




 本文详细介绍了如何安装和配置Tesseract OCR引擎及其Python接口Pytesseract,特别关注于解决中文识别问题,并提供了一个简单的代码示例。
本文详细介绍了如何安装和配置Tesseract OCR引擎及其Python接口Pytesseract,特别关注于解决中文识别问题,并提供了一个简单的代码示例。
文本识别学习开始第一天
安装tesseract
查过资料,tesseract是也是一种开源的文本识别库(引擎),就好像OpenCV一样啦,我这次学习是基于Python的,首先安装tesseract。
官网下载非常慢,你们可以试试。tesseract官方下载链接
这里下载的很快,放上链接。版本不太新,够用
下载完是一个exe文件,点击一步步安装就行了。
 和OpenCV一样,需要配置环境变量(因为你需要调用人家里面的函数,方法等)。在系统变量PATH里配置
和OpenCV一样,需要配置环境变量(因为你需要调用人家里面的函数,方法等)。在系统变量PATH里配置
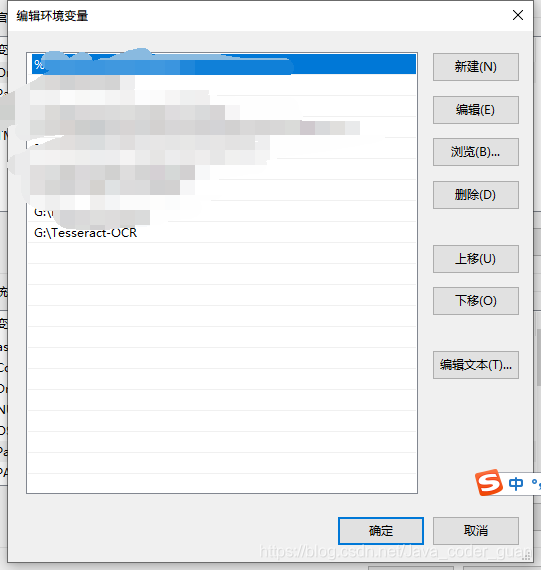
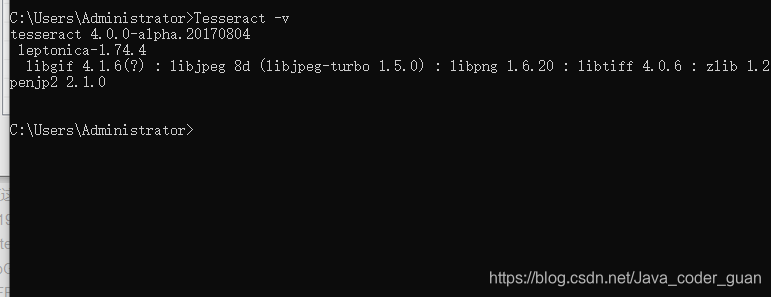
在cmd中测试是否安成功:
输入命令:Tesseract -v
 还需要安装python文本识别的文本识别模块pytesseract
还需要安装python文本识别的文本识别模块pytesseract
在终端用pip install pytesseract 就OK!
原理就是pytesseract 调用tesseract,最终识别文字运用的是tesseract。
以上就算安装完成了。
测试一下
这是用例图片

python代码:
#! -*- coding:utf-8 -*-
from PIL import Image
import pytesseract
image = Image.open(r'C:\Users\Administrator\Pictures\Saved Pictures\ceshi.png')
# image.show(); 显示图片 路径无问题
text = pytesseract.image_to_string(image)
print(text);
测试结果:
 但中文没法识别识别出来
但中文没法识别识别出来
查找方法:
查了网上说是人家是被的库中没有中文识别库,我们需要下载一个中文库,名字是chi_sim.traineddata 将此文件放到tessdata中,名称换成eng.traineddata,覆盖掉原来那个同名的文件,这里放上下载链接。
下载中文字库
改进后的:

测试成功!!

















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









