



1 Cassandra集群备份
1.1 概述
每个节点存储了完整数据的一部分。
查看node1节点的数据
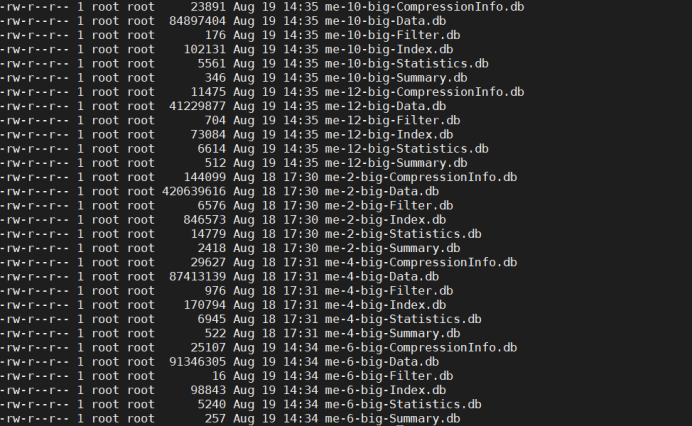
查看node2节点的数据
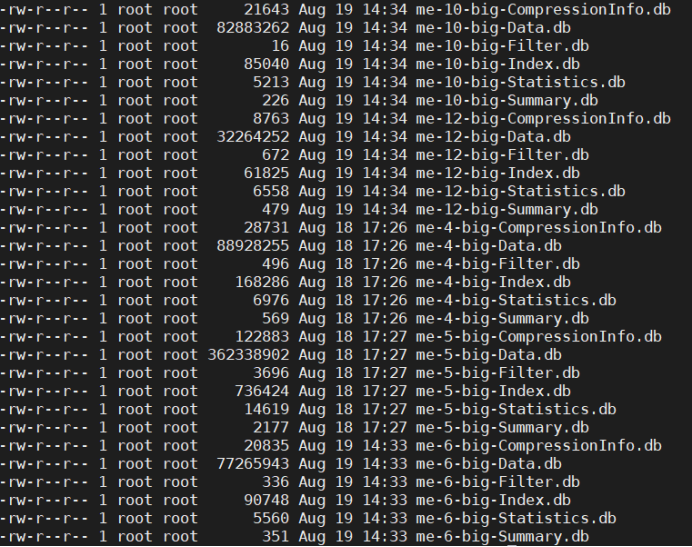
查看node3节点的数据
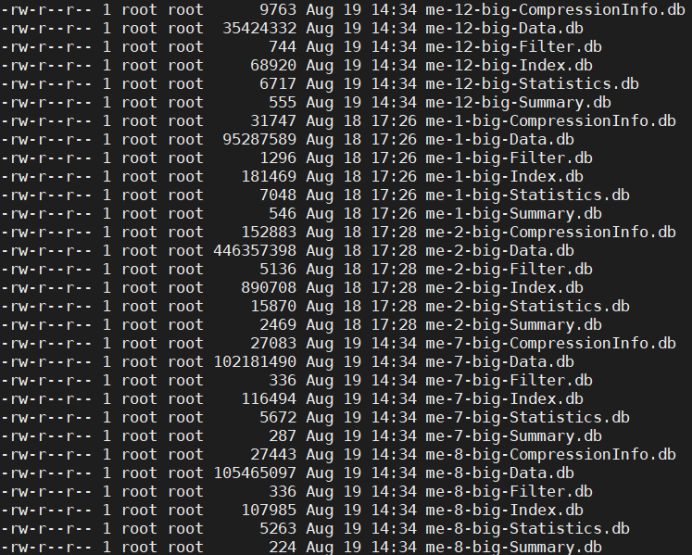
会发现三个节点的数据文件命名是相互隔离的,如果拷贝到一个目录下肯定会出现数据覆盖现象。
1.2 物理备份
每个节点执行命令
./nodetool snapshot -t 20240815 school
备份的school的表的数据都存储在${data_file_directories}/school/表名-uuid/snapshots/20240815/数据
如果data_file_directories没有在配置文件中配置,默认为Cassandra的家目录/data
这样会在每个节点生成当前节点的备份文件
1.3 使用COPY备份数据
略
2 Cassandra集群恢复
2.1 单机迁移集群
2.1.1 物理恢复法
将单机所有的数据恢复到集群一个节点
提前创建好keyspace和table
replication = {'class': 'SimpleStrategy', 'replication_factor': '1'} AND durable_writes = true;
直接将备份数据拷贝到单个节点的keyspace/table目录下
将数据复制到单个节点的${data_file_directories}/keyspace_name/table_name-uuid/下面
执行命令刷新数据:
./nodetool refresh keyspace_name table_name
数据存储结果:当前node节点全量数据,另外两个节点${data_file_directories}/keyspace_name/table_name-uuid/目录下为空
数据可以正常查询
2.1.2 sstableloader导入集群
将单机所有数据分散到集群所有可用节点
使用命令导入集群
/app/module/cassandra/bin/sstableloader --nodes 192.168.137.141,192.168.137.142 -u cassandra -pw 123456 /data/keyspace_name/table_name
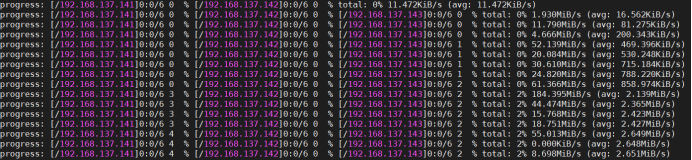

- 配置的--nodes 192.168.137.141,192.168.137.142,导入过程中依旧会根据集群中的所有节点,进行数据导入。
- 数据导入过程并不是均匀分配的数据。
- 数据导入完成以后,三个节点的数据大小加起来约等于备份的数据,也就是三个节点凑一起是一份完整数据。
2.2 集群迁移到新集群
2.2.1 新集群节点多
新集群节点大于等于旧集群节点情况下。
直接将每个节点的数据,拷贝到新的节点对应的目录下,然后刷新数据
./nodetool refresh keyspace_name table_name
2.2.2 新集群节点少
新集群节点小于等于旧集群节点情况下。
1、先将每个节点的数据,拷贝到新的节点对应的目录下,然后刷新数据
./nodetool refresh qingchen_test02 qingchen_table
2、多出来的节点数据,使用sstableloader导入到集群
/app/module/cassandra/bin/sstableloader --nodes 192.168.137.141,192.168.137.142 -u cassandra -pw 123456 /tmp/qingchen_test02/qingchen_table/

2.2.3 sstableloader导入集群
将节点备份数据,分批次导入到集群
/app/module/cassandra/bin/sstableloader --nodes 192.168.137.141,192.168.137.142 -u cassandra -pw 123456 /app/qingchen_test03/qingchen_table/
数据会优先导入到当前节点,如果数据量大,依旧会平摊到其他节点。
2.3 Cassandra恢复特殊情况
2.3.1 sstableloader重复导入一个备份
- 执行命令重复导入同一份备份,命令行不会报错。
- 还导入到和第一次导入相同的节点。
- 数据文件目录大小会翻倍。
- 可以正常查询。
- 日志没有报错。
3 Cassandra集群数据查询
数据查询过程中,当宕机节点超过节点一半以上时,集群无法进行查询操作
"Cannot achieve consistency level QUORUM"


















 6881
6881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









