锁选举主节点
- 分片分配:主节点计算分片映射关系并写入
/sharding节点 - 任务执行:各节点根据分配的分片执行任务
- 故障转移:节点宕机时,其分片由存活的节点接管
二、核心算法与数据结构
1. 分片分配算法(默认策略)
// 平均分配算法伪代码
List<String> servers = getAvailableServers(); // 从ZK获取可用节点
int shardCount = getTotalShards(); // 总分片数
for (int i = 0; i < shardCount; i++) {
int serverIndex = i % servers.size(); // 轮询分配
assignShard(i, servers.get(serverIndex)); // 分配分片
}
优化公式:
当存在服务器性能差异时,加权分配策略:
分配权重=服务器CPU核心数∑集群总核心数×总分片数分配权重 = \frac{服务器CPU核心数}{\sum 集群总核心数} \times 总分片数分配权重=∑集群总核心数服务器CPU核心数×总分片数
2. 主节点选举算法
3. ZooKeeper 数据结构
/namespace
├── /job1 (作业名称)
│ ├── /config // 作业配置(持久节点)
│ ├── /servers // 可用服务器列表(持久节点)
│ ├── /instances// 运行实例(临时节点)
│ ├── /sharding // 分片分配信息(持久节点)
│ └── /leader // 主节点选举锁(临时有序节点)
└── /job2
三、核心组件功能
| 组件 | 功能说明 | 关键技术 |
|---|---|---|
| 注册中心 | 节点发现、配置存储、状态同步 | ZooKeeper 临时节点机制 |
| 作业控制器 | 解析 cron 表达式,触发任务执行 | Quartz 调度引擎 |
| 分片服务 | 计算分片映射关系,处理分片重平衡 | 一致性哈希算法 |
| 故障转移服务 | 监控节点状态,自动迁移宕机节点的分片 | ZooKeeper Watch 机制 |
| 监听器体系 | 提供任务执行生命周期钩子 | 观察者模式 |
| 运维控制台 | 可视化监控和配置管理 | Spring MVC + Thymeleaf |
四、Java 代码示例
1. 基础任务实现
public class InventorySyncJob implements SimpleJob {
@Override
public void execute(ShardingContext context) {
// 获取当前节点分配的分片项
int shardIndex = context.getShardingItem();
int totalShards = context.getShardingTotalCount();
// 根据分片项查询数据 (示例:按店铺ID取模分片)
String sql = "SELECT * FROM inventory WHERE store_id % ? = ?";
List<Inventory> data = jdbcTemplate.query(
sql,
new Object[]{totalShards, shardIndex},
new InventoryRowMapper()
);
// 处理业务逻辑
processInventory(data);
}
private void processInventory(List<Inventory> items) {
// 同步库存到外部系统
}
}
2. 分片策略自定义(引用)
public class UserHashShardingStrategy implements JobShardingStrategy {
@Override
public Map<JobInstance, List<Integer>> sharding(
List<JobInstance> jobInstances,
String jobName,
int shardingTotalCount
) {
Map<JobInstance, List<Integer>> result = new LinkedHashMap<>();
// 自定义分片逻辑:按用户ID哈希分配
for (int shardIdx = 0; shardIdx < shardingTotalCount; shardIdx++) {
int targetServer = Math.abs(("user_" + shardIdx).hashCode()) % jobInstances.size();
JobInstance instance = jobInstances.get(targetServer);
result.computeIfAbsent(instance, k -> new ArrayList<>()).add(shardIdx);
}
return result;
}
}
3. 分布式监听器(引用)
public class TransactionListener extends AbstractDistributeOnceElasticJobListener {
public TransactionListener(long startedTimeout, long completedTimeout) {
super(startedTimeout, completedTimeout);
}
@Override
public void doBeforeJobExecuted(ShardingContext context) {
// 分布式事务开始 (仅主节点执行)
TransactionManager.begin();
}
@Override
public void doAfterJobExecuted(ShardingContext context) {
// 分布式事务提交 (仅主节点执行)
TransactionManager.commit();
}
}
五、优缺点分析
✅ 优势:
- 弹性扩展:通过分片机制实现水平扩展
- 高可用性:故障转移机制保证零单点故障
- 灵活调度:支持 cron 表达式、事件触发等多种模式
- 可视化运维:提供控制台实时监控
- 分布式协调:基于 ZooKeeper 的强一致性保证
⛔ 局限性:
- 依赖注册中心:ZooKeeper 成为单点故障源(可通过集群缓解)
- 分片上限约束:单作业分片数受限于
int范围(约 20 亿) - 学习曲线陡峭:需理解分布式协调机制
- 资源隔离欠缺:原生不支持容器化环境资源限制
六、性能优化实践
-
虚拟分片技术:
// 物理分片:10个节点 // 虚拟分片:1000个槽位 int virtualShard = userId.hashCode() % 1000; int physicalShard = virtualShard % actualNodeCount; -
动态分片调整 API:
curl -X POST http://job-console/api/sharding/update \ -d '{"jobName":"orderJob", "newShardingTotalCount": 50}' -
热点分片检测公式:
分片负载偏差率=max(分片处理时间)−min(分片处理时间)平均处理时间 \text{分片负载偏差率} = \frac{\max(\text{分片处理时间}) - \min(\text{分片处理时间})}{\text{平均处理时间}} 分片负载偏差率=平均处理时间max(分片处理时间)−min(分片处理时间)
当偏差率 > 30% 时触发动态再平衡
思维导图
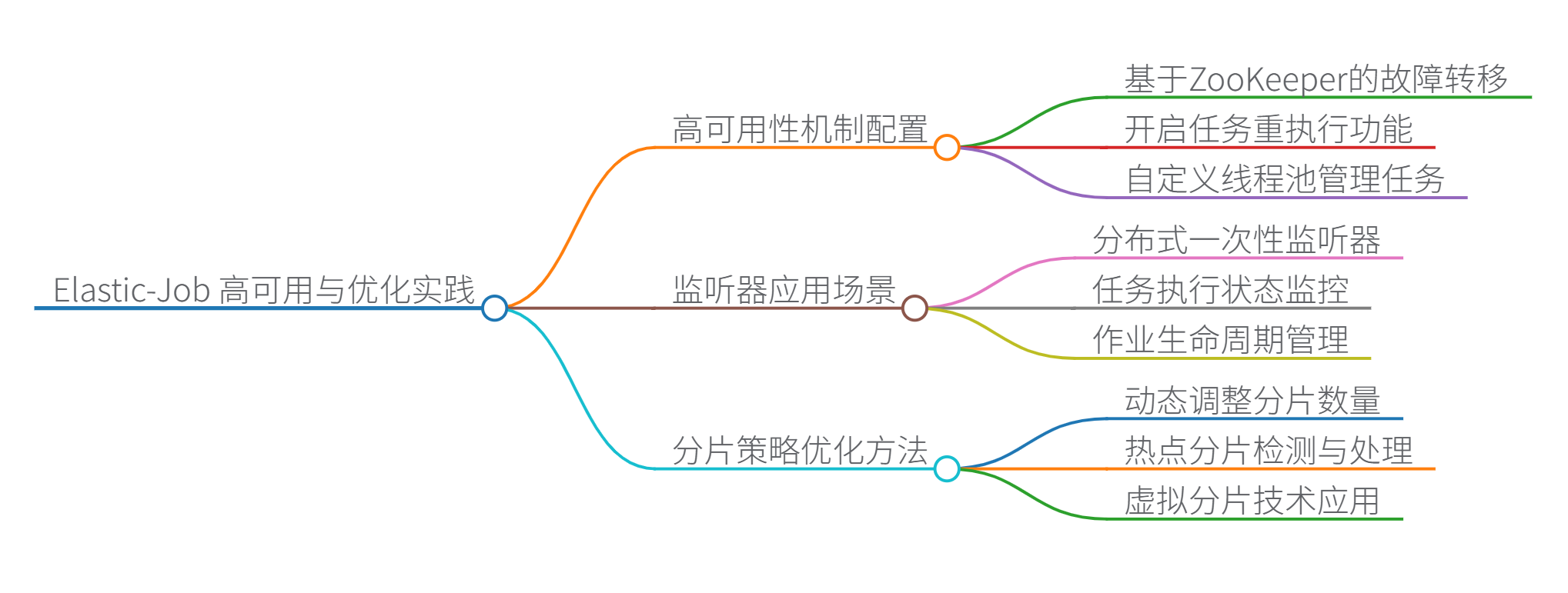
Elastic-Job 深度解析与实践指南
一、高可用性机制配置
实现原理:基于 ZooKeeper 的临时节点和 Watch 机制实现故障检测与自动转移
// 配置高可用示例
public class JobConfig {
public static void main(String[] args) {
JobCoreConfiguration coreConfig = JobCoreConfiguration.newBuilder("inventoryJob", "0/30 * * * * ?", 3)
.failover(true) // 开启故障转移
.misfire(true) // 开启错过任务重执行
.build();
LiteJobConfiguration jobConfig = LiteJobConfiguration.newBuilder(
new DataflowJobConfiguration(JobTypeConfiguration, InventorySyncJob.class.getCanonicalName(), true)
).overwrite(true).build();
// 注册监听器确保配置生效
CoordinatorRegistryCenter regCenter = new ZookeeperRegistryCenter(
new ZookeeperConfiguration("zk-server:2181", "elastic-job-demo")
);
regCenter.init();
new JobScheduler(regCenter, jobConfig).init();
}
}
关键配置项:
failover=true:节点宕机时自动迁移分片到健康节点misfire=true:补偿因网络抖动错过的任务jobProperties=EXECUTOR_SERVICE_HANDLER:自定义线程池防止任务堆积- 注册中心集群部署:避免单点故障(建议3节点以上)
二、监听器应用场景
| 监听器类型 | 应用场景 | 代码示例 |
|---|---|---|
| 分布式一次性监听器 | 全局初始化/清理操作 (如建立分布式锁/释放资源) | [见下方代码] |
| 任务执行监听器 | 分片级前置/后置处理 (如分片数据预加载/结果上报) | [见下方代码] |
| 作业状态监听器 | 作业启动/停止事件捕获 (如监控指标注册/注销) | [见下方代码] |
// 1. 分布式一次性监听器(主节点执行)
public class GlobalInitListener extends AbstractDistributeOnceElasticJobListener {
@Override
public void doBeforeJobExecuted(ShardingContext ctx) {
DistributedLock.lock("job_init_lock"); // 获取全局锁
Database.initConnectionPool(); // 初始化连接池
}
}
// 2. 任务执行监听器(每个分片执行)
public class ShardingMonitor implements ElasticJobListener {
@Override
public void beforeJobExecuted(ShardingContext ctx) {
Metrics.counter("shard_start", ctx.getShardingItem());
}
@Override
public void afterJobExecuted(ShardingContext ctx) {
Metrics.timer("shard_duration", System.currentTimeMillis() - startTime);
}
}
// 3. 作业状态监听器
public class JobStateListener implements ElasticJobListener {
@Override
public void beforeJobExecuted(ShardingContext ctx) {
JobRegistry.register(ctx.getJobName()); // 注册到监控系统
}
@Override
public void afterJobExecuted(ShardingContext ctx) {
JobRegistry.unregister(ctx.getJobName());
}
}
三、分片策略优化方法
大型系统优化技巧:
-
动态分片调整:根据负载自动扩缩容
// API动态调整分片数 CuratorFramework client = CuratorFrameworkFactory.newClient("zk:2181"); client.start(); client.setData().forPath("/config/jobName/shardingTotalCount", "48".getBytes()); -
热点分片检测算法:
// 基于处理时间的动态权重分配 Map<Integer, Long> shardProcessTime = getShardMetrics(); double avgTime = shardProcessTime.values().average(); for (Entry<Integer, Long> entry : shardProcessTime.entrySet()) { double weight = entry.getValue() / avgTime; adjustShardWeight(entry.getKey(), weight); // 降低热点分片权重 } -
虚拟分片技术:
// 物理分片10个,虚拟分片1000个 int virtualShards = 1000; for (long userId : trillionUserIds) { int virtualShard = (userId.hashCode() & Integer.MAX_VALUE) % virtualShards; int physicalShard = virtualShard % actualNodeCount; // 映射到物理节点 processUser(userId, physicalShard); }
四、跨数据中心调度实现
架构方案:
关键技术:
- 全局命名服务:通过 DNS 或负载均衡器实现注册中心跨域访问
- 分片路由策略:
public class CrossDCSharding implements JobShardingStrategy { @Override public Map<JobInstance, List<Integer>> sharding(...) { // 根据数据中心标签分配分片 if (shardId < 1000) { assignToDC("beijing", shardId); } else { assignToDC("shanghai", shardId); } } } - 数据同步:使用 Debezium 或 Kafka Connect 实现跨域数据同步
五、与 Kubernetes 集成
协同工作机制:
关键集成点:
-
Operator 部署模式:
# Elastic-Job Operator CRD apiVersion: elasticjob.io/v1 kind: ElasticJob metadata: name: user-profile-job spec: replicas: 0 # 由Elastic-Job控制 jobClass: com.example.UserDataJob shardingTotalCount: 100 zookeeperServers: "zk-cluster:2181" -
自动扩缩容策略:
// 根据分片负载动态调整Pod数量 int requiredPods = Math.ceil(totalShards / shardsPerPod); KubernetesClient client = new DefaultKubernetesClient(); client.apps().deployments() .inNamespace("prod") .withName("ej-worker") .scale(requiredPods); // 触发HPA
六、万亿级数据分片策略
突破分片上限方案:
-
分层分片架构:
用户ID → 虚拟桶(100万桶) → 物理分片(10万节点) -
动态分片映射表:
// 使用分布式缓存存储分片映射 Map<Long, Integer> shardMap = new DistributedCacheMap<>(); for (long userId : userIds) { int shard = userId % VIRTUAL_SHARD_COUNT; if (!shardMap.contains(userId)) { shardMap.put(userId, shard % currentPhysicalShards); } processUser(userId, shardMap.get(userId)); } -
分片分裂算法:
// 当单个分片数据超过阈值时分裂 if (shardDataSize > MAX_SHARD_SIZE) { int newShardId = createNewShard(); migrateData(oldShardId, newShardId, dataRange); updateShardMapping(oldShardId, newShardId); }
性能公式:
理论处理能力=单节点TPS平均数据密度×节点数×虚拟分片因子 \text{理论处理能力} = \frac{\text{单节点TPS}}{\text{平均数据密度}} \times \text{节点数} \times \text{虚拟分片因子} 理论处理能力=平均数据密度单节点TPS×节点数×虚拟分片因子
七、Kubernetes 部署实践
Helm 部署模板:
# values.yaml
zookeeper:
replicaCount: 3
persistence:
enabled: true
elasticjob:
controller:
image: elasticjob/controller:v3.0
worker:
replicas: 0 # 初始无worker
autoscaler:
enabled: true
maxReplicas: 1000
metrics:
- type: External
external:
metricName: "shards_pending"
targetValue: 5
分片策略设计:
public class UserLocalitySharding implements JobShardingStrategy {
@Override
public Map<JobInstance, List<Integer>> sharding(...) {
// 根据用户地理位置分配分片
Map<String, List<JobInstance>> dcNodes = groupByDatacenter(instances);
for (int shard = 0; shard < shardingTotalCount; shard++) {
String region = getUserRegion(shard); // 根据分片ID推导地域
JobInstance target = selectLowestLoad(dcNodes.get(region));
assignShard(target, shard);
}
}
}
数据本地化优化:
思维导图

















 1190
1190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









