




 本文探讨了为何需要在系统中引入多级缓存,特别是L1 Caffeine JVM缓存和L2 Redis缓存,以减少网络IO消耗并提高性能。文章指出了Spring Cache在实现多级缓存时的设计难点,包括单一缓存源和支持数据一致性的问题。随后,作者介绍了如何配置和使用这种多级缓存方案,并给出了性能对比数据。最后,详细解释了自定义CacheManager和过期策略的实现细节,利用Redis的pub/sub消息机制来确保缓存的一致性。
本文探讨了为何需要在系统中引入多级缓存,特别是L1 Caffeine JVM缓存和L2 Redis缓存,以减少网络IO消耗并提高性能。文章指出了Spring Cache在实现多级缓存时的设计难点,包括单一缓存源和支持数据一致性的问题。随后,作者介绍了如何配置和使用这种多级缓存方案,并给出了性能对比数据。最后,详细解释了自定义CacheManager和过期策略的实现细节,利用Redis的pub/sub消息机制来确保缓存的一致性。
为什么多级缓存
缓存的引入是现在大部分系统所必须考虑的
- redis 作为常用中间件,虽然我们一般业务系统(毕竟业务量有限)不会遇到如下图 在随着 data-size 的增大和数据结构的复杂的造成性能下降,但网络 IO 消耗会成为整个调用链路中不可忽视的部分。尤其在 微服务架构中,一次调用往往会涉及多次调用 例如pig oauth2.0 的 client 认证[1]

综合所述:我们需要构建 L1 Caffeine JVM 级别缓存 , L2 Redis 缓存。
设计难点
目前大部分应用缓存都是基于 Spring Cache 实现,基于注解(annotation)的缓存(cache)技术,存在的问题如下:
- Spring Cache 仅支持 单一的缓存来源,即:只能选择 Redis 实现或者 Caffeine 实现,并不能同时使用。
- 数据一致性:各层缓存之间的数据一致性问题,如应用层缓存和分布式缓存之前的数据一致性问题。
- 缓存过期:Spring Cache 不支持主动的过期策略
业务流程
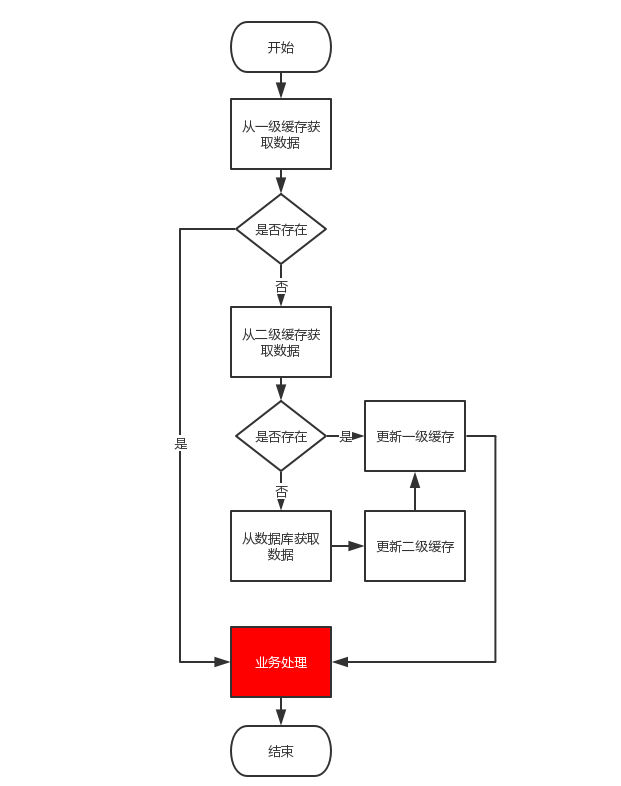
如何使用
- 引入依赖
<dependency>
<groupId>com.pig4cloud.pl 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









