







 本文深入探讨RocketMQ为实现高效读写性能在存储架构上的设计,包括存储结构选型对比,RocketMQ选择单个文件存储的原因,如何平衡读性能,以及消息消费的索引构建和位点记录,揭示了RocketMQ如何优化存储以满足高效率需求。
本文深入探讨RocketMQ为实现高效读写性能在存储架构上的设计,包括存储结构选型对比,RocketMQ选择单个文件存储的原因,如何平衡读性能,以及消息消费的索引构建和位点记录,揭示了RocketMQ如何优化存储以满足高效率需求。
MQ作为一款中间件,就需要承载全公司所有业务系统使用需求,并高效稳定运行。因此,MQ对本身运行效率有着非常苛刻的诉求。
为了实现高效率,其实需要很多方面一起配合来完成。比如存储方式、内存使用、负载均衡等等。
本文就RocketMQ为了实现高效的读写速率在存储架构上所做的努力,进行下阐述。
Part one / 存储结构选型对比
为了更方便的进行数据读写,消息在磁盘底层的文件目录设计,都需要关注和解决什么问题呢:
• 首先,最基本的,消息原始记录的写入和存储,且速率要快。 • 其次,要可以区分 topic ,特别是允许消费者按 topic 进行接收。 • 再次,分布式集群下的多消费者负载均衡。
那么问题来了,消息文件该怎么设计呢?
如果按 topic 来拆分文件进行存储,是否可以?
• 缺点:生产者写入时选择对应的文件来写入。当数据量逐渐增大之后,定位查询文件地址,对磁盘的寻址所带来的性能损耗,将不再可以忽略。 • 优点:在消费时,可以直接加载相关文件进行读取,不会产生随机寻址。
如果用一整个文件来存消息呢?
• 优点:所有的 topic 都被写入一个文件中,这样,写入时,只要将消息按到达顺序序追加到文件尾部即可,很容易实现顺序写入。 • 缺点:消费时,需要根据辅助信息来在文件中定位消息,会产生随机读,损耗性能。
因此,不管是按 topic 拆开多文件存储,还是一整个文件存储做有利有弊,需要按实际需要进行权衡。
Part two / RocketMQ的存储方案选择
RocketMQ 存储原始消息选择的是写同一个文件。
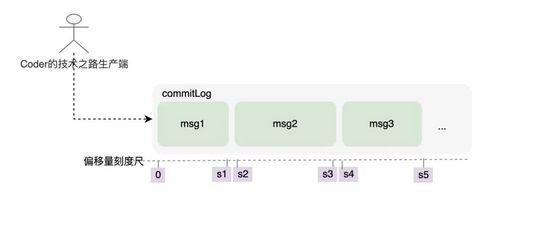
生产者将消息顺序写入commitLog文件
究其原因,是由于 RocketMQ 一般都是普通业务场景使用居多,生产者和 topic 众多,如果都独立开各自存储,每次消息生产的磁盘寻址对性能损耗是非常巨大的。
旁证侧引:
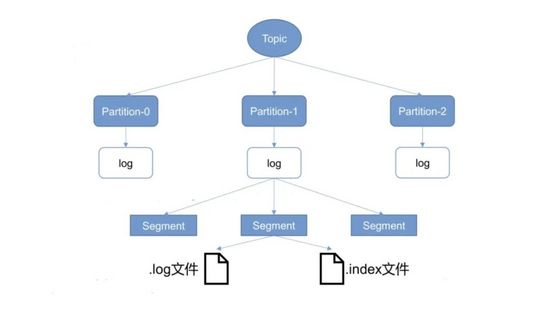
kafka 的文件存储方式,是按 topic 拆分成 partation 来进行的。是什么样的原因,让 kafka 做出了和 RocketMQ 相反的选择呢?
个人认为,主要还是使用场景的区别, kafka 被优先选择用来进行大数据处理,相对于业务场景,数据维度的 topic 要少很多,并且 kafka 的生产者( spark flume binlog 等)机器会更加集中,这使得 kafka 选择按 topic
拆分文件的缺陷不那么突出,而大数据处理更重要的是消息读取,顺序读的优势得以被充分利用。
"
单 partation ,单 cunsumer 的 kafka ,性能异常的优秀
" 是经常被提及的一个观点,其原因,相信有了上面的分析应该也差不多有结论了。
Part three / RocketMQ怎样平衡读性能
从第一部分的存储方案对比可以知道, RocketMQ 为了保证消息写入效率,在存储结构上选择了 顺序写 ,势必会对消息的读取和消费带来不便。
那么,它是怎么来平衡消费时的读取速率的呢?
关键问题是,找到一种途径,可以快速的在 commitLog 中定位到所需消息的位置。
索引 RocketMQ commitLog 索引文件 topic
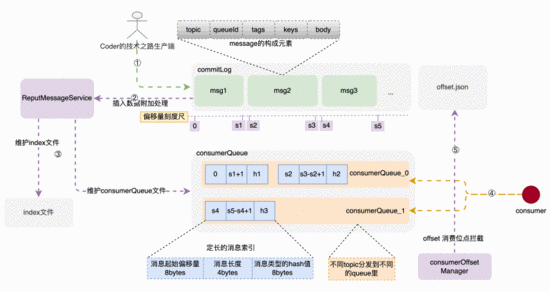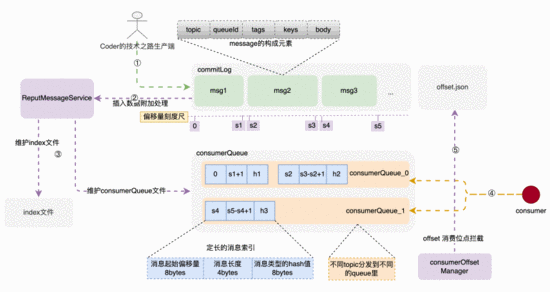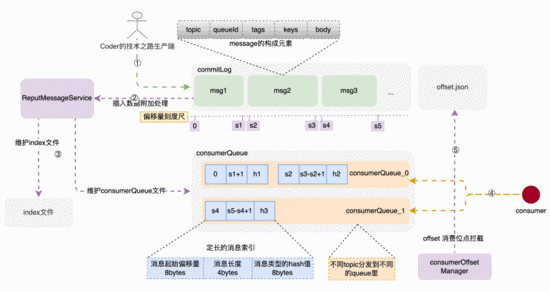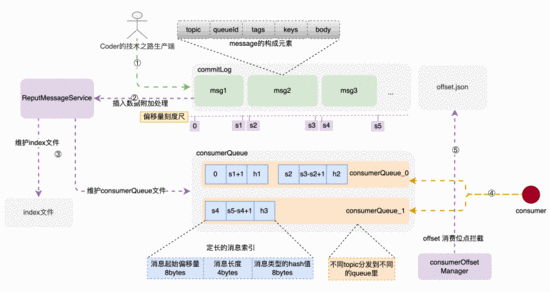
存储架构和存储构建链路示意图
RocketMQ 的消息体构成

消息体元素构成
• topic 是业务场景的唯一标识,不可缺少; • queueId 在申请topic的时候确定,关联着消费索引 consumerQueue 中的队列ID; • tags 是消息特殊标签,用于业务系统订阅时提前过滤(这个功能真的是太重要了,吃过苦的同学都清楚); • keys 是消息的关键字,构建index索引,用于关键字查询用; • msgBody 是真实消息体;
消息由发布者发布,并依次的、顺序的写到 commitLog 里,消息一旦被写入,是不可以更改顺序和内容的。 commitLog 规定最大1个G,达到规定大小则写新的一个文件。
索引结构和构建过程
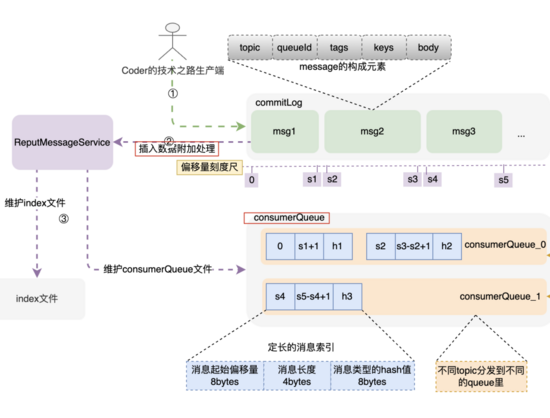
consumerQueue结构和创建过程
consumerQueue queue commitLog commitLog
consumerQueue topic queue queueId
bytes commitLog type hash码
而上述索引的构建过程,是在消息被写入 commitLog 时,专门的后台服务-- putMessageService ,将索引信息分发到 consumerQueue 和index文件里,来构建索引项。
建索引的过程,实际上是一种分而治之思维的落地,除了索引,还有redis中的各种指标维护,核心是 分散压力到每次请求,避免了大规模集中计算。
消息的消费
消费者对应consumerQueue不一定是一对一的,因此,怎么来让每个新的消费者来了不会重复消费呢?
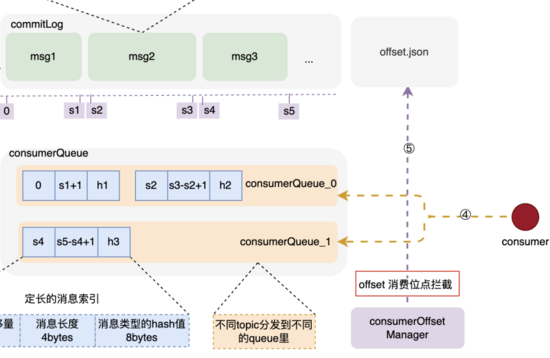
offset消费位点记录
在消息成功被拉取并消费时,后台任务 CommitOffsetManager 会将当前消费者,针对topic的消费位点进行记录,目的是让下一个或者重新启动单饿消费者记住这个消费位点,不至于重复消费。
因此,整个文件目录就一目了然了:

Part four / 读效率的追求
虽然通过上述文件存储结构的分析,我们知道,消费者可以根据索引文件中的索引项来快速定位, 但事实上,消息的发布和消费,不可能直接针对磁盘进行读写操作的,这样效率会非常非常低。
实际上,我们的操作基本是针对一块内存进行操作的。
commitLog 操作系统 pageCache
• 消息发布者,在发布消息的时候,首先把消息添加到内存里,然后根据刷盘的配置可以来指定是同步刷盘还是异步刷盘,来将内存中的数据同步到磁盘上。 • 消息的消费者,在消费消息的时候,大多数情况下,会直接命中到内存上,不会进行磁盘读,但极个别的情况下,需要消费的消息,在内存中没法找到,这时候,就需要用换页技术,将相关的信息,拉取到内存中。为什么是相关信息,而不是需要什么拉取什么?这是有一个机制,来保证潜在的即将被消费的信息直接换入内存,来提交效率。
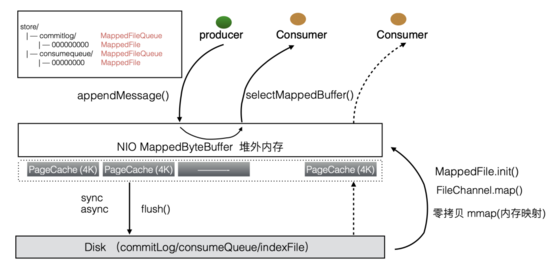
摘自:Qcon大会 RocketMQ分享资料
Part five / 总结
整体一套处理流程看下来,其实我们可以看到很多熟悉的身影,比如Mysql的索引,redis的统计信息记录等等,都非常相似。
其实,我们可以这么认为:对于信息存储和查询的处理方案大都如出一辙,只要把握住最核心的部分,然后根据实际业务诉求进行适配优化,基本都是可以达到期望的结果的。

















 1033
1033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









