 Python编程:数据处理与排序算法实践
Python编程:数据处理与排序算法实践




今天又刷了一套题,其中有这么一个问题:
给一堆学生的成绩,将学生的所有成绩求平均值并排序,让我用我熟悉的语言写这个需求:
我的第一感觉是用SQL写:
select student_id ,avg(grade)"avg_grade"from table group by student_id order by avg_grade desc
然后,面试官问到,“除此之外,你还能用其它语言实现吗?”
我想了3s,只想到mean,sorted!怎么写了?
import numpy as np
import pandas as pd
data = {'Chinese': [66, 95, 93, 90,80],'English': [65, 85, 92, 88, 90],'Math': [30, 98, 96, 77, 90]}
symbol=['ZhangFei', 'GuanYu', 'ZhaoYun', 'HuangZhong', 'DianWei']
df2=pd.DataFrame(data,index=symbol)
df2['Chinese'].mean()#求指定列的均值,和
df2['ZhangFei':'ZhangFei'].sum() #并不能求出一个人的三科成绩之和
df2['total']=df2['Chinese']+df2['English']+df2['Math']#相当于重新定义了一个求和列
def sumFunction():
df2['total']=df2['Chinese']+df2['English']+df2['Math']
return df2['total'] #只是计算,并没有定义df2
print(sumFunction())
print(np.sort(df2,axis=0))#numpy是没有描述标签的,没有index,columns,只能通过0列,1行排序
print(df2.sort_values(by=['total']))#DataFrame,可以按照指定列排序
print(df2.sort_index(by=['total']))
#输出
ZhangFei 161
GuanYu 278
ZhaoYun 281
HuangZhong 255
DianWei 260
Name: total, dtype: int64
[[ 66 65 30 161]
[ 80 85 77 255]
[ 90 88 90 260]
[ 93 90 96 278]
[ 95 92 98 281]]
Chinese English Math total
ZhangFei 66 65 30 161
HuangZhong 90 88 77 255
DianWei 80 90 90 260
GuanYu 95 85 98 278
ZhaoYun 93 92 96 281
Chinese English Math total
ZhangFei 66 65 30 161
HuangZhong 90 88 77 255
DianWei 80 90 90 260
GuanYu 95 85 98 278
ZhaoYun 93 92 96 281
面试官此时笑了,不能使用排序函数,你会排序算法吗?
”强忍着不哭,心里mmp,是想让我写排序算法吧“
为了迎合面试官,我笑着回答,“我会冒泡算法”
面试官,眉头一紧,我看着神态不对,快速补充道,”我还会堆排序“
此时,面试官,眉头渐缓,话锋一转,那你手写堆排序吧
冒泡排序--快速排序--堆排序
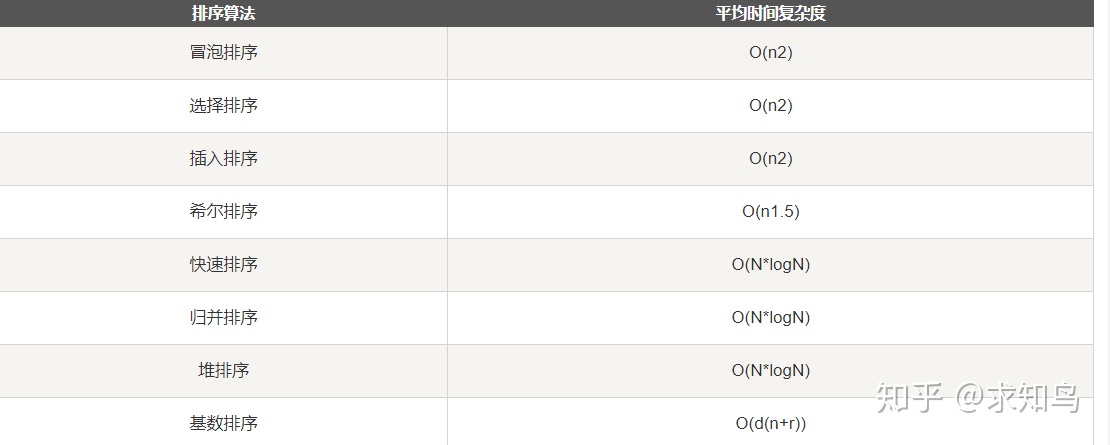
以上均为插科打诨,自娱自乐,接下来正式开始今天的主题:Python实操!
1、获取字符串”123456“最后的两个字符。
a='123456'
print(a[-2:])2、一个编码为 GBK 的字符串 S,要将其转成 UTF-8 编码的字符串,应如何操作?
a="S".encode("gbk").decode("utf-8,ignore")
3、s="info:xiaoZhang 33 shandong",用正则切分字符串输出['info', 'xiaoZhang', '33', 'shandong']
import re
s="info:xiaoZhang 33 shandong"
res=re.split(r":| ",s) #根据冒号或空格切分
print(res)
4、a = "你好 中国 ",去除多余空格只留一个空格。
s="你好 中国 "
print(" ".join(s.split()))
5、已知 AList = [1,2,3,1,2],对 AList 列表元素去重,写出具体过程
a=list([1,2,3,1,1])
b=pd.Series(a)
print(b.unique()) #借助pandas中的函数
print(list(set(a)))#直接用python自带的set函数6、给定两个 list,A 和 B,找出相同元素和不同元素?
A=list([1,2,3,1])
B=list([2,3,4])
print(set(A)&set(B))
print(set(A)^set(B))
7、合并列表[1,5,7,9]和[2,2,6,8]
a=[2,3]
b=[11,2]
print(a+b)#
a.extend(b)#
8、.请合并下面两个字典 a = {"A":1,"B":2},b = {"C":3,"D":4}
a={"A:1","B:2"}
b={"C:3","D:4"}
a.update(b)
print(a)
输出
{'D:4', 'B:2', 'C:3', 'A:1'}9、如何把元组("a","b")和元组(1,2),变为字典{"a":1,"b":2}
a=('a','b')
b=(1,2)
print(dict(zip(a,b)))
{'a': 1, 'b': 2}10、有两个磁盘文件 A 和 B,各存放一行字母,要求把这两个文件中的信息合并(按字母顺序排列),输出到一个新文件 C 中。
A中存储ABCD
B中存储EFGH
with open("C://Users//baihua//Desktop//A.txt",encoding='utf-8') as f1:
f1_txt=f1.readline()
with open("C://Users//baihua//Desktop//B.txt",encoding='utf-8') as f2:
f2_txt=f2.readline()
f3_txt=f1_txt+f2_txt
f3_list=sorted(f3_txt)
with open("C.txt","a+") as f:
f.write("".join(f3_list))
print(f3_list)
['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H']
```11、写一个函数,接收整数参数 n,返回一个函数,函数的功能是把函数的参数和 n 相加并把结果返回。
考察闭包的使用,返回函数的类型是函数对象
def fun_1(a):
def fun_2(b):
return a+b
return fun_2
m=fun_1(8)
print(m(5))
13
12、一行代码输出 1-100 之间的所有偶数。
print(list(range(2,101,2)))13、with 语句的作用,写一段代码?
#一般访问文件资源时我们会这样处理
f=open( 'c:\test.txt','r')
data=f.read()
f.close()
#这样写没有错,但是容易犯两个错误
#1如果在读写时出现异常而忘了异常处理
#2忘了关闭文件句柄
#以下为加强版的写法
f=open( 'c:\test.txt','r')
try:
data=f.read()
finally:
f.close()
#以上写法可以避免因读取文件时异常的发生而没有关闭问题的处理了。
#使用with有更优雅的写法
with open(r 'c:\test.txt','r') as f:
data=f.read()
14、python 字典和 json 字符串相互转化方法
在python中使用dumps方法将dict对象转换成Json对象;
使用loads方法可以将Json对象转化为dict对象。
```
import json
dic_1={'a':'1','b':'456','c':'dfg'}
json_str=json.dumps(dic_1)
dic_2=json.loads(json_str)
print(dic_2)
输出
{'a': '1', 'b': '456', 'c': 'dfg'}
```
15、请写一个 Python 逻辑,计算一个文件中的大写字母数量
with open(r'A.txt','r') as f:
count=0
for i in f.read():
if i.isupper():
count+=1
print(count)
```16、请写一段 Python连接Mysql数据库的代码。
conn = pymysql.connect(host='localhost',
port=3306, user='root',
passwd='1234', db='user', charset='utf8mb4')#声明mysql连接对象
cursor=conn.cursor(cursor=pymysql.cursors.DictCursor)#查询结果以字典的形式
cursor.execute(sql语句字符串)#执行sql语句
conn.close()#关闭链接
```
17、请写一段python导出数据的代码
import pandas as pd
from pandas import Series, DataFrame
score = DataFrame(pd.read_excel('data.xlsx'))
score.to_excel('data1.xlsx')
print score
18、使用正则表达式匹配出<html><h1>百度一下,你就知道</html>中的地址
import re
source = "<html><h1>www.baidu.com</h1></html>"
pat = re.compile("<html><h1>(.*?)</h1></html>")
print(pat.findall(source)[0])
``19、正则表达式匹配中(.*)和(.*?)匹配区别?
(.*) 为贪婪模式极可能多的匹配内容 ,(.*?) 为非贪婪模式又叫懒惰模式,一般匹配到结果就好,匹配字符的少为主,
import re
s = "<html><div>文本 1</div><div>文本 2</div></html>"
pat1 = re.compile(r"\<div>(.*?)\</div>")
print(pat1.findall(s))
pat2 = re.compile(r"\<div>(.*)\</div>")
print(pat2.findall(s))
['文本 1', '文本 2']
['文本 1</div><div>文本 2']
``` 20、写一段匹配邮箱的正则表达式其他内容
电子邮件地址有统一的标准格式:用户名@服务器域名。用户名表示邮件信箱、注册名或信件接收者的用户标识,@符号后是你使用的邮件服务器的域名。@可以读成“at”,也就是“在”的意思。整个电子邮件地址可理解为网络中某台服务器上的某个用户的地址。
用户名,可以自己选择。由字母 a~z(不区分大小写)、数字 0~9、点、减号或下划线组成;只能以数字或字母开头和结尾。
与你使用的网站有关,代表邮箱服务商。例如网易的有@http://163.com 新浪有@http://vip.sina.com 等。
网上看到了各种各样的版本,都不确定用哪个,于是自己简单的总结了一个。大家有更好的欢迎留言。
r"^[a-zA-Z0-9]+[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$"
21、python 中的 is 和==
首先要知道Python中对象包含的三个基本要素,分别是:id(身份标识)、type(数据类型)和value(值)。
is和==都是对对象进行比较判断作用的,但对对象比较判断的内容并不相同。
==用来比较判断两个对象的value(值)是否相等,例如下面两个字符串间的比较:
`a = 'cheesezh'
b= 'cheesezh'
print(a==b)
True
#is
a = (1,2,3) #a和b为元组类型
b = (1,2,3)
print(a is b)
False
print(id(a))
15001280
print(id(b)
14790408
```22、列举 5 个 Python 中的标准模块
sys模块:系统模块,修改默认参数等
json模块:有关数据格式的模块
pathlib:路径操作模块,比os模块拼接方便
urllib:网络请求模块,包括对url的结构解析
asyncio:python的异步库,基于事件循环的协程模块
re:正则表达式模块
ttertools:提供了操作生成器的一些模块
23、列出5个你用过的python库
numpy库:数据分析常用库,提供了包括random,reshape,通用函数,以及多维数组,极大提高了运算效率
pandas库:数据分析常用库,提供了包括unique,value_counts(),reindex,sort_index,等以及Series与DataFrame数据结构。
sklearn库(Scikit-learn):机器学习模型库
Matplotlib库:用于创建二维图和图形的底层库
Seaborn库:基于Matplotlib库的高级API,提供了包括一些复杂类型,比如联合分布图,小提琴图
TensorFlow库:深度学习和机器学习框架,由 Google Brain 开发。它提供了使用具有多个数据集的人工神经网络的能力。在最流行的 TensorFlow应用中有目标识别、语音识别等。
Scrapy库:是一个用来创建网络爬虫,扫描网页和收集结构化数据的库。
24、lambda 表达式格式以及应用场景?
匿名函数,在函数式编程中经常作为常数使用。Python中,也有几个定义好的全局函数方便使用的,filter, map, reduce,这些全局函数可以和lambda配合使用。
foo = [2, 18, 9, 22, 17, 24, 8, 12, 27]
print filter(lambda x: x % 3 == 0, foo)
[18, 9, 24, 12, 27]
print map(lambda x: x * 2 + 10, foo)
[14, 46, 28, 54, 44, 58, 26, 34, 64]
print reduce(lambda x, y: x + y, foo)
139
```
那lambda函数是不是最简洁的使用了?
在对象遍历处理方面,其实Python的for..in..if语法已经很强大,并且在易读上胜过了lambda。
foo = [2, 18, 9, 22, 17, 24, 8, 12, 27]
print (filter(lambda x:x * 2 + 10, foo))#二者等价
print ([x * 2 + 10 for x in foo])
25、copy 和 deepcopy 的区别是什么?
简单来说,copy.copy()浅拷贝,只拷贝父对象,不拷贝对象内部的子对象,copy.deepcopy()深拷贝,拷贝对象及其子对象。
import copy
2 >>> origin = [1, 2, [3, 4]]
3 #origin 里边有三个元素:1, 2,[3, 4]
4 >>> cop1 = copy.copy(origin)
5 >>> cop2 = copy.deepcopy(origin)
6 >>> cop1 == cop2
7 True
8 >>> cop1 is cop2
9 False
10 #cop1 和 cop2 看上去相同,但已不再是同一个object
11 >>> origin[2][0] = "hey!"
12 >>> origin
13 [1, 2, ['hey!', 4]]
14 >>> cop1
15 [1, 2, ['hey!', 4]]
16 >>> cop2
17 [1, 2, [3, 4]]
浅拷贝依赖于源,源变,浅拷贝就变!
深拷贝独立出来了,源变与深拷贝没关系!
26、w、a+、wb 文件写入模式的区别
r : 读取文件,若文件不存在则会报错
w: 写入文件,若文件不存在则会先创建再写入,会覆盖原文件
a : 写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾
rb,wb:分别与r,w类似,但是用于读写二进制文件
r+ : 可读、可写,文件不存在也会报错,写操作时会覆盖
w+ : 可读,可写,文件不存在先创建,会覆盖
a+ :可读、可写,文件不存在先创建,不会覆盖,追加在末尾
27、举例 sort 和 sorted 的区别
sort 只是应用在 list 上的方法,(就地排序无返回值)。
sorted 是内建函数,可对所有可迭代的对象进行排序操作,(返回新的list)。
>>> students = [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
>>> sorted(students, key=lambda s: s[2])
[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]28、用三种方式实现最大最小归一化
import numpy as np
import pandas as pd
#方法一
def autoNorm(dataSet):
norm_data=(dataSet-dataSet.min(axis=0))/(dataSet.max(axis=0)-dataSet.min(axis=0))
return norm_data
train_data=np.arange(16).reshape(4,4)
print(autoNorm(train_data))
#方法二
def autoNprm(dataSet):
minVals=dataSet.min(0)#0按照列,1按照行,取最小值;1*3
maxVals=dataSet.max(0)
ranges=maxVals-minVals #归一化的分母
normDataSet=zeros(shape(dataSet))#创建输入数据的同类型矩阵
m=dataSet.shape[0]#输出行数
normDataSet=dataSet-tile(minVals,(m,1))#矩阵-矩阵;要求:1000*3-1000*3;tile()可实现将minVals复制1000行
normDataSet=normDataSet/tile(ranges,(m,1))#特征值相除用/,矩阵相除用linalg.solve(matA,matB)
return normDataSet
print(autoNorm(train_data))
#方法三,python自带方法
# coding:utf-8
from sklearn import preprocessing
import numpy as np
# 初始化数据,每一行表示一个样本,每一列表示一个特征
x = np.array([[ 0., -3., 1.],
[ 3., 1., 2.],
[ 0., 1., -1.]])
# 将数据进行 [0,1] 规范化
min_max_scaler = preprocessing.MinMaxScaler()
minmax_x = min_max_scaler.fit_transform(x)
print minmax_x
[[0. 0. 0.66666667]
[1. 1. 1. ]
[0. 1. 0. ]]
29、用Python实现Z-评分归一化
def autoNorm(dataSet):
norm_data=(dataSet-dataSet.mean(axis=0))/dataSet.std(axis=0)
return norm_data
train_data=np.arange(16).reshape(4,4)
print(autoNorm(train_data))
#方法二
from sklearn import preprocessing
import numpy as np
# 初始化数据
x = np.array([[ 0., -3., 1.],
[ 3., 1., 2.],
[ 0., 1., -1.]])
# 将数据进行 Z-Score 规范化
scaled_x = preprocessing.scale(x)
print scaled_x
[[-0.70710678 -1.41421356 0.26726124]
[ 1.41421356 0.70710678 1.06904497]
[-0.70710678 0.70710678 -1.33630621]]Python经验分享
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
Python学习路线
这里把Python常用的技术点做了整理,有各个领域的知识点汇总,可以按照上面的知识点找对应的学习资源。
学习软件
Python常用的开发软件,会给大家节省很多时间。
学习视频
编程学习一定要多多看视频,书籍和视频结合起来学习才能事半功倍。
100道练习题

实战案例
光学理论是没用的,学习编程切忌纸上谈兵,一定要动手实操,将自己学到的知识运用到实际当中。
最后祝大家天天进步!!
上面这份完整版的Python全套学习资料已经上传至优快云官方,朋友如果需要可以直接微信扫描下方优快云官方认证二维码免费领取【保证100%免费】。

















 1058
1058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









