







 本文详细介绍了如何在Java中实现LRU(最近最少使用)缓存,包括LRU缓存的结构、算法原理以及并发性处理。通过结合HashMap和双向链表,确保了缓存的高效读写。文章还提供了具体的Java代码实现,并讨论了使用读写锁以保证线程安全。
本文详细介绍了如何在Java中实现LRU(最近最少使用)缓存,包括LRU缓存的结构、算法原理以及并发性处理。通过结合HashMap和双向链表,确保了缓存的高效读写。文章还提供了具体的Java代码实现,并讨论了使用读写锁以保证线程安全。
最近使用最少(LRU)缓存是一种缓存逐出算法,它按使用顺序组织元素。顾名思义,在LRU中,最长时间未使用的元素将从缓存中逐出。
例如,如果我们有一个容量为三项的缓存:
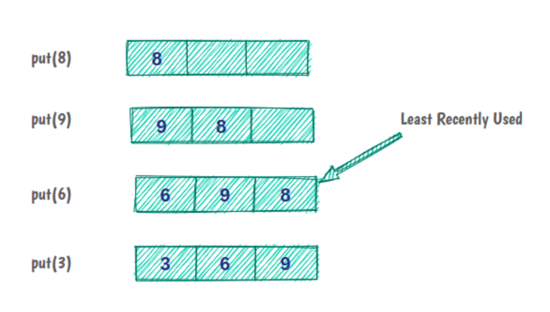
最初,缓存是空的,我们将元素 8 放在缓存中。元素 9 和 6 像以前一样被缓存。但现在,缓存容量已满,要放入下一个元素,我们必须逐出缓存中最近使用最少的元素。
在我们用Java实现LRU缓存之前,最好先了解一下缓存的一些方面:
O(1)
LRU缓存的结构
现在,让我们考虑一个有助于我们设计缓存的问题。
我们如何设计一个可以在固定时间内执行读取、排序(时态排序)和删除元素等操作的数据结构?
似乎要找到这个问题的答案,我们需要深入思考关于LRU缓存及其特性的说法:
- 实际上,LRU缓存是一种 队列 —如果重新访问某个元素,它将进入逐出顺序的末尾
- 此队列将具有特定容量,因为缓存的大小有限。每当引入新元素时,它都会添加到队列的最前面。当逐出发生时,它发生在队列的尾部。
- 命中缓存中的数据必须在固定时间内完成,这在队列中是不可能的!但是,使用Java的
HashMap数据结构是可能的 - 删除最近使用最少的元素必须在固定时间内完成,这意味着对于队列的实现,我们将使用
DoublyLinkedList而不是SingleLinkedList或数组
因此,LRU缓存只是 DoublyLinkedList 和 HashMap 的组合,如下所示:
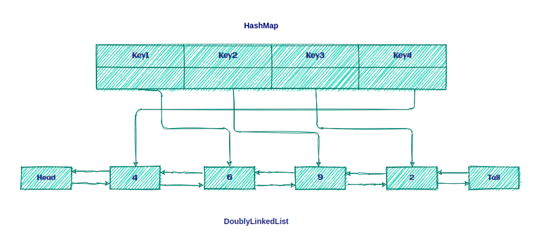
这样做的目的是将密钥保留在Map上,以便快速访问队列中的数据。
LRU算法
LRU算法非常简单!如果密钥存在于 HashMap 中,则为缓存命中;否则,就是缓存丢失了。
缓存未命中后,我们将执行两个步骤:
1. 在列表前面添加新元素。
2. 在 HashMap 中添加一个新条目并引用列表的标题。
在缓存命中后,我们将执行两个步骤:
1. 删除hit元素并将其添加到列表前面。
2. 使用列表前面的新引用更新 HashMap 。
现在,我们来看看如何在Java中实现LRU缓存!
Java实现
首先,我们将定义缓存接口:
public interface Cache<K, V> {
boolean set(K key, V value);
Optional<V> get(K key);
int size();
boolean isEmpty();
void clear();
}
现在,我们将定义表示缓存的 LRUCache 类:
public class LRUCache<K, V> implements Cache<K, V> {
private int size;
private Map<K, LinkedListNode<CacheElement<K,V>>> linkedListNodeMap;
private DoublyLinkedList<CacheElement<K,V>> doublyLinkedList;
public LRUCache(int size) {
this.size = size;
this.linkedListNodeMap = new HashMap<>(maxSize);
this.doublyLinkedList = new DoublyLinkedList<>();
}
// rest of the implementation
}
我们可以创建具有特定大小的 LRUCache 实例。在这个实现中,我们使用 HashMap 集合来存储对 LinkedListNode 的所有引用。
现在,让我们来讨论我们的LRUCache的操作。
put操作
第一种是 put 方法:
public boolean put(K key, V value) {
CacheElement<K, V> item = new CacheElement<K, V>(key, value);
LinkedListNode<CacheElement<K, V>> newNode;
if (this.linkedListNodeMap.containsKey(key)) {
LinkedListNode<CacheElement<K, V>> node = this.linkedListNodeMap.get(key);
newNode = doublyLinkedList.updateAndMoveToFront(node, item);
} else {
if (this.size() >= this.size) {
this.evictElement();
}
newNode = this.doublyLinkedList.add(item);
}
if(newNode.isEmpty()) {
return false;
}
this.linkedListNodeMap.put(key, newNode);
return true;
}
首先,我们在 linkedListNodeMap 中找到存储所有键/引用的键。如果该键存在,则会发生缓存命中,并准备从 DoublyLink 列表中检索 CacheElement 并将其移动到前面。
之后,我们使用新引用更新 linkedListNodeMap ,并将其移动到列表的前面:
public LinkedListNode<T> updateAndMoveToFront(LinkedListNode<T> node, T newValue) {
if (node.isEmpty() || (this != (node.getListReference()))) {
return dummyNode;
}
detach(node);
add(newValue);
return head;
}
首先,我们检查节点是否为空。此外,节点的引用必须与列表相同。之后,我们从列表中分离节点,并向列表中添加 newValue 。
但是如果密钥不存在,就会发生缓存丢失,我们必须将新密钥放入 linkedListNodeMap 。在此之前,我们检查列表大小。如果列表已满,我们必须从列表中逐出最近使用最少的元素。
get操作
让我们看看我们的 get 操作:
public Optional<V> get(K key) {
LinkedListNode<CacheElement<K, V>> linkedListNode = this.linkedListNodeMap.get(key);
if(linkedListNode != null && !linkedListNode.isEmpty()) {
linkedListNodeMap.put(key, this.doublyLinkedList.moveToFront(linkedListNode));
return Optional.of(linkedListNode.getElement().getValue());
}
return Optional.empty();
}
如上所述,此操作非常简单。首先,我们从 linkedListNodeMap 获取节点,然后检查它是否为 null 或空。
操作的其余部分与之前相同,只是 moveToFront 方法有一个区别:
public LinkedListNode<T> moveToFront(LinkedListNode<T> node) {
return node.isEmpty() ? dummyNode : updateAndMoveToFront(node, node.getElement());
}
现在,让我们创建一些测试来验证缓存是否正常工作:
@Test
public void addSomeDataToCache_WhenGetData_ThenIsEqualWithCacheElement(){
LRUCache<String,String> lruCache = new LRUCache<>(3);
lruCache.put("1","test1");
lruCache.put("2","test2");
lruCache.put("3","test3");
assertEquals("test1",lruCache.get("1").get());
assertEquals("test2",lruCache.get("2").get());
assertEquals("test3",lruCache.get("3").get());
}
现在,让我们测试驱逐策略:
@Test
public void addDataToCacheToTheNumberOfSize_WhenAddOneMoreData_ThenLeastRecentlyDataWillEvict(){
LRUCache<String,String> lruCache = new LRUCache<>(3);
lruCache.put("1","test1");
lruCache.put("2","test2");
lruCache.put("3","test3");
lruCache.put("4","test4");
assertFalse(lruCache.get("1").isPresent());
}
处理并发性
到目前为止,我们假设我们的缓存只在单线程环境中使用。
为了使这个容器线程安全,我们需要同步所有公共方法。让我们在前面的实现中添加 ReentrantReadWriteLock 和 ConcurrentHashMap :
public class LRUCache<K, V> implements Cache<K, V> {
private int size;
private final Map<K, LinkedListNode<CacheElement<K,V>>> linkedListNodeMap;
private final DoublyLinkedList<CacheElement<K,V>> doublyLinkedList;
private final ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
public LRUCache(int size) {
this.size = size;
this.linkedListNodeMap = new ConcurrentHashMap<>(size);
this.doublyLinkedList = new DoublyLinkedList<>();
}
// ...
}
我们更喜欢使用可重入读/写锁,而不是将方法声明为 synchronized ,因为它使我们能够更灵活地决定何时在读和写时使用锁。
写锁
现在,让我们在 put 方法中添加对 writeLock 的调用:
public boolean put(K key, V value) {
this.lock.writeLock().lock();
try {
//..
} finally {
this.lock.writeLock().unlock();
}
}
当我们对资源使用 writeLock 时,只有持有锁的线程才能写入或读取资源。因此,所有其他试图读取或写入资源的线程都必须等待当前锁持有者释放它。
这对于防止死锁非常重要。如果 try 块中的任何操作失败,我们仍然会在退出函数之前释放锁,并在方法末尾使用 finally 块。
需要 writeLock 的另一个操作是 executeElement ,我们在put方法中使用了它:
private boolean evictElement() {
this.lock.writeLock().lock();
try {
//...
} finally {
this.lock.writeLock().unlock();
}
}
读锁
现在是向 get 方法添加 readLock 调用的时候了:
public Optional<V> get(K key) {
this.lock.readLock().lock();
try {
//...
} finally {
this.lock.readLock().unlock();
}
}
这似乎正是我们用 put 方法所做的。唯一的区别是我们使用 readLock 而不是 writeLock 。因此,读锁和写锁之间的这种区别允许我们在不更新缓存时并行读取缓存。
现在,让我们在并发环境中测试缓存:
@Test
public void runMultiThreadTask_WhenPutDataInConcurrentToCache_ThenNoDataLost() throws Exception {
final int size = 50;
final ExecutorService executorService = Executors.newFixedThreadPool(5);
Cache<Integer, String> cache = new LRUCache<>(size);
CountDownLatch countDownLatch = new CountDownLatch(size);
try {
IntStream.range(0, size).<Runnable>mapToObj(key -> () -> {
cache.put(key, "value" + key);
countDownLatch.countDown();
}).forEach(executorService::submit);
countDownLatch.await();
} finally {
executorService.shutdown();
}
assertEquals(cache.size(), size);
IntStream.range(0, size).forEach(i -> assertEquals("value" + i,cache.get(i).get()));
}
结论
在本文中,我们了解了LRU缓存的确切含义,包括它的一些最常见的特性。然后,我们看到了一种在Java中实现LRU缓存的方法,并探讨了一些最常见的操作。
最后,我们介绍了使用锁机制实现的并发性。
与往常一样,本文中使用的所有示例都可以在GitHub上获得: https://github.com/eugenp/tutorials/tree/master/data-structures

















 647
647


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








