



 本文深入探讨了在TensorFlow中实现多GPU数据并行训练的详细步骤与代码实现,重点讲解了如何分配数据和计算任务,以及如何平均梯度进行参数更新。
本文深入探讨了在TensorFlow中实现多GPU数据并行训练的详细步骤与代码实现,重点讲解了如何分配数据和计算任务,以及如何平均梯度进行参数更新。
tensorflow使用多个gpu训练
关于多gpu训练,tf并没有给太多的学习资料,比较官方的只有:tensorflow-models/tutorials/image/cifar10/cifar10_multi_gpu_train.py
但代码比较简单,只是针对cifar做了数据并行的多gpu训练,利用到的layer、activation类型不多,针对更复杂网络的情况,并没有给出指导。自己摸了不少坑之后,算是基本走通了,在此记录下
一、思路
单GPU时,思路很简单,前向、后向都在一个GPU上进行,模型参数更新时只涉及一个GPU。多GPU时,有模型并行和数据并行两种情况。模型并行指模型的不同部分在不同GPU上运行。数据并行指不同GPU上训练数据不同,但模型是同一个(相当于是同一个模型的副本)。在此只考虑数据并行,这个在tf的实现思路如下:
模型参数保存在一个指定gpu/cpu上,模型参数的副本在不同gpu上,每次训练,提供batch_size*gpu_num数据,并等量拆分成多个batch,分别送入不同GPU。前向在不同gpu上进行,模型参数更新时,将多个GPU后向计算得到的梯度数据进行平均,并在指定GPU/CPU上利用梯度数据更新模型参数。
假设有两个GPU(gpu0,gpu1),模型参数实际存放在cpu0上,实际一次训练过程如下图所示:
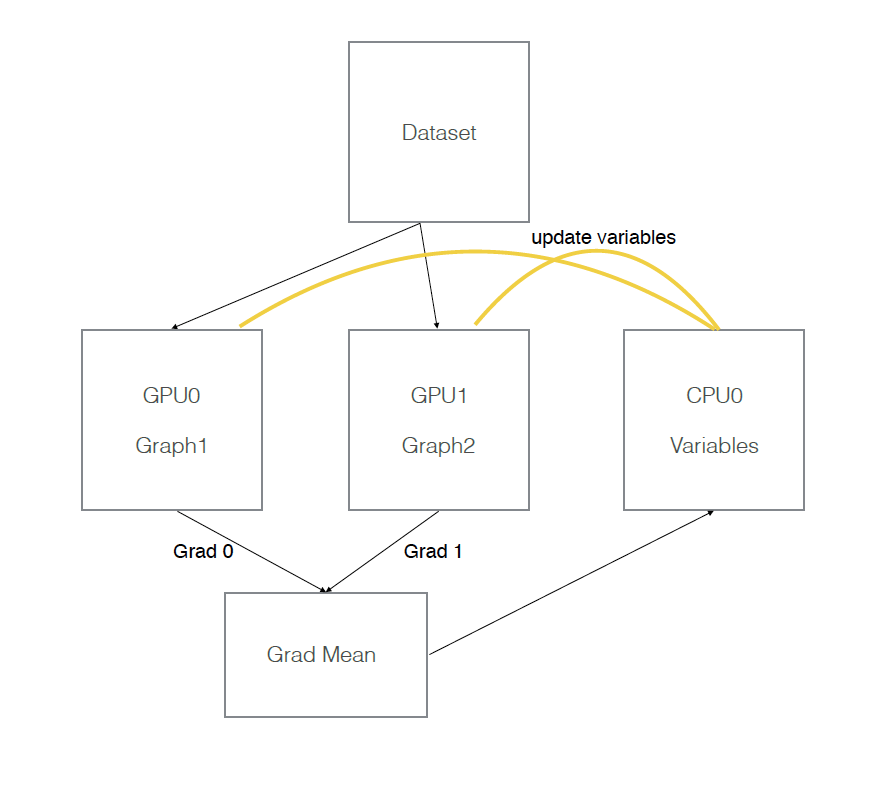
二、tf代码实现
大部分需要修改的部分集中在构建计算图上,假设在构建计算图时,数据部分基于tensorflow1.4版本的dataset类,那么代码要按照如下方式编写:

1 next_img, next_label = iterator.get_next()
2 image_splits = tf.split(next_img, num_gpus)
3 label_splits = tf.split(next_label, num_gpus)
4 tower_grads = []
5 tower_loss = []
6 counter = 0
7 for d in self.gpu_id:
8 with tf.device('/gpu:%s' % d):
9 with tf.name_scope('%s_%s' % ('tower', d)):
10 cross_entropy = build_train_model(image_splits[counter], label_splits[counter], for_training=True)
11 counter += 1
12 with tf.variable_scope("loss"):
13 grads = opt.compute_gradients(cross_entropy)
14 tower_grads.append(grads)
15 tower_loss.append(cross_entropy)
16 tf.get_variable_scope().reuse_variables()
17
18 mean_loss = tf.stack(axis=0, values=tower_loss)
19 mean_loss = tf.reduce_mean(mean_loss, 0)
20 mean_grads = util.average_gradients(tower_grads)
21 update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
22 with tf.control_dependencies(update_ops):
23 train_op = opt.apply_gradients(mean_grads, global_step=global_step)
第1行得到image和对应label
第2-3行对image和label根据使用的gpu数量做平均拆分(默认两个gpu运算能力相同,如果gpu运算能力不同,可以自己设定拆分策略)
第 4-5行,保存来自不同GPU计算出的梯度、loss列表
第7-16行,开始在每个GPU上创建计算图,最重要的是14-16三行,14,15把当前GPU计算出的梯度、loss值append到列表后,以便后续计算平均值。16行表示同名变量将会复用,这个是什么意思呢?假设现在gpu0上创建了两个变量var0,var1,那么在gpu1上创建计算图的时候,如果还有var0和var1,则默认复用之前gpu0上的创建的那两个值。
第18-20行计算不同GPU获取的grad、loss的平均值,其中第20行使用了cifar10_multi_gpu_train.py中的函数。
第23行利用梯度平均值更新参数。
注意:上述代码中,所有变量(vars)都放在了第一个GPU上,运行时会发现第一个GPU占用的显存比其他GPU多一些。如果想把变量放在CPU上,则需要在创建计算图时,针对每层使用到的变量进行设备指定,很麻烦,所以建议把变量放在GPU上。


</div>
<div class="postDesc">posted @ <span id="post-date">2017-12-27 17:42</span> <a href="https://www.cnblogs.com/hrlnw/">handspeaker</a> 阅读(<span id="post_view_count">5575</span>) 评论(<span id="post_comment_count">0</span>) <a href="https://i.cnblogs.com/EditPosts.aspx?postid=7779058" rel="nofollow">编辑</a> <a href="#" onclick="AddToWz(7779058);return false;">收藏</a></div>
</div>

















 607
607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









