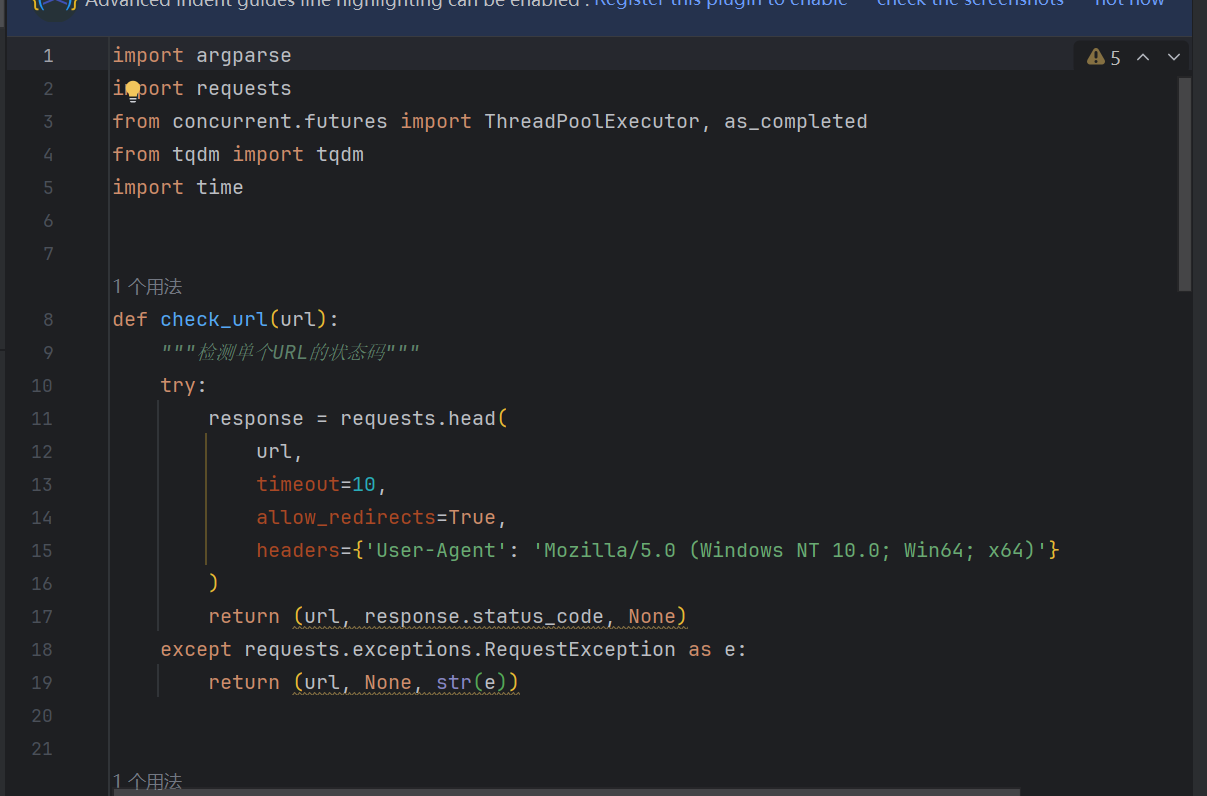
import argparse
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
from tqdm import tqdm
import time
def check_url(url):
"""检测单个URL的状态码"""
try:
response = requests.head(
url,
timeout=10,
allow_redirects=True,
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'}
)
return (url, response.status_code, None)
except requests.exceptions.RequestException as e:
return (url, None, str(e))
def batch_check(urls, max_workers=50):
"""批量检测URL"""
results = []
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = {executor.submit(check_url, url): url for url in urls}
with tqdm(total=len(urls), desc="Processing URLs") as pbar:
for future in as_completed(futures):
result = future.result()
results.append(result)
pbar.update(1)
return results
def main():
parser = argparse.ArgumentParser(description='批量HTTP状态码检测工具')
parser.add_argument('-i', '--input', required=True, help='输入文件路径(包含URL列表)')
parser.add_argument('-o', '--output', default='results.csv', help='输出文件路径')
args = parser.parse_args()
# 读取输入文件
with open(args.input) as f:
urls = [line.strip() for line in f if line.strip()]
# 执行检测
start_time = time.time()
results = batch_check(urls)
# 写入结果
with open(args.output, 'w') as f:
f.write("URL,Status Code,Error\n")
for url, status, error in results:
f.write(f'"{url}",{status if status else ""},"{error if error else ""}"\n')
# 统计结果
success_200 = sum(1 for r in results if r[1] == 200)
success_304 = sum(1 for r in results if r[1] == 304)
total_success = success_200 + success_304
print(f"\n检测完成!耗时:{time.time()-start_time:.2f}s")
print(f"总数量:{len(urls)} | 有效200:{success_200} | 有效304:{success_304} | 总成功率:{total_success/len(urls)*100:.1f}%")
if __name__ == '__main__':
main()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.





















 707
707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









