



在大数据时代,数据就像血液,在不同的系统间流动。我们常常需要将关系型数据库(如MySQL)中的业务数据,迁移或同步到分布式文件系统(如HDFS)中,以便进行更深层次的数据分析或与大数据生态中的其他工具(如Hive、HBase)进行集成。
今天,我们就来手把手教你如何使用强大的ETL(抽取-转换-加载)工具 Kettle(Pentaho Data Integration, PDI)8.3,将MySQL数据库中的数据轻松导入到HDFS。整个过程可视化操作,无需编写复杂的代码,即便你是初学者也能快速上手!
核心概念速览
在开始之前,我们先简单了解几个核心概念:
- Kettle (Pentaho Data Integration, PDI):一个开源的数据集成工具,以其强大的ETL能力和直观的可视化界面而闻名。你可以通过拖拽组件、连线、配置参数,实现复杂的数据流处理。
- MySQL:一种广泛使用的开源关系型数据库管理系统,常用于存储业务数据。
- HDFS (Hadoop Distributed File System):Hadoop生态系统的核心组件之一,一个高容错、高吞吐量的分布式文件系统,专为大规模数据存储和处理而设计。它是大数据存储的基石。
- 转换 (Transformation):在Kettle中,一个“转换”定义了数据从源到目标的流向和处理逻辑。它由一系列相互连接的步骤(组件)组成。
准备工作
在开始之前,请确保你已经:
- 安装并成功运行了 Kettle 8.3。
- 有一个可访问的 MySQL 数据库,其中包含你需要导出的数据(本文以 test123 数据库中的 emp 表为例)。
- 有一个可访问的 Hadoop 集群,并且Kettle能连接到它。
步骤详解
1. 创建一个新的Kettle转换
首先,打开Kettle Spoon客户端。
在左侧的“核心对象”树中,找到并右键点击“转换”,选择“新建转换”,或者点击菜单栏的“文件” -> “新建” -> “转换”。这将打开一个新的空白画布,我们所有的数据流逻辑都将在这里构建。
2. 配置MySQL数据库连接与数据抽取
我们需要告诉Kettle从哪个MySQL数据库中读取数据。
- 添加“表输入”组件:
- 在左侧的“核心对象”树中,展开“输入”类别,找到“表输入”组件。
- 将其拖拽到转换画布上。
- 双击画布上的“表输入”组件,进入其配置界面。
- 配置数据库连接:
- 在“表输入”组件配置界面中,点击“新建”按钮,创建一个新的数据库连接。
- 连接名称: 随意填写,例如 hadoop01_mysql (便于识别)。
- 连接类型: 选择 MySQL。
- 访问方式: 选择 Native (JDBC)。JDBC(Java Database Connectivity)是Java语言连接数据库的标准接口。
- 主机名: 填写你的MySQL服务器IP地址,例如 10.10.170.11。
- 数据库名称: 填写你要连接的数据库名,例如 test123。
- 端口号: 填写MySQL默认端口 3306。
- 用户名和密码: 填写你的MySQL数据库登录凭据,例如 root 和对应的密码。
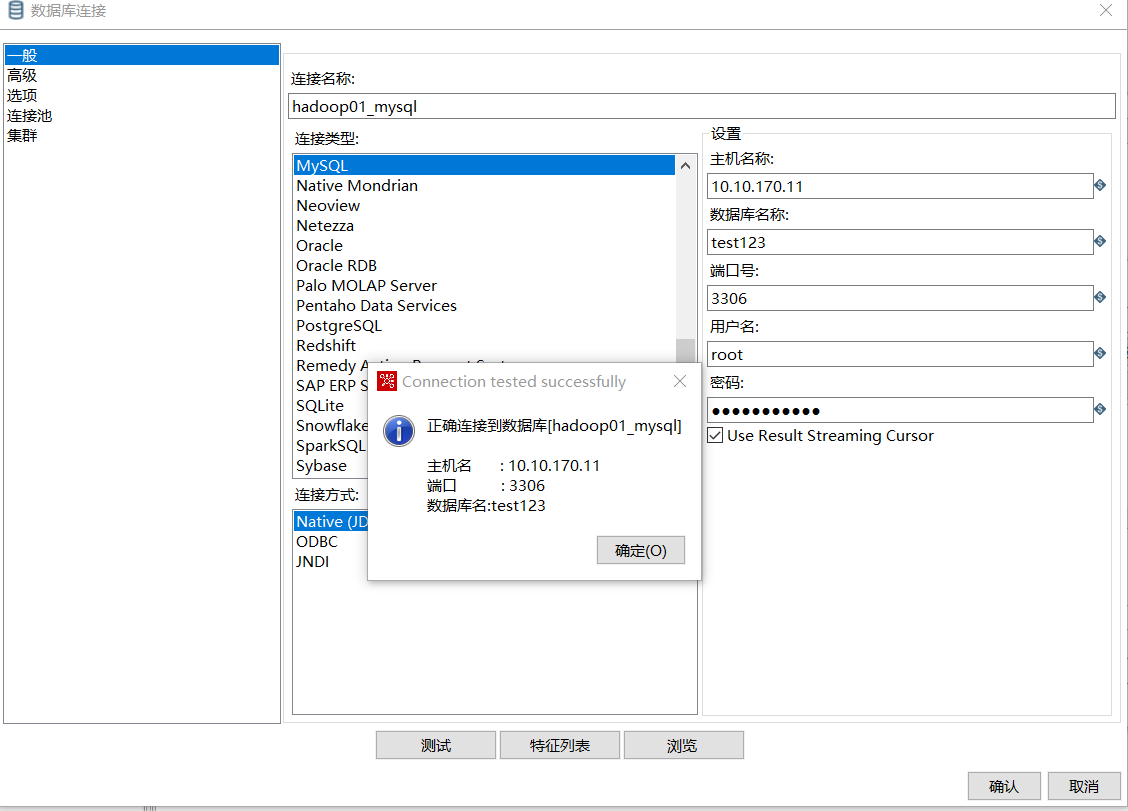
- 填写完毕后,点击“测试”按钮。如果出现“Connection tested successfully”的提示框,恭喜你,数据库连接配置成功!
- 编写SQL查询语句:
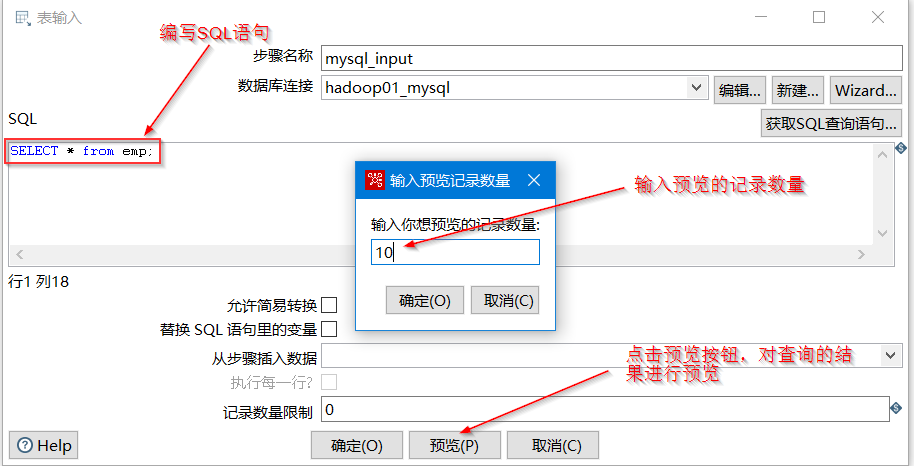
- 回到“表输入”组件配置界面,在“SQL”文本框中,输入你想要从MySQL中抽取数据的SQL语句。例如,我们想抽取 emp 表的所有数据:
- 预览数据: 输入SQL语句后,点击下方的“预览”按钮。Kettle会弹出一个窗口,询问你想要预览多少条记录(输入10即可)。点击“确定”后,Kettle会执行SQL并显示前几条数据。如果能看到正确的查询结果,说明你的SQL语句和连接都配置无误。
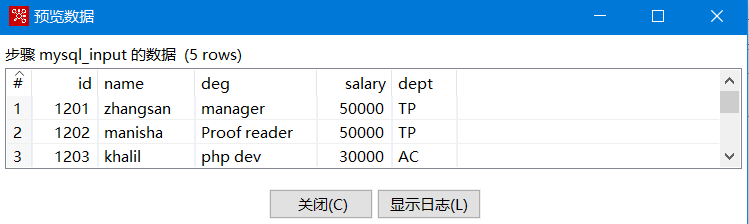
看到数据预览成功,说明数据源的配置已经完全就绪,可以点击“确定”关闭“表输入”组件配置。
3. 添加Hadoop文件输出组件并建立关联
接下来,我们需要指定数据要写入HDFS的目标。
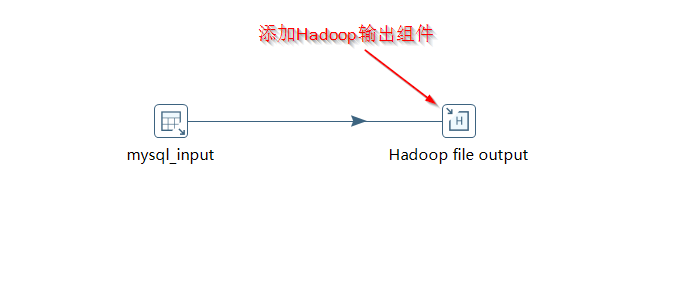
- 添加“Hadoop文件输出”组件:
- 在左侧的“核心对象”树中,展开“输出”类别,找到“Hadoop文件输出”组件。
- 将其拖拽到转换画布上。
- 建立数据流关联:
- 按住键盘的 Shift 键,用鼠标从“表输入”组件拖拽一条连线到“Hadoop文件输出”组件。这条线表示数据将从“表输入”流向“Hadoop文件输出”。
4. 配置Hadoop文件输出组件
双击画布上的“Hadoop文件输出”组件,进入其配置界面。
- “文件”选项卡:
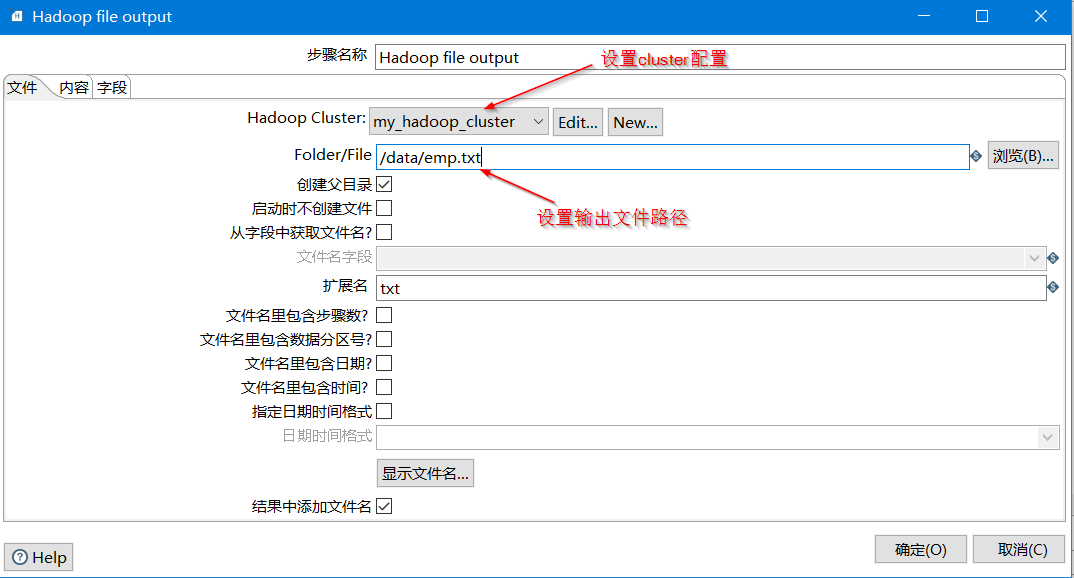
- 步骤名称: Hadoop file output (默认即可)。
- Hadoop Cluster: 选择你已经配置好的Hadoop集群,例如 my_hadoop_cluster。如果你还没有配置,可能需要点击“编辑”或“新建”按钮进行配置(通常包括NameNode地址、Port等,Kettle会自动查找Hadoop配置文件)。
- Folder/File: 这是数据在HDFS上的目标路径和文件名。例如,输入 /data/emp.txt。这意味着数据将写入HDFS的 /data 目录下,文件名为 emp.txt。
- 创建目录: 勾选此项,如果HDFS上的 /data 目录不存在,Kettle会自动创建。
- 扩展名: 填写 txt。
- “内容”选项卡:
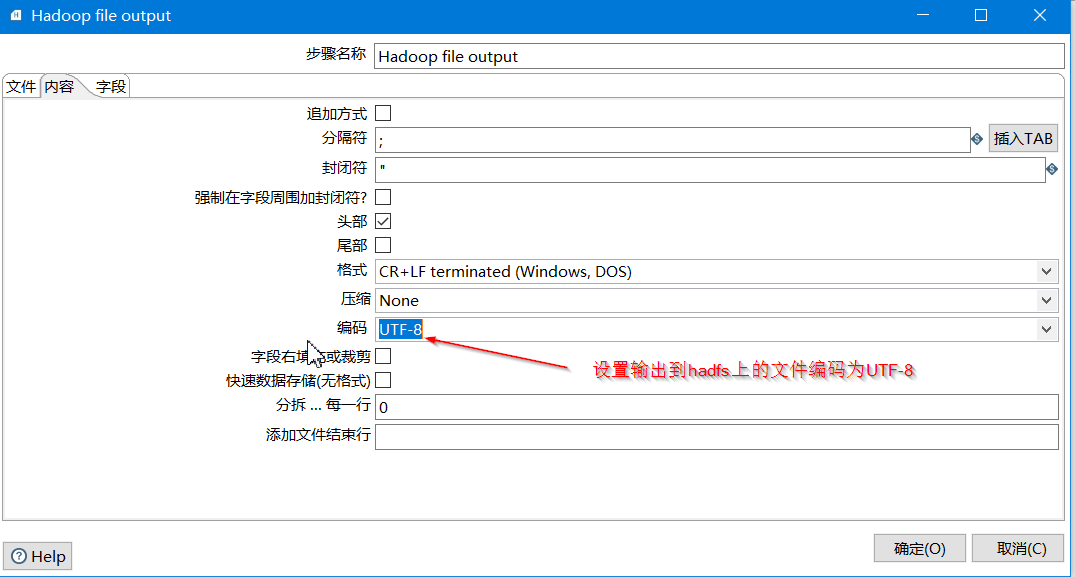
- 在这里,我们可以定义输出文件的格式,例如字段分隔符、编码等。
- 编码: 这一项非常重要,请务必设置为 UTF-8。这能确保MySQL中包含中文或其他非ASCII字符的数据在写入HDFS时不会出现乱码。
配置完成后,点击“确定”关闭“Hadoop文件输出”组件配置。
5. 运行测试
现在,所有的配置都已完成,我们可以运行这个转换来测试它是否能正常工作。
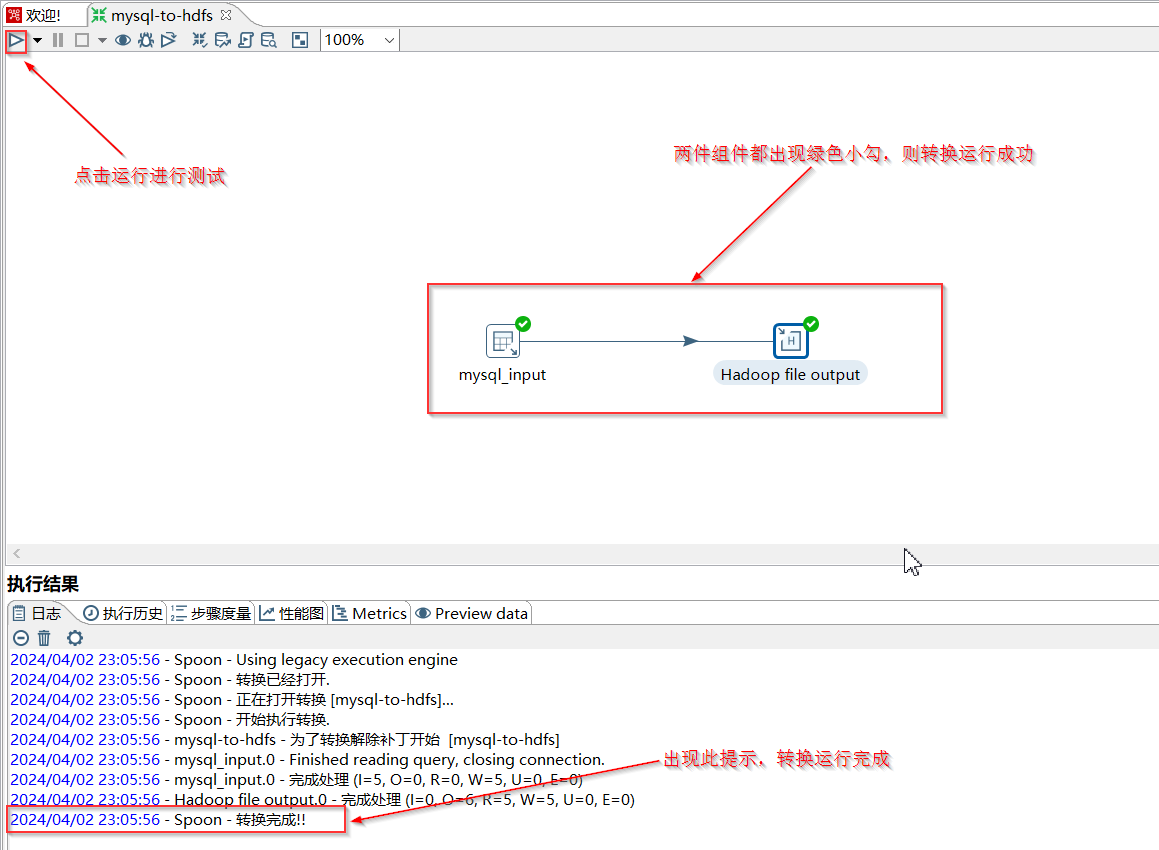
- 点击运行按钮:
- 在Kettle界面的上方工具栏,找到并点击绿色的“运行”按钮(类似于播放键)。
- Kettle会弹出一个“运行转换”对话框,直接点击“运行”即可。
- 观察执行日志和组件状态:
- Kettle会开始执行转换。你可以在“执行结果”窗口的“日志”选项卡中看到详细的运行日志。
- 同时,观察画布上的“表输入”和“Hadoop文件输出”组件。如果它们都出现了绿色的勾选标记,并且日志中显示“转换完成!”,那么恭喜你,数据已成功从MySQL传输到了HDFS!
6. 检测运行结果
为了最终确认数据是否真的写入了HDFS,我们需要连接到Hadoop集群进行验证。
- 登录Hadoop集群终端:
- 使用SSH工具连接到你的Hadoop集群的任意一个节点。
- 查看HDFS目录和文件:
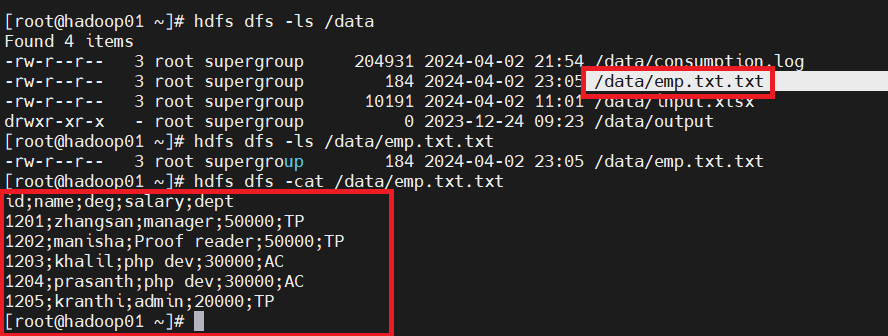
- 在终端中执行HDFS命令,查看 /data 目录下的文件列表:
你应该能看到 emp.txt 文件。
- 接着,查看 emp.txt 文件的内容,验证数据是否正确:
如果终端显示的数据与你在Kettle中预览的MySQL数据一致,那么本次数据迁移就大功告成了!
总结与展望
通过以上简单的六个步骤,我们成功地使用Kettle 8.3 将MySQL数据库中的数据抽取并加载到了HDFS分布式文件系统。Kettle作为一款强大的可视化ETL工具,极大地降低了数据集成任务的复杂性,让数据流动变得更加高效便捷。
本次实践我们掌握了:
- 在Kettle中创建和运行一个基本的转换。
- 配置MySQL数据库连接,并使用SQL抽取数据。
- 配置Hadoop文件输出组件,将数据写入HDFS。
- 通过Kettle日志和Hadoop命令行工具验证数据传输结果。
这仅仅是Kettle功能的冰山一角!你可以基于此,进一步探索以下内容,让你的数据集成能力更上一层楼:
- 数据转换与清洗: 在“表输入”和“Hadoop文件输出”之间添加更多的Kettle组件(如“字段选择”、“过滤记录”、“排序记录”、“聚合”等),对数据进行清洗、转换和加工,满足更复杂的数据处理需求。
- 参数化与变量: 学习如何使用变量和参数,让你的转换更加灵活,例如动态指定输入表名或输出HDFS路径。
- 定时任务: 将Kettle转换部署到调度工具(如Cron、Oozie)中,实现数据的自动化定时同步。
- 错误处理: 学习Kettle的错误处理机制,确保数据流程的健壮性。
- 与其他大数据工具集成: 将HDFS中的数据导入Hive、Spark等工具,进行进一步的数据分析和建模。
希望这篇博客能帮助你更好地理解和使用Kettle,开启你的大数据之旅!如果你在实践过程中遇到任何问题,欢迎留言交流。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









