




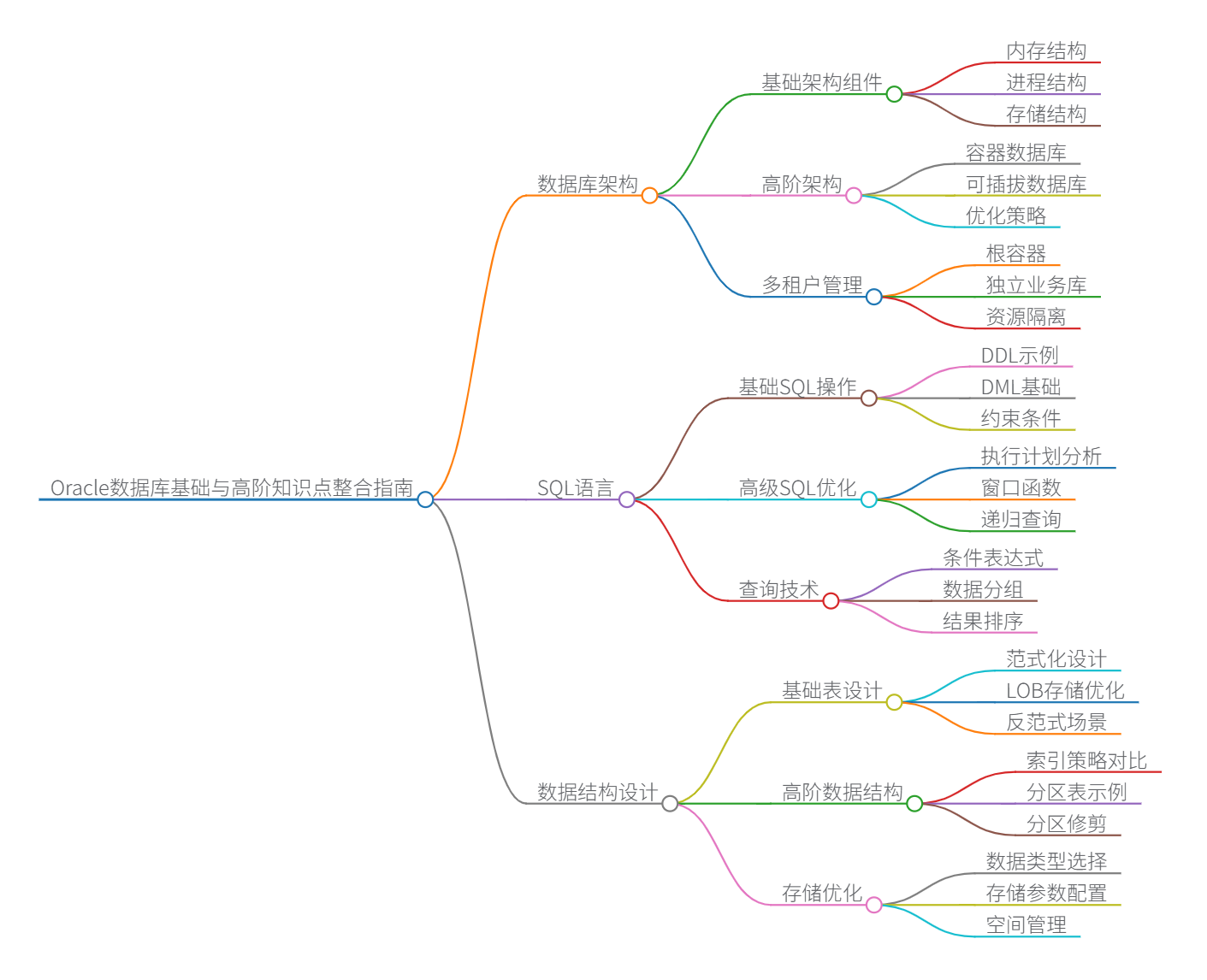
Oracle数据库基础与高阶知识点整合指南
本文系统整合Oracle 19c数据库的核心知识体系,涵盖基础架构、SQL优化、数据结构设计及19c新特性,形成阶梯式学习路径。所有内容基于Oracle官方文档及行业最佳实践,确保技术准确性。
一、数据库架构:从基础到高阶
1. 基础架构组件
-
内存结构
- SGA(系统全局区):
SGAsize=db_cache_size+shared_pool_size+log_buffer \text{SGA}_{\text{size}} = \text{db\_cache\_size} + \text{shared\_pool\_size} + \text{log\_buffer} SGAsize=db_cache_size+shared_pool_size+log_buffer
共享池缓存SQL解析结果,减少硬解析频率;数据库缓冲区存储热数据块;重做日志缓冲区确保事务持久性。 - PGA(程序全局区):会话私有内存,处理排序(
SORT_AREA_SIZE)和哈希连接。
- SGA(系统全局区):
-
进程结构
- 关键进程:
PMON:清理异常会话DBWn:脏数据块写入磁盘LGWR:日志写入(优先于DBWn,满足Write-Ahead Logging原则)
- 关键进程:
-
存储结构
逻辑结构 物理结构 关联关系 表空间(Tablespace) 数据文件(.dbf) 一个表空间含多个文件 段(Segment) 控制文件(.ctl) 记录数据库元数据 区(Extent) 重做日志文件(.log) 事务恢复关键
2. 高阶架构:多租户(CDB/PDB)
- 容器数据库(CDB):根容器(
CDB$ROOT)管理公共资源 - 可插拔数据库(PDB):独立业务库,共享CDB进程与内存
优化策略:CREATE PLUGGABLE DATABASE sales_pdb ADMIN USER admin IDENTIFIED BY password;- 资源隔离:通过PDB级
RESOURCE_MANAGER_PLAN限制CPU/I/O - 存储分离:热数据存SSD,冷数据存HDD
- 资源隔离:通过PDB级
二、SQL语言:从基础语法到高级优化
1. 基础SQL操作
- DDL示例:
CREATE TABLE employees ( id NUMBER PRIMARY KEY, name VARCHAR2(50) NOT NULL, salary NUMBER CHECK(salary >= 0) -- 约束条件 ); - DML基础:
UPDATE employees SET salary = salary * 1.1 WHERE dept_id = 10;
2. 高级SQL优化技术
-
执行计划分析:
EXPLAIN PLAN FOR SELECT * FROM orders WHERE order_date > SYSDATE-30; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);关键指标:
COST:优化器预估资源消耗ROWS:返回行数估值ACCESS_PREDICATES:索引使用条件
-
窗口函数实战:
-- 计算部门内薪资排名 SELECT dept_id, name, salary, RANK() OVER (PARTITION BY dept_id ORDER BY salary DESC) AS dept_rank FROM employees; -
递归查询:
WITH org_tree (employee_id, manager_id, level) AS ( SELECT employee_id, manager_id, 1 FROM employees WHERE manager_id IS NULL UNION ALL SELECT e.employee_id, e.manager_id, ot.level + 1 FROM employees e JOIN org_tree ot ON e.manager_id = ot.employee_id ) SELECT * FROM org_tree;
三、数据结构设计:基础表到高级分区
1. 基础表设计原则
-
范式化设计:
- 第一范式(1NF):列原子性
- 第二范式(2NF):消除部分依赖
- 第三范式(3NF):消除传递依赖
反范式场景:数据仓库星型模型(牺牲存储换查询性能)
-
LOB存储优化:
CREATE TABLE documents ( id NUMBER, doc_content CLOB ) LOB(doc_content) STORE AS SECUREFILE (COMPRESS HIGH ENABLE STORAGE IN ROW);
2. 高阶数据结构优化
-
索引策略对比:
索引类型 适用场景 19c增强 B-Tree 高基数列(如ID) 支持降序索引 位图索引 低基数列(如性别) 自动维护 函数索引 条件含表达式 支持JSON路径索引 -
分区表示例:
CREATE TABLE sales ( region VARCHAR2(20), sale_date DATE ) PARTITION BY LIST (region) SUBPARTITION BY HASH (sale_date) SUBPARTITIONS 8;分区修剪(Partition Pruning):查询时仅访问相关分区,减少I/O 90%+
四、Oracle 19c核心新特性
1. 自动化管理
- 自动索引:
后台自动分析负载,创建/删除索引,重建失效索引。EXEC DBMS_AUTO_INDEX.CONFIGURE('AUTO_INDEX_MODE','IMPLEMENT'); - 自适应执行计划:运行时根据实际数据分布调整连接方式(Nested Loop → Hash Join)
2. 高可用增强
- Data Guard Far Sync:零数据丢失(Zero Data Loss)异地容灾
- RAC One Node:单节点部署低成本高可用方案
3. 性能诊断工具
- AWR报告关键指标:
DB Time:数据库总负载Top SQL by Elapsed Time:需优化SQLI/O Profile:存储瓶颈分析
生成命令:@?/rdbms/admin/awrrpt.sql
五、学习路径与实战环境
环境推荐:
- 本地开发:
- Oracle官方虚拟机(19c + 示例库)
- Docker:
docker pull container-registry.oracle.com/database/express:19c
- 云环境:
- Oracle Always Free Tier(20GB免费存储)
- AWS RDS Oracle(BYOL许可)
关键原则:
- 所有实验在非生产环境进行
- 表空间预留30%扩展空间
- 绑定变量避免硬解析:
SELECT * FROM users WHERE id = :id
六、性能优化黄金法则
- I/O最小化:通过索引减少物理读(逻辑读:物理读 ≤ 1:10)
- 内存最大化:缓冲命中率 ≥ 90%
Buffer Hit Ratio=1−physical readsdb block gets + consistent gets \text{Buffer Hit Ratio} = 1 - \frac{\text{physical reads}}{\text{db block gets + consistent gets}} Buffer Hit Ratio=1−db block gets + consistent getsphysical reads - 19c自动化:启用自适应执行计划与自动索引
思维导图

















 9435
9435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









