




 本文介绍了Pandas中Series的构造与简单使用。构造方式有使用列表和字典两种。简单使用包括values和index操作、元素级操作、isnull和notnull方法判断缺失值、设置name属性、强制改变索引,还介绍了按索引和值排序以及排名的方法。
本文介绍了Pandas中Series的构造与简单使用。构造方式有使用列表和字典两种。简单使用包括values和index操作、元素级操作、isnull和notnull方法判断缺失值、设置name属性、强制改变索引,还介绍了按索引和值排序以及排名的方法。
Pandas-Series
Series构造
1)使用列表构造
Series类似于一维数组,有一组数据及一组索引标签组成,
# -*- coding: utf-8 -*-
>>> import pandas as pd
>>> obj = pd.Series([4, 7, -5, 3])
>>> obj
0 4
1 7
2 -5
3 3
2)使用字典创建Series
传入一个字典对象,字典的见就是最终生成的Series的索引,
>>> sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
使用上面的字典构造Series,

Series简单使用
values和index操作
索引在左边,值在右边,没有指定的情况下会自动创建 0 — N-1的整数索引。Series的值和索引可以分别使用values方法和index方法获取,
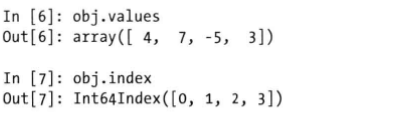
创建Series时,使用index参数能够指定Series的索引,但是索引的维度一定与Series的维度相同,

与numpy的数组相比,Series能够直接通过索引获取、修改某一个或多个元素,

元素级操作
Series数组也可以像numpy的数组一样进行元素级运算,运算后依旧能够保留之前的索引,

因为Pandas是基于numpy建立的,所以numpy的方法基本上都适用于Pandas的数据结构。
isnull和notnull方法
之前的字典创建Series的实例中存在缺失值,可以使用isnull方法或者notnull方法进行判断,

Series最重要的一个功能是在算数运算中自动对齐相同索引的数据。


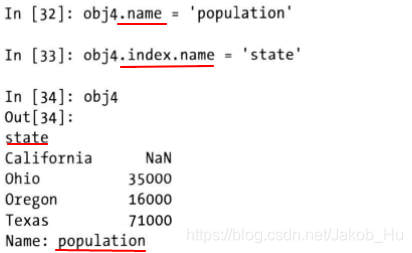
name属性
Series除了索引外,还可以给Series赋予一个name属性,name属性有两个,一个是整个Series的name属性;另一个是索引的name属性。
强制改变索引
已经存在的Series的索引可以通过强制的方式进行修改,
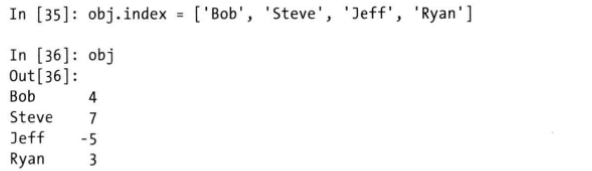
但是索引的维度与Series的维度要相同。
排序和排名
按索引排序
使用的是sort_index方法,该方法返回的是已排序的新对象。Series索引排序,方式很简单,因为只有一个维度,
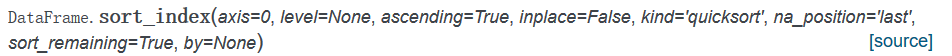

Series按索引进行排序时不需要使用axis参数。
按值排序
Series按值排序使用的是order方法,默认所有缺失值会被放到末尾,


排名
排名和排序唯一的不同在于,排名返回的是Series中各条记录的名次,名次的值从1开始,与numpy的argsort方法很相似,但是可以通过method参数指定的规则人为进行调整。
Series排名,使用的是rank方法,Series的axis如果取值为1,会报错,原因是维度不够。
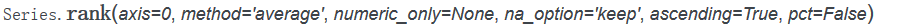

rank方法中method参数和na_option参数是很重要的,




在此区分一下 min和 max的区别,即相同的元素排序后名次相同,min是取小名次,而max是取大名次。



















 3426
3426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









