




 Zookeeper是一种集中服务,用于维护配置信息、命名、提供分布式同步及组服务。它有助于简化分布式应用开发,通过提供统一的配置管理、命名服务等功能,增强应用的稳定性和可管理性。本文介绍了Zookeeper的基本原理、存储结构、功能及应用场景。
Zookeeper是一种集中服务,用于维护配置信息、命名、提供分布式同步及组服务。它有助于简化分布式应用开发,通过提供统一的配置管理、命名服务等功能,增强应用的稳定性和可管理性。本文介绍了Zookeeper的基本原理、存储结构、功能及应用场景。
Zookeeper
简介
Apache Zookeeper致力于开发和维护开源服务器,实现高度可靠的分布式协调
Zookeeper是一种集中式服务,用于维护配置信息,命名,提供分布式同步和提供组服务。所有这些类型的服务都一分布式应用程序的某种形式使用。每次实施他们都需要做很多工作来修复不可避免的错误和竞争条件。由于难以实现这些类型的服务,应用程序最初通常会吝啬它们,这使得它们在变化的情况下边的脆弱并且难以管理。即使正确完成,这些服务的不同实现也会在部署应用程序时导致管理复杂性
存储结构
目录树结构
功能
(1)存储数据
(2)监听
应用场景
(1)集群统一配置管理
(2)集群统一命名服务
(3)集群统一管理
(4)服务器的动态上下线感知
(5)负载均衡
节点状态信息
(1)czxid:导致创建此znode的更改的zxid
(2)ctime:创建此znode时从纪元开始的时间(以毫秒为单位)
(3)mZxid:最后修改此znode的更改的zxid
(4)mtime:上次修改此znode时的时间(以毫秒为单位)/p>
(5)pZxid:最后修改此znode的子项的更改的zxid
(6)dataVsersion:对此znode数据的更改次数
(7)cversion:此znode的子项的更改数
(8)aclVersion:对此znode的ACL的更改次数
(9)ephemeralOwner:如果znode是一个临时节点,则此znode的所有者的会话ID。如果它不是短暂的节点,则它将为零
(10)dataLength:此znode的数据字段的长度
(11)numChildren:此znode的子节点数
工作机制
基于观察者模式设计的分布式服务管理框架
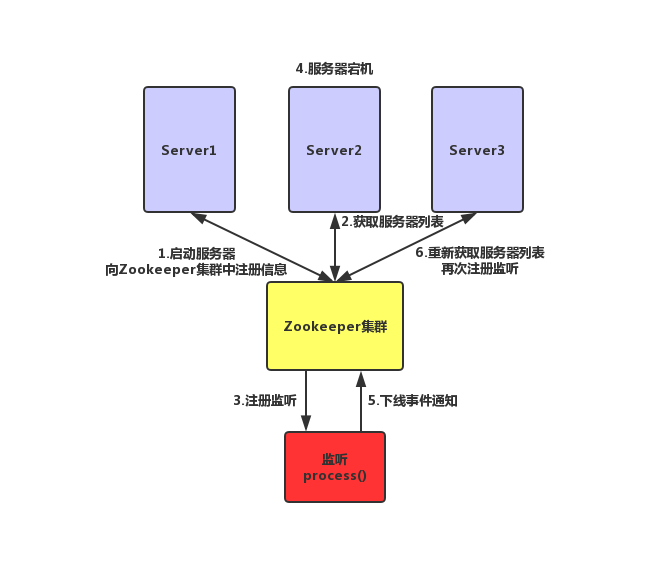
(1)启动服务器
(2)向Zookeeper集群中注册信息,创建临时节点
(3)Zookeeper获取当前服务器列表
(4)Zookeeper注册监听
(5)如果服务器宕机,临时节点就会消失
(6)监听就会向Zookeeper发送下线事件通知
(7)Zookeeper就会重新获取服务器列表
(8)Zookeeper再次注册监听
监听Watch
Watch是一次触发; 如果您收到观看活动并希望收到有关未来更改的通知,则必须设置另一个Watch
因为Watch是一次性触发器,并且在获取事件和发送新请求以获取Watch之间存在延迟,因此您无法可靠地看到ZooKeeper中的节点发生的每个更改。准备好处理znode在获取事件和再次设置监视之间多次更改的情况。(你可能不在乎,但至少意识到它可能会发生。)
对于给定通知,只会触发一次监视对象或函数/上下文对。例如,如果为同一个文件的exists和getData调用注册了相同的Watch对象,然后删除该文件,则只能使用该文件的删除通知调用Watch对象一次
当您断开与服务器的连接时(例如,当服务器发生故障时),在重新建立连接之前,您将不会获得任何监视。因此,会话事件将发送给所有优秀的手表处理程序。使用会话事件进入安全模式:断开连接时不会接收事件,因此您的过程应该在该模式下保守地执行

















 9375
9375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









