



前言
在上一篇笔记中学习了解了一部分关于Stable Diffusion的运行原理,今天就来接着学习下Stable Diffusion关于微调训练方面的知识点。
今天没多少废话,因为我下午要去玩PTCG!让我们冲冲冲

整理和输出教程属实不易,觉得这篇教程对你有所帮助的话,可以点击👇二维码领取资料😘

数据集
上一篇笔记里提到过AI是如何“吸收”我们给它的知识,其中便是通过记录图像的像素色块分布然后存储这一特征。
现如今Stable Diffusion作为最炙手可热的AI绘画工具,它的训练规模肯定是极为庞大的。
在最开始的时候,官方的V1.1版本说是用了世界上最大规模的多模态图文数据集LAION-2B来进行训练,其中的B代表着Billion(十亿)。
这个数据集有着约23.2亿对图片和对应文本描述的庞大数据集:
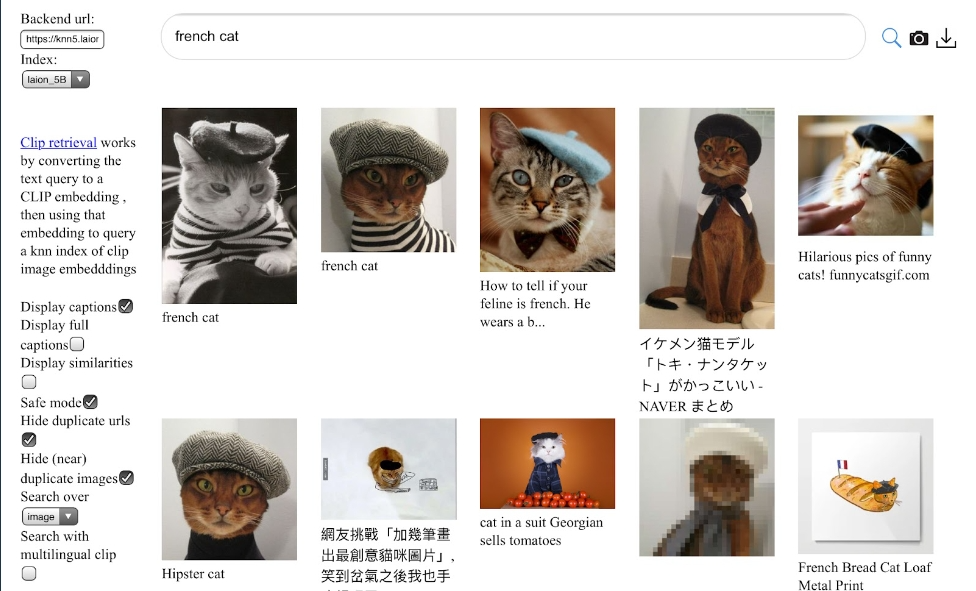
最新的LAION-5B约有58.5亿
Stable Diffusion官方在这个基础上训练了超过40万步,每个版本追加了更高清的图片进行优化,而SD1.5版本就是建立在LAION-5B数据集基础上。
这样庞大的数据集训练成本当然是很高的
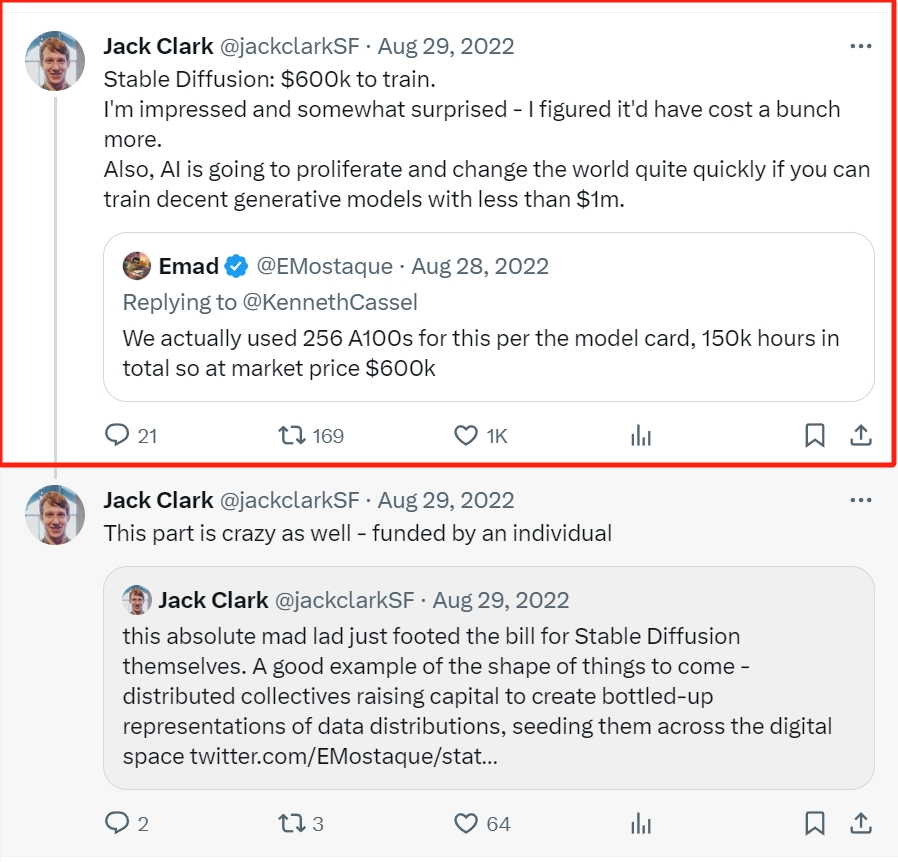
Stable Diffusion团队共使用了256块英伟达A100 GPU,训练了15万个小时共计成本约60万美金,而其竞争对手Dalle2的训练开销约在其7-8倍左右。
现在许多人手机上都有的GPT4训练成本已然超过了1亿美金,回过头看感觉Stable Diffusion还挺有性价比的。
当然看到这里也不要紧张,我们自己训练的模型并不需要这么大规模和这么多钱。

目前AI绘画领域所讨论的所有模型训练都是建立在这些官方已经花了很多钱和时间训练出来的开源模型(预训练模型)基础上。
所以现在绝大多数个人用户上传的模型都是微调模型,也就是那些在已经预训练好的大型模型基础上使用特定的数据集进行进一步训练,这样可以让模型适应特定任务或领域。
在以往官方已经训练好了不同版本的模型,而这些被模型训练者们挑选来训练的模型被称为“基底模型”。当然不只是官方的模型,还可以选择别人微调后的模型再进行一次训练。
目前在各类模型网站上有着各种对模型的微调方式,而且这方式都是一个个开发者自行摸索出来的。
**主流模型微调手段
**
在早期的时候有着各类模型微调手段例如审美梯度Aesthetic Gradient、由NovelAI开发者提供的超网络Hypernetwork等。
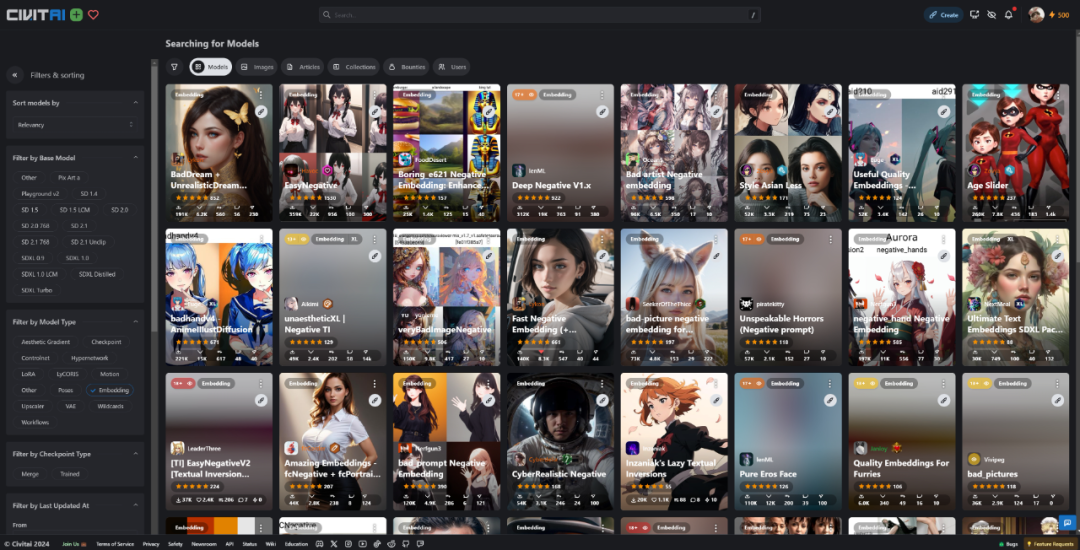
就目前的模型市场上看,还能发挥比较大作用的主流微调训练手法一共有三种:Dreambooth、LoRA(Low-Rank Adaptation)低秩(zhi)适应模型、Textual Inversion文本反演。
这三个微调手法分别对应着我们已经很熟悉的CheckPoint大模型、Lora模型和Embeddings词嵌入模型
Dreambooth(CheckPoint)是最早诞生且对配置要求最高的手段(显存>12GB),它是直接对包括文本编码器到噪声预测器的一整个过程进行微调,但调出来的模型理论上能容纳很多新东西,像是各种风格化的大模型。

LoRa是目前公认性价比最高的微调方式,通过在噪声预测期的神经网络中嵌入一些额外的低秩适应层从而实现高质量微调。配置要求也是最低的(显存>8GB),毕竟生成的模型只需要几十到几百MB,目前用来生成里植入一些人物角色和特定物体。

Textual Inversion(Embeddings)是比较轻量的微调手段(显存>10GB),是通过一些文本(Token)向量层面的微小改动起到微调效果。现多用于一些简单的概念植入或者提高生成图片的质量。

当然显卡配置越高越舒服,最好是16GB以上的配置。如果没有也没关系,可以用线上部署的方式来训练,直接上4090巴巴适适。
不过还有另一种方法:模型之间的融合,现如今所常用的模型大多数都是多个模型融合的结果。

1girl, beautiful face, ((white eyes)), sexy pose, Red moon in the background, stars, space, (lightroom:1.13), soft light, (natural skin texture:1.2), (hyperrealism:1.2), sharp focus, focused,[[realistic]]
Negative prompt: (low quality:1.3), (worst quality:1.3),(monochrome:0.8),(deformed:1.3),(malformed hands:1.4),(poorly drawn hands:1.4),(mutated fingers:1.4),(bad anatomy:1.3),(extra limbs:1.35),(poorly drawn face:1.4),(watermark:1.3),(patreon logo),FastNegativeV2
-
Steps: 30
-
Sampler: Euler a
-
CFG scale: 7
-
Seed: 3943490072
-
Size: 512x512
-
Model hash: e3020b4e49
-
Model: realisian_v50
-
Denoising strength: 0.7
-
Clip skip: 2
-
ENSD: 31337
-
Hires upscale: 2
-
Hires upscaler: R-ESRGAN 4x+
-
Version: v1.6.0-2-g4afaaf8a0
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 1699
1699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









