




 本文深入探讨线程池在不同任务类型(计算密集型、IO密集型及混合型)下的最优配置策略,通过实验量化分析线程数与性能的关系,揭示了线程池大小对系统资源利用与任务执行效率的影响。
本文深入探讨线程池在不同任务类型(计算密集型、IO密集型及混合型)下的最优配置策略,通过实验量化分析线程数与性能的关系,揭示了线程池大小对系统资源利用与任务执行效率的影响。
去年的一篇《ThreadPoolExecutor详解》大致讲了ThreadPoolExecutor内部的代码实现。
总结一下,主要有以下四点:
- 当有任务提交的时候,会创建核心线程去执行任务(即使有核心线程空闲仍会创建);
- 当核心线程数达到corePoolSize时,后续提交的都会进BlockingQueue中排队;
- 当BlockingQueue满了(offer失败),就会创建临时线程(临时线程空闲超过一定时间后,会被销毁);
- 当线程总数达到maximumPoolSize时,后续提交的任务都会被RejectedExecutionHandler拒绝。
prestartAllCoreThreads方法可以直接创建所有核心线程并启动。
BlockingQueue使用无限容量的阻塞队列(如LinkedBlockingQueue)时,不会创建临时线程(因为队列不会满),所以线程数保持corePoolSize。
BlockingQueue使用没有容量的同步队列(如SynchronousQueue)时,任务不会入队,而是直接创建临时线程去执行任务。
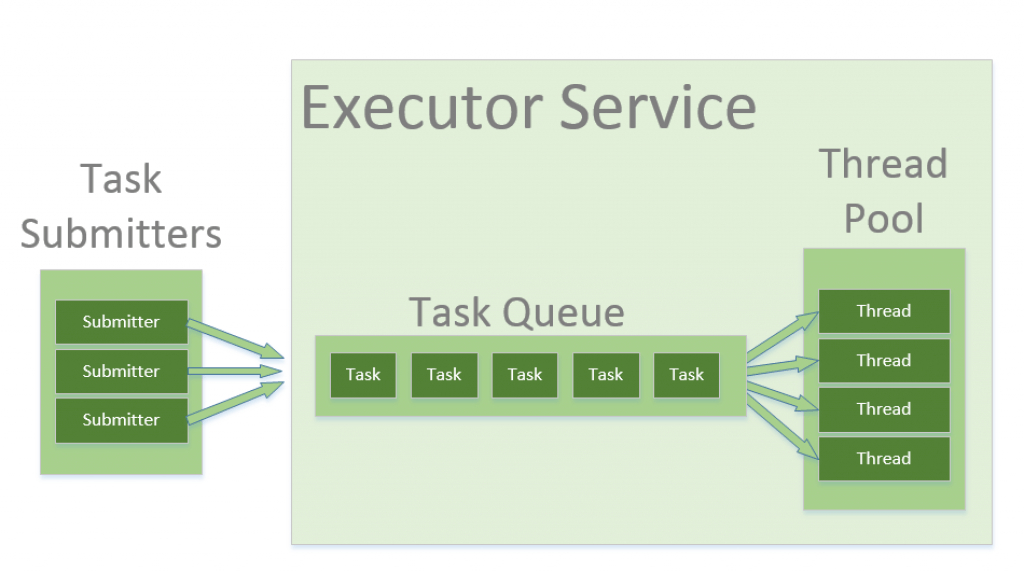
虽然线程池的模型被剖析的非常清晰,但是如何最高性能地使用线程池一直是一个令人纠结的问题,其中最主要的问题就是如何决定线程池的大小。
这篇文章会以量化测试的方式分析:何种情况线程池应该使用多少线程数。
1. 计算密集型任务与IO密集型任务
大多数刚接触线程池的人会认为有一个准确的值作为线程数能让线程池适用在程序的各个地方。然而大多数情况下并没有放之四海而皆准的值,很多时候我们要根据任务类型来决定线程池大小以达到最佳性能。
计算密集型任务以CPU计算为主,这个过程中会涉及到一些内存数据的存取(速度明显快于IO),执行任务时CPU处于忙碌状态。
IO密集型任务以IO为主,比如读写磁盘文件、读写数据库、网络请求等阻塞操作,执行IO操作时,CPU处于等待状态,等待过程中操作系统会把CPU时间片分给其他线程。
2. 计算密集型任务
下面写一个计算密集型任务的例子:
public class ComputeThreadPoolTest {
final static ThreadPoolExecutor computeExecutor;
final static List<Callable<Long>> computeTasks;
final static int task_count = 5000;
static {
computeExecutor = (ThreadPoolExecutor) Executors.newFixedThreadPool(1);
// 创建5000个计算任务
computeTasks = new ArrayList<>(task_count);
for (int i = 0; i < task_count; i++) {
computeTasks.add(new ComputeTask());
}
}
static class ComputeTask implements Callable<Long> {
// 计算一至五十万数的总和(纯计算任务)
@Override
public Long call() {
long sum = 0;
for (long i = 0; i < 50_0000; i++) {
sum += i;
}
return sum;
}
}
public static void main(String[] args) throws InterruptedException {
// 我电脑是四核处理器
int processorsCount = Runtime.getRuntime().availableProcessors();
// 逐一增加线程池的线程数
for (int i = 1; i <= processorsCount * 5; i++) {
computeExecutor.setCorePoolSize(i);
computeExecutor.setMaximumPoolSize(i);
computeExecutor.prestartAllCoreThreads();
System.out.print(i);
computeExecutor.invokeAll(computeTasks); // warm up all thread
System.out.print("\t");
testExecutor(computeExecutor, computeTasks);
System.out.println();
// 一定要让cpu休息会儿,Windows桌面操作系统不会让应用长时间霸占CPU
// 否则Windows回收应用程序的CPU核心数将会导致测试结果不准确
TimeUnit.SECONDS.sleep(5);// cpu rest
}
computeExecutor.shutdown();
}
private static <T> void testExecutor(ExecutorService executor, List<Callable<T>> tasks)
throws InterruptedException {
for (int i = 0; i < 8; i++) {
long start = System.currentTimeMillis();
executor.invokeAll(tasks); // ignore result
long end = System.currentTimeMillis();
System.out.print(end - start); // 记录时间间隔
System.out.print("\t");
TimeUnit.SECONDS.sleep(1); // cpu rest
}
}
}
将程序生成的数据粘贴到excel中,并对数据进行均值统计
注意如果相同的线程数两次执行的时间相差比较大,说明测试的结果不准确。
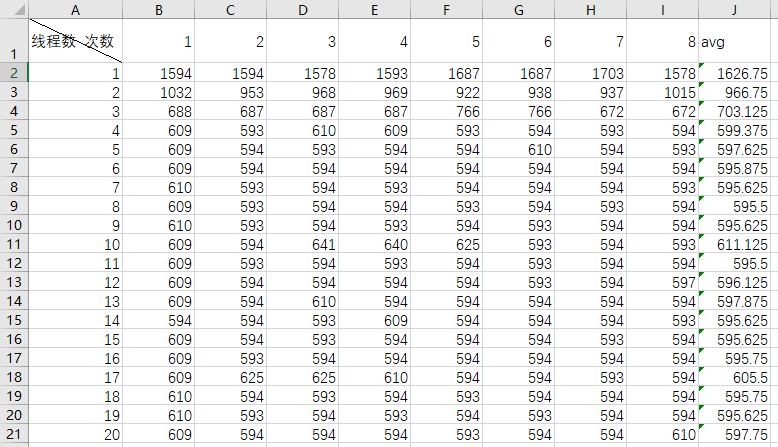
测试程序生成的数据可以从这下载
对数据生成折线图
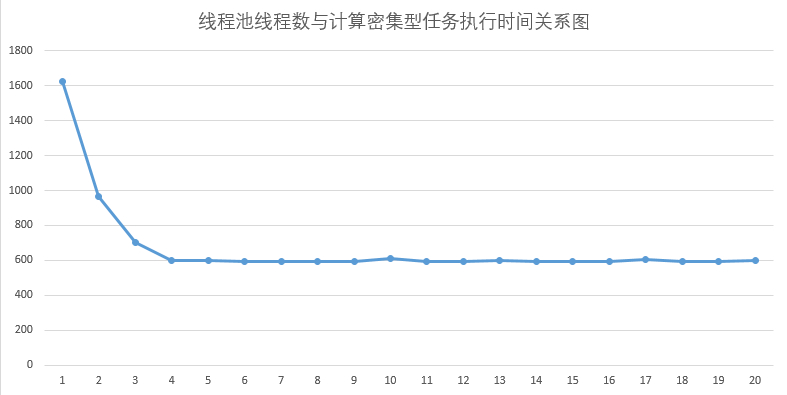
由于我笔记本的CPU有四个处理器,所以会发现当线程数达到4之后,5000个任务的执行时间并没有变得更少,基本上是在600毫秒左右徘徊。
因为计算机只有四个处理器可以使用,当创建更多线程的时候,这些线程是得不到CPU的执行的。
所以对于计算密集型任务,应该将线程数设置为CPU的处理个数,可以使用Runtime.availableProcessors方法获取可用处理器的个数。
《并发编程实战》一书中对于IO密集型任务建议线程池大小设为$N_{cpu}+1$,原因是当计算密集型线程偶尔由于页缺失故障或其他原因而暂停时,这个“额外的”线程也能确保这段时间内的CPU始终周期不会被浪费。
对于计算密集型任务,不要创建过多的线程,由于线程有执行栈等内存消耗,创建过多的线程不会加快计算速度,反而会消耗更多的内存空间;另一方面线程过多,频繁切换线程上下文也会影响线程池的性能。
3. 每个程序员都应该知道的延迟数
IO操作包括读写磁盘文件、读写数据库、网络请求等阻塞操作,执行这些操作,线程将处于等待状态。
为了能更准确的模拟IO操作的阻塞,我觉得有必要将https://people.eecs.berkeley.edu/~rcs/research/interactive_latency.html中列举的延迟数整理出来。
| 事件 | 纳秒 | 微秒 | 毫秒 | 对照 |
|---|---|---|---|---|
| 一级缓存 | 0.5 | - | - | - |
| 二级缓存 | 7 | - | - | 一级缓存时间14倍 |
| 互斥锁定/解锁 | 25.0 | - | - | - |
| 主存参考 | 100.0 | - | - | 二级缓存20倍,一级缓存200倍 |
| 使用Zippy压缩1K字节 | 3,000.0 | 3 | - | - |
| 通过1Gbps网络发送1K字节 | 10,000.0 | 10 | - | - |
| 从SSD中随机读取4K | 150,000.0 | 150 | - | 1GB/秒的读取速度的SSD硬盘 |
| 从内存中顺序读取1MB | 250,000.0 | 250 | - | - |
| 在同一数据中心局域网内往返 | 500,000.0 | 500 | - | - |
| 从SSD顺序读取1MB | 1,000,000.0 | 1000 | 1 | 1GB/秒SSD,4X 内存 |
| 磁盘搜寻 | 10,000,000.0 | 10000 | 10 | 20X 数据中心往返 |
| 从磁盘顺序读取1MB | 20,000,000.0 | 20000 | 20 | 80X 内存,20X SSD |
| 发送一个数据包 美国加州→荷兰→加州 | 150,000,000.0 | 150000 | 150 | - |
4. IO密集型任务
这里用sleep方式模拟IO阻塞:
这里用sleep方式模拟IO阻塞:
public class IOThreadPoolTest {
// 使用无限线程数的CacheThreadPool线程池
static ThreadPoolExecutor cachedThreadPool = (ThreadPoolExecutor) Executors.newCachedThreadPool();
static List<Callable<Object>> tasks;
// 仍然是5000个任务
static int taskNum = 5000;
static {
tasks = new ArrayList<>(taskNum);
for (int i = 0; i < taskNum; i++) {
tasks.add(Executors.callable(new IOTask()));
}
}
static class IOTask implements Runnable {
@Override
public void run() {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
cachedThreadPool.invokeAll(tasks);// warm up all thread
testExecutor(cachedThreadPool, tasks);
// 看看执行过程中创建了多少个线程
int largestPoolSize = cachedThreadPool.getLargestPoolSize();
System.out.println("largestPoolSize:" + largestPoolSize);
cachedThreadPool.shutdown();
}
private static void testExecutor(ExecutorService executor, List<Callable<Object>> tasks)
throws InterruptedException {
long start = System.currentTimeMillis();
executor.invokeAll(tasks);
long end = System.currentTimeMillis();
System.out.println(end - start);
}
}
这里使用无线程数限制的CachedThreadPool线程池,也就是说这里的5000个任务会被5000个线程同时处理,由于所有的线程都只是阻塞而不消耗CPU资源,所以5000个任务在不到2秒的时间内就执行完了。
很明显使用CachedThreadPool能有效提高IO密集型任务的吞吐量,而且由于CachedThreadPool中的线程会在空闲60秒自动回收,所以不会消耗过多的资源。
但是打开任务管理器你会发现执行任务的同时内存会飙升到接近400M,因为每个线程都消耗了一部分内存,在5000个线程创建之后,内存消耗达到了峰值。
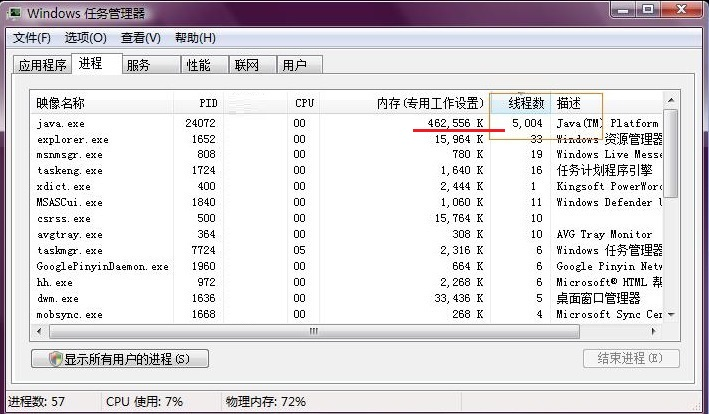
所以使用CacheThreadPool的时候应该避免提交大量长时间阻塞的任务,以防止内存溢出;另一种替代方案是,使用固定大小的线程池,并给一个较大的线程数(不会内存溢出),同时为了在空闲时节省内存资源,调用allowCoreThreadTimeOut允许核心线程超时。
线程执行栈的大小可以通过-Xsssize或-XX:ThreadStackSize参数调整
5. 混合型任务
大多数任务并不是单一的计算型或IO型,而是IO伴随计算两者混合执行的任务——即使简单的Http请求也会有请求的构造过程。
混合型任务要根据任务等待阻塞时间与CPU计算时间的比重来决定线程数量:
比如一个任务包含一次数据库读写(0.1ms),并在内存中对读取的数据进行分组过滤等操作(5μs),那么线程数应该为80左右。
线程数与阻塞比例的关系图大致如下:
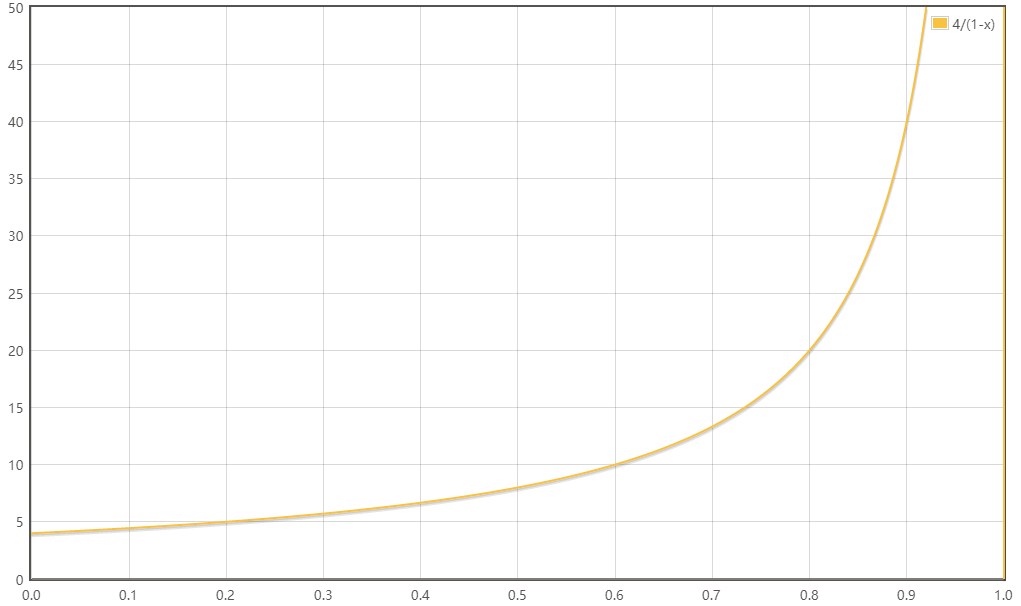
当阻塞比例为0,也就是纯计算任务,线程数等于核心数(这里是4);阻塞比例越大,线程池的线程数应该更多。
《Java并发编程实战》中最原始的公式是这样的:
$N{cpu}$代表CPU的个数,$U{cpu}$代表CPU利用率的期望值($0<U_{cpu}<1$),$\frac{W}{C}$仍然是等待时间与计算时间的比例。
我上面提供的公式相当于目标CPU利用率为100%。
通常系统中不止一个线程池,所以实际配置线程数应该将目标CPU利用率计算进去。
6. 总结
线程池的大小取决于任务的类型以及系统的特性,避免“过大”和“过小”两种极端。线程池过大,大量的线程将在相对更少的CPU和有限的内存资源上竞争,这不仅影响并发性能,还会因过高的内存消耗导致OOM;线程池过小,将导致处理器得不到充分利用,降低吞吐率。
要想正确的设置线程池大小,需要了解部署的系统中有多少个CPU,多大的内存,提交的任务是计算密集型、IO密集型还是两者兼有。
虽然线程池和JDBC连接池的目的都是对稀缺资源的重复利用,但通常一个应用只需要一个JDBC连接池,而线程池通常不止一个。如果一个系统要执行不同类型的任务,并且它们的行为差异较大,那么应该考虑使用多个线程池,使每个线程池可以根据各自的任务类型以及工作负载来调整。
清山绿水始于尘,博学多识贵于勤。
我有酒,你有故事吗?
微信公众号:「Java编程大本营」。
欢迎一起谈天说地,聊Java。 回复「vip课程」,获取一套价值19820 元的 java vip课程
- END

















 170万+
170万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









