






深刻解读6大设计原则和28种设计模式的准确定义、应用方法和最佳实践,全方位比较各种同类模式之间的异同,详细讲解组合使用不同模式的方法、
特色:
- 简单、通俗、易懂,但又不肤浅,这是本书的最大特色。
- 理念:像看小说一样阅读本书。
总览:
由于pdf的内容太多,篇幅有限制。有想获取完整版笔记的朋友:关注我并帮忙转发此文,扫描小编的我二维码即可免费领取!!

详细目录介绍:

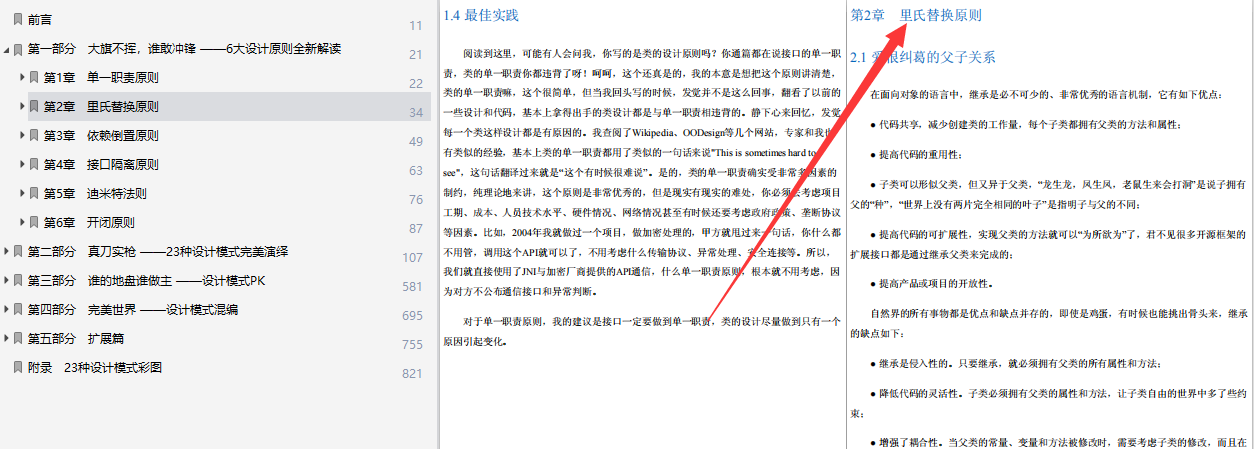

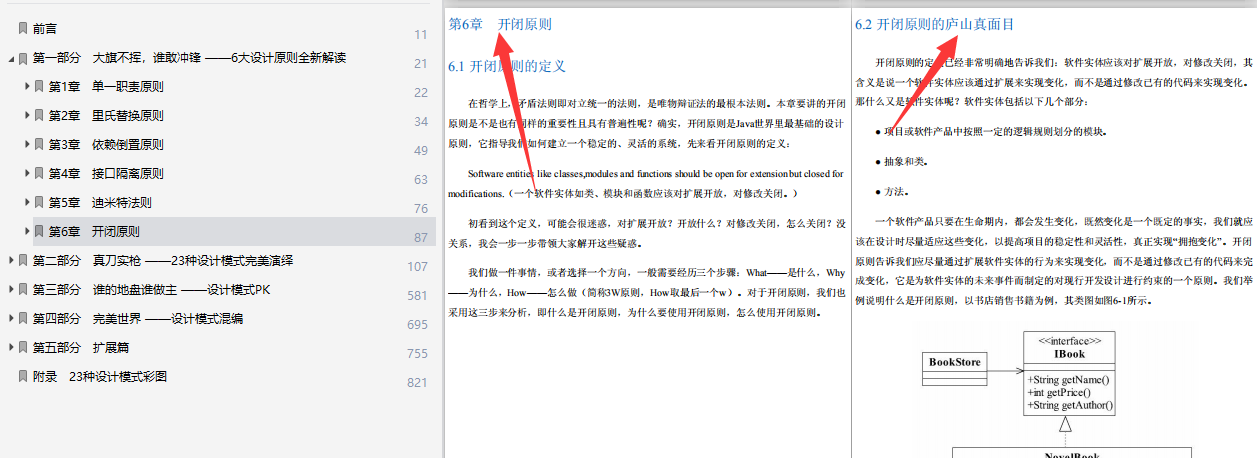
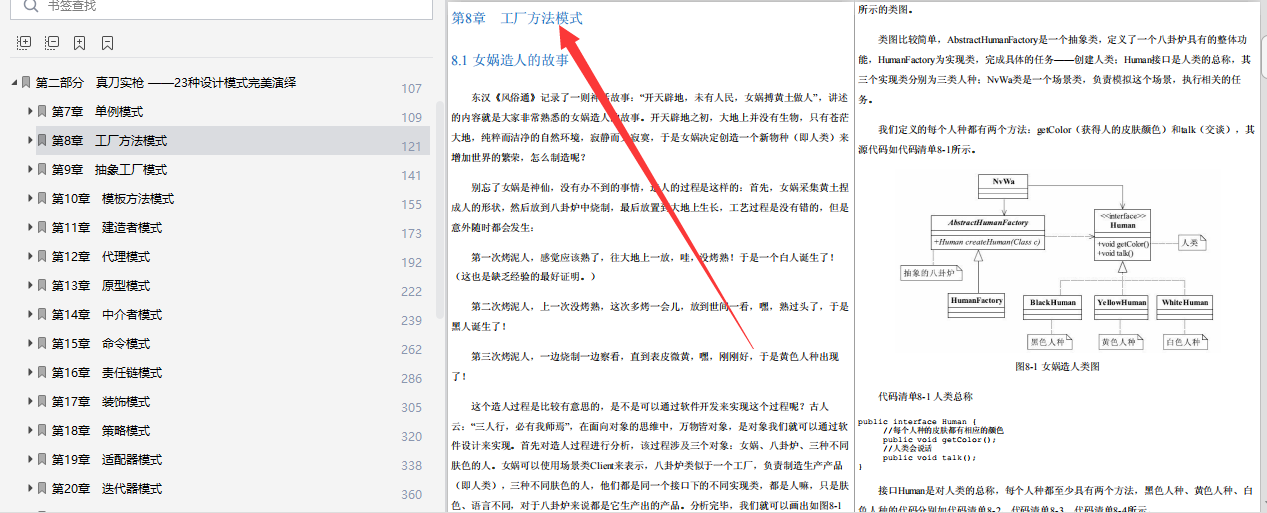
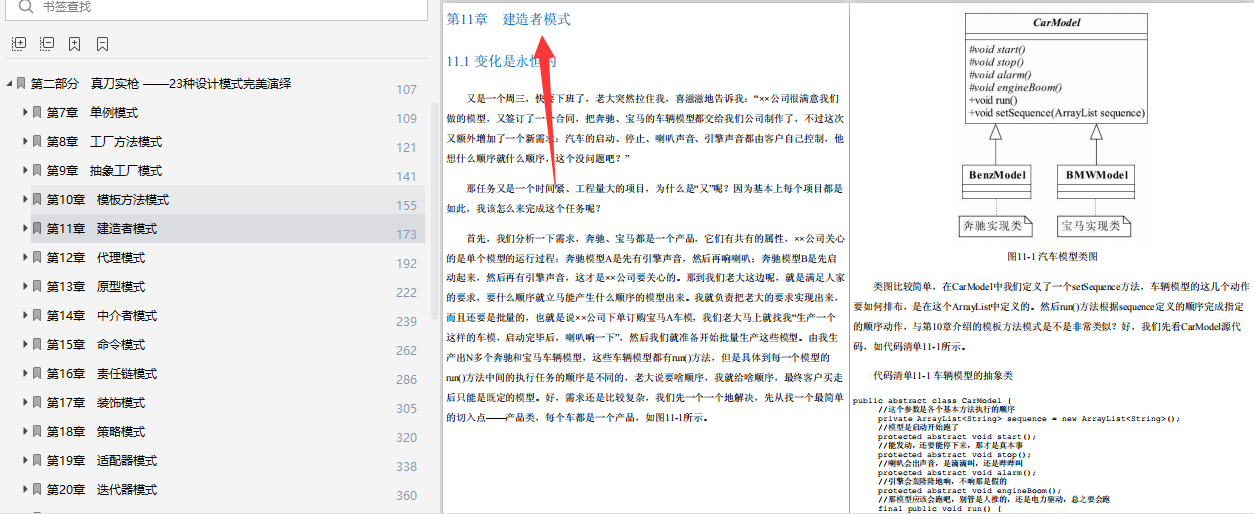



 这篇博客深入探讨了6个核心的设计原则和28种设计模式,提供了详细的定义、应用示例及最佳实践。文章以通俗易懂的方式阐述,适合程序员进阶学习。博主分享了获取完整版笔记的途径。
这篇博客深入探讨了6个核心的设计原则和28种设计模式,提供了详细的定义、应用示例及最佳实践。文章以通俗易懂的方式阐述,适合程序员进阶学习。博主分享了获取完整版笔记的途径。
深刻解读6大设计原则和28种设计模式的准确定义、应用方法和最佳实践,全方位比较各种同类模式之间的异同,详细讲解组合使用不同模式的方法、
特色:
由于pdf的内容太多,篇幅有限制。有想获取完整版笔记的朋友:关注我并帮忙转发此文,扫描小编的我二维码即可免费领取!!
 307
2191
448
3387
3319
298
307
2191
448
3387
3319
298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























