



节点规划
集群共采用4个节点,其中3个RabbitMQ节点、1个HaProxy节点。
这里使用HaProxy来实现对RabbitMQ的负载均衡和可扩展性。虽然可以再加KeepAlived实现对HaProxy节点的高可用,不过我电脑资源有限,KeepAlived也比较简单,对测试验证没有太大影响,就不加了。
主机名 | IP地址 | 角色 |
gw14 | 172.31.2.14 | RabbitMQ集群节点 |
gw15 | 172.31.2.15 | RabbitMQ集群节点 |
gw16 | 172.31.2.16 | RabbitMQ集群节点 |
gw17 | 172.31.2.17 | HaProxy节点 |
设置hosts
RabbitMQ节点使用了主机名来相互访问,因此需要互相能解析彼此的主机名。由于我的测试VM未使用内网DNS,因此就通过添加hosts这种方式来实现。
编辑/etc/hosts文件,在所有节点上都设置3台RabbitMQ服务器的hosts:
部署RabbitMQ
参考了官网的操作系统兼容性说明后,操作系统使用Debian Bookworm(12.10.0版本),以匹配最新的RabbitMQ和Erlang版本。
在所有节点上,根据 官网文档指引,安装最新的软件版本(Erlang 27、RabbitMQ 4.1)(RabbitMQ调优就不在这里介绍了):
查看RabbitMQ,程序已经启动起来了:
示例截图:
现在,所有节点均是作为独立的RabbitMQ broker节点启动了。
在所有节点上确认集群状态:
示例截图:
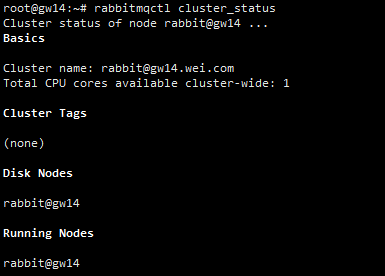
可以看到,节点名称是rabbit@shorthostname这种格式的,其中,shorthostname在Linux系统上取的是主机名的小写。集群中只有1个节点,即节点自身。
设置cookie一致
由于集群节点间通过cookie进行认证,我们需要保持它们的cookie一致。
在gw14节点,拷贝cookie到gw15、gw16节点上,保持文件内容、权限一致:
在gw15节点,重启RabbitMQ:
在gw16节点,重启RabbitMQ:
创建集群
为了让3个节点处于同一个集群,我们告诉其中2个节点,如rabbit@gw15、rabbit@gw16,加入到第3个节点的集群,如rabbit@gw14。在节点加入其它集群之前,必须先将它重置(reset)。重置节点会移除节点上的所有数据。
在gw15节点上,进行如下操作:
在gw16节点上,操作与上面是一样的,除了这次我们让节点加入rabbit@gw15节点所在的集群。这是为了演示加入集群时使用现有集群中的任意节点都是可以的。
然后在任一节点查看集群状态,可查看到集群中有3个节点,集群组建成功:
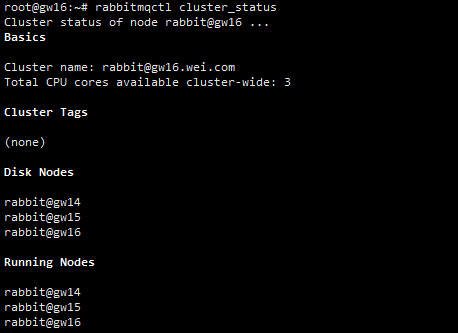
部署HaProxy
操作系统使用Debian12.10,根据HaProxy 官网文档指引,安装HaProxy 3.0版本:
备注1:在安装HaProxy的时候会提示缺少依赖libopentracing-c-wrapper0,其实不单这个,还缺少很多依赖软件。按照Debian 官网指引,可在/etc/apt/sources.list文件中添加如下apt源,执行apt-get update,再安装HaProxy。
备注2:安装过程中会涉及重新安装/重启openssh、cron服务等,请注意。
设置HaProxy配置文件/etc/haproxy/haproxy.cfg:
重载配置:
客户端访问集群(Quorum Queues)
消息消费基本能力验证
从RabbitMQ 4.0开始,已不再支持经典队列(Classic queue)镜像。对于新版本RabbitMQ,若要使用可复制的、高可用的数据结构,应选择使用仲裁队列(Quorum Queues)或流(Streams)。仲裁队列适用于对数据安全性要求高、对消息即时性和消息延迟没那么高要求的场景。
仲裁队列(Quorum Queues)是一种可持久化的、可复制的队列,基于Raft共识算法。当使用仲裁队列时,如果集群有N个节点,那么至少需要有(N/2)+1个节点可用才能保证整个集群的可用性。但是,默认的仲裁队列副本数为3,即便集群节点数大于3时。
RabbitMQ支持好几个客户端协议,我们这里使用通用的AMQP 0-9-1协议来访问RabbitMQ。在IDE中创建2个maven项目,分别用作生产者和消费者。
在项目的pom文件中添加RabbitMQ客户端库、SLF4J API、SLF4J Simple这几个依赖:
在生产者项目中,编写生产者程序EmitLog.java:
在消费者项目中,编写消费者程序ReceiveLogs.java:
要创建一个仲裁队列,最关键的就是在声明队列时,要将x-queue-type参数的值设为quorum。
运行消费者程序后,登录到RabbitMQ管理后台,可看到队列类型为quorum(即仲裁队列),并且队列存在于3个节点上,这与经典队列(classic queue)只存在于1个节点上是不相同的:
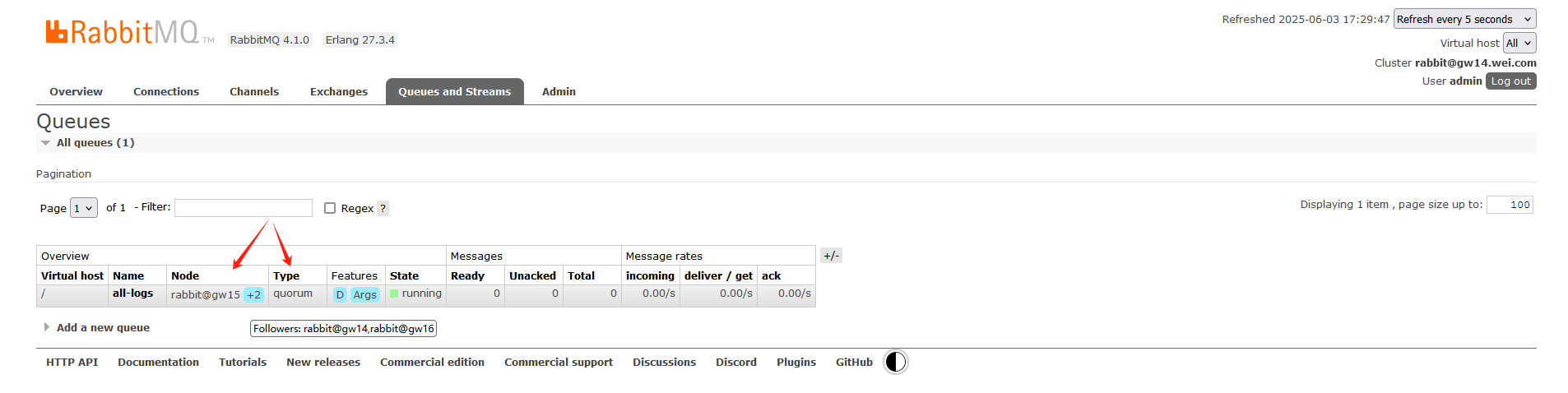
点击队列名称进入队列详情界面,还可看到队列当前的Leader节点:
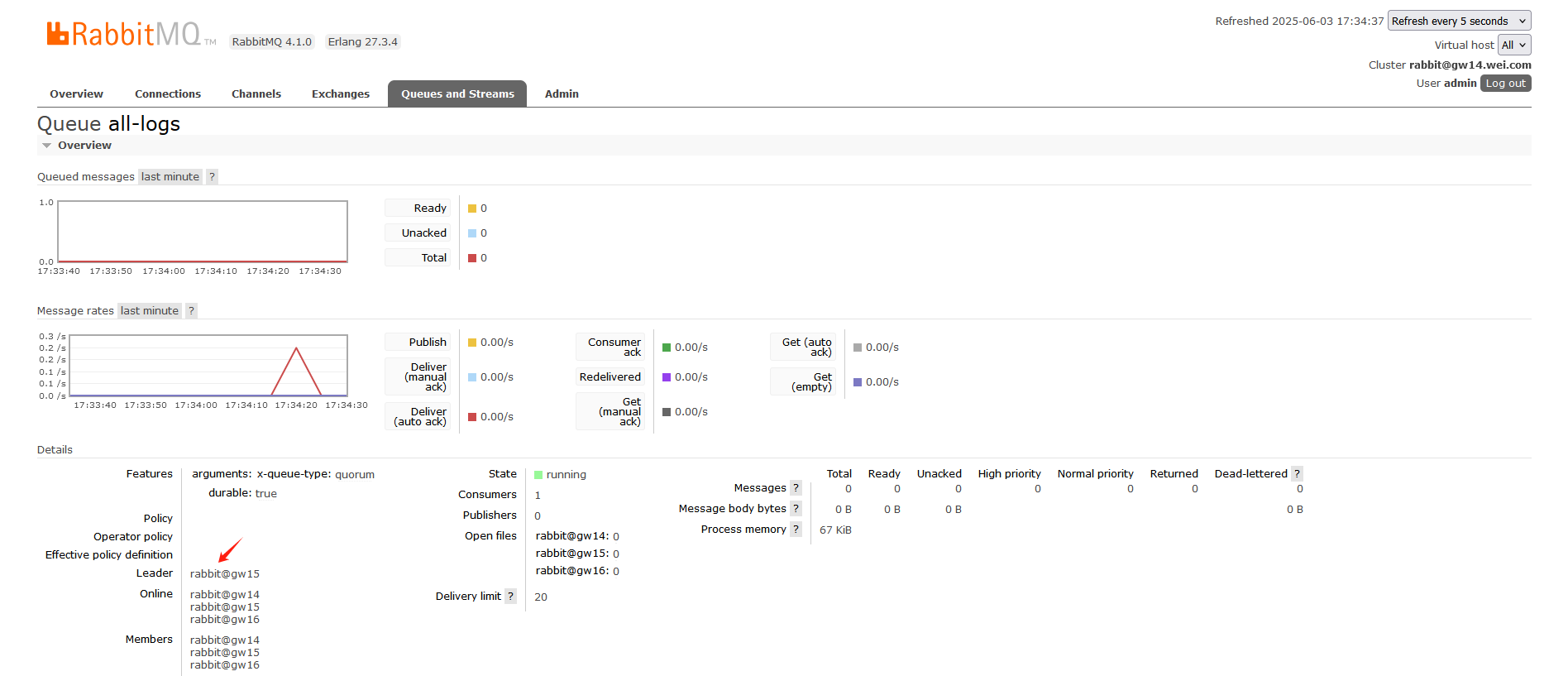
运行生产者程序后,消费者程序能正常收到消息:

由此可见,使用RabbitMQ集群时,消息消费基本能力正常。
集群可用性验证
当前集群有3个RabbitMQ节点,为了保证仲裁队列的可用性,最多可以有1个节点不可用。本小节验证下是否如此。
1)停掉1个节点,预期仲裁队列仍然可用。
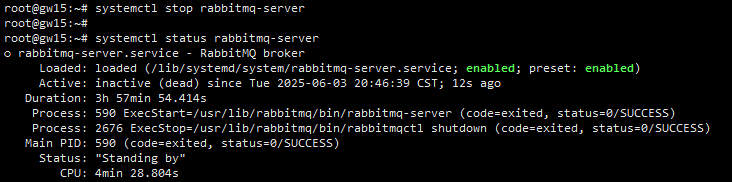
我这里选择停掉仲裁队列当前的Leader节点。登录到gw15节点,停掉RabbitMQ实例:
截图:
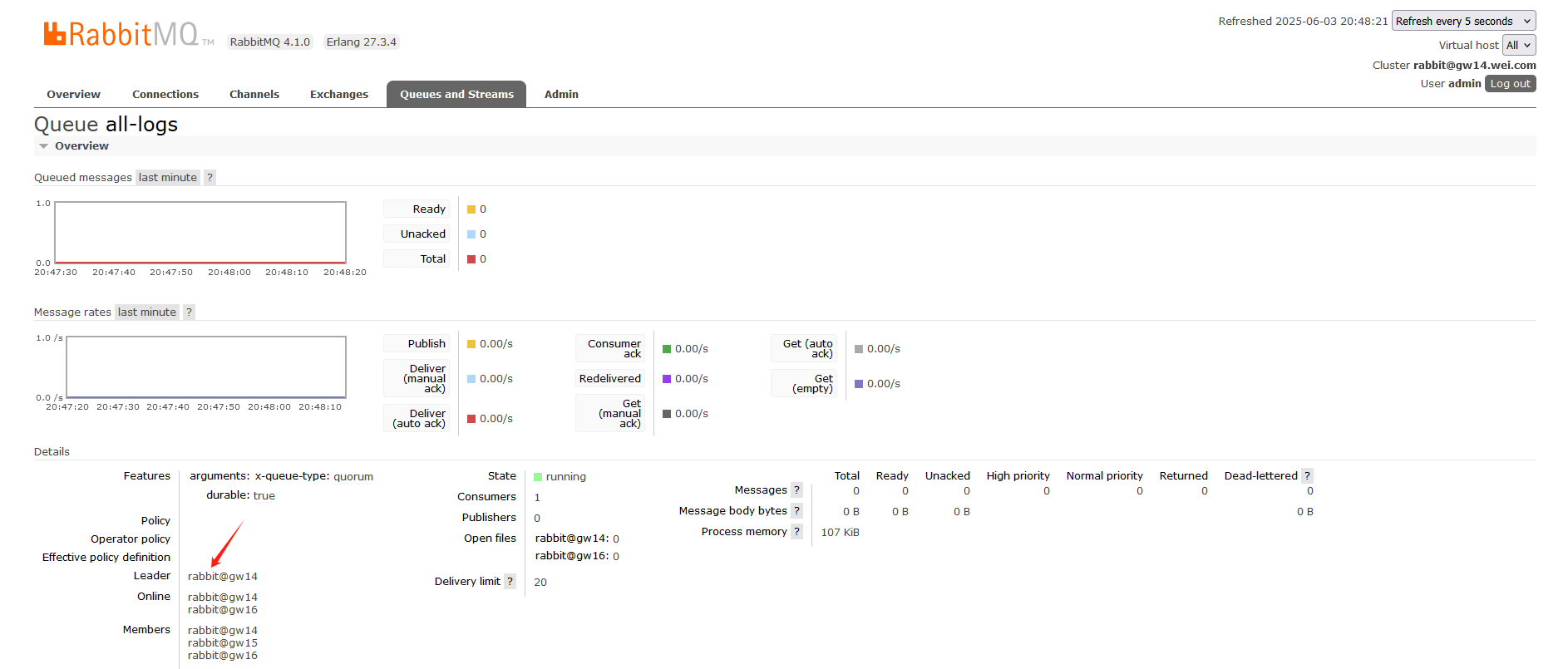
停掉gw15节点后,可观察到队列的Leader节点变了:
消费者程序先前经haproxy连到了gw15节点,当gw15节点上的RabbitMQ实例停掉后,消费者程序自动重连到了其它节点。生产者发送的消息,消费者程序能正常收到:

可见,停掉1个节点时,仲裁队列仍然可用,符合预期。
2)停掉2个节点,预期仲裁队列不可用。
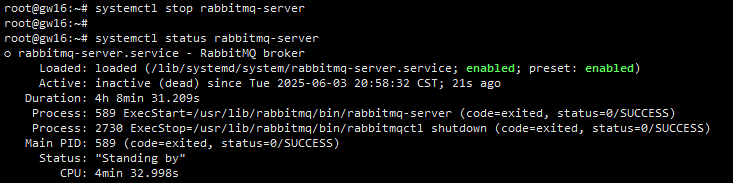
继续前面的操作,登录到gw16节点,将其RabbitMQ实例也停掉:
截图:
停掉2个节点后,仲裁队列状态由running变为了minority:
此时,生产者程序发送消息后在关闭连接时最终报错了:
RabbitMQ服务端实际将生产者发送的消息丢弃了,消费者程序也未收到消息:

可见,停掉2个节点时,仲裁队列不可用,符合预期。
3)恢复所有节点后,仲裁队列恢复正常。
继续前面的操作,将gw15、gw16节点的RabbitMQ实例都启动:
此时,仲裁队列的状态重新变为了running:
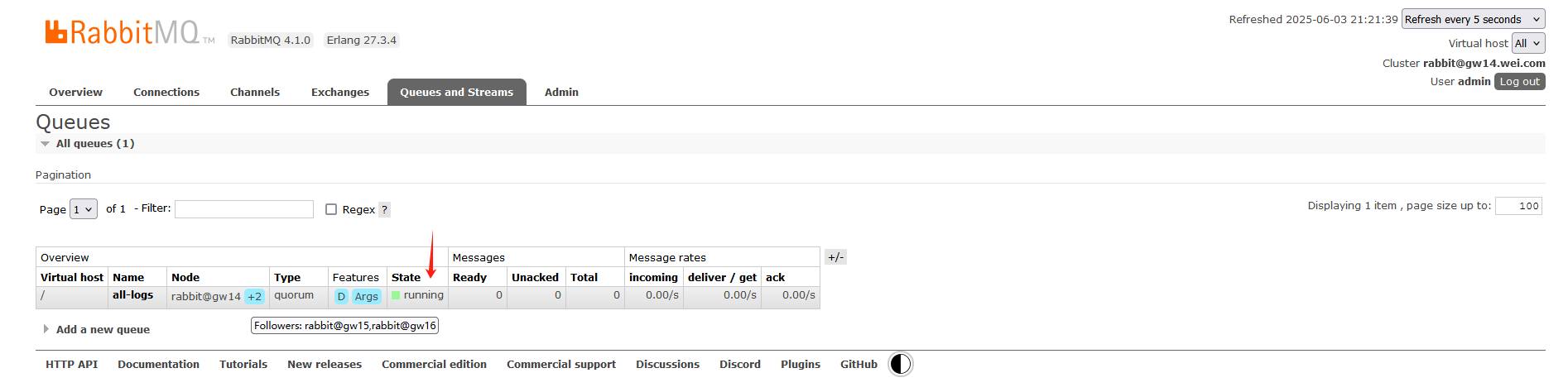
生产者发送的消息,消费者可正常收到:
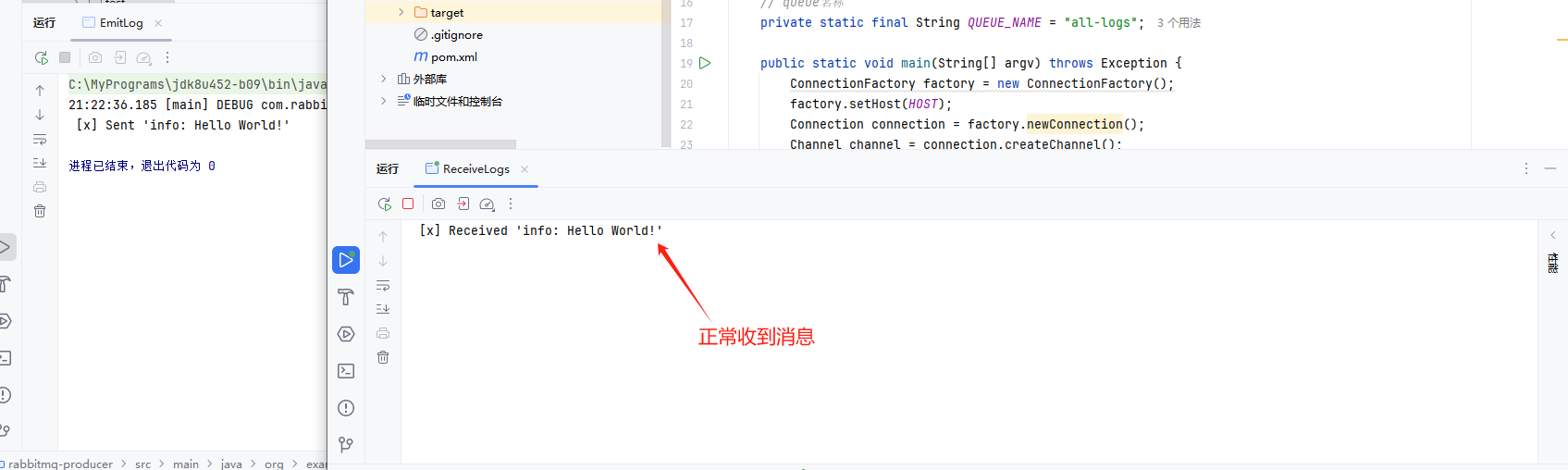
如上验证所示,使用HaProxy+RabbitMQ集群这种架构,可以保证仲裁队列的高可用,验证通过。

















 3289
3289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









