




 本文详细探讨了Python中的函数递归调用,包括直接和间接调用,并强调了设置终止条件的重要性。同时介绍了回溯和递推的概念,并提供了一个有趣的实例进行解释。接着讲解了三元表达式的使用,以及列表、字典和集合生成式如何简化代码。此外,还涉及了匿名函数的语法和二分查找算法的应用,强调了算法在提升查找效率上的优势。
本文详细探讨了Python中的函数递归调用,包括直接和间接调用,并强调了设置终止条件的重要性。同时介绍了回溯和递推的概念,并提供了一个有趣的实例进行解释。接着讲解了三元表达式的使用,以及列表、字典和集合生成式如何简化代码。此外,还涉及了匿名函数的语法和二分查找算法的应用,强调了算法在提升查找效率上的优势。
函数递归调用
函数递归调用就是指在调用一个函数的过程中,又直接或者间接的调用了该函数本身,这种调用就称做“函数的递归调用“。
-
直接调用函数本身:调用
func1的过程中又调用了func1.count = 1 def func1(): print('from index') global count count += 1 print(count) func1() index()图解:
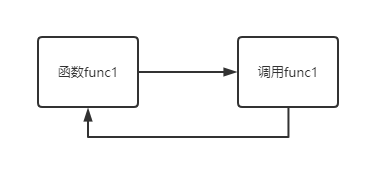
-
间接调用函数本身:在调用
func1的过程中,会调用func2,在调用func2的过程中又会调用func1.def func1(): print('from func1') func2() def func2(): print('from func2') func1() func1()图解:
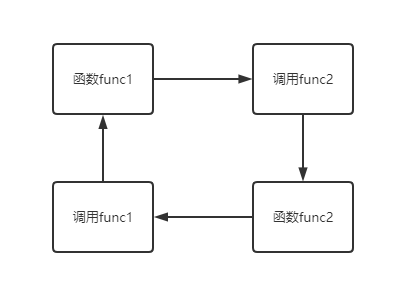
-
函数的递归调用,如果不设置结束条件是会无限循环下去的,这样会抛出异常,为了避免,因此要设定在满足某种条件下就终止。
补充:系统默认递归调用深度为1000次,但是我们可以通过系统的方法来修改和查看递归调用深度。
-
查看递归调用的默认深度
import sys print(sys.getrecursionlimit()) # 1000 -
修改递归调用的默认深度
import sys print(sys.getrecursionlimit()) # 修改前为1000 sys.setrecursionlimit(2000) print(sys.getrecursionlimit()) # 修改后为2000
回溯与递推
引例:老师问四个学生1,2,3,4的考试成绩,学生4说自己的成绩比学生3高10分,学生3说自己的成绩比学生2高10分,学生2说自己的成绩比学生1高10分,学生1说自己的成绩为66分,请问学生1,2,3,4四个学生的成绩分别为多少?
分析:要想知道学生4的成绩就得知道学生3的成绩,要想知道学生3的成绩就得知道学生2的成绩,以此类推,我们可以得到下面的表达式:
score(4) = score(3) + 10
score(3) = score(2) + 10
score(2) = score(1) + 10
score(1) = 66
结论: score(n) = score(n-1) + 10
代码实现:
def score(n):
if n == 1:
return 66
return score(n-1) + 10
print(score(4)) # 96
总结:我们将从学生4成绩的得出过程,通过推导,找到学生1成绩(也就是终止条件)的过程称为“回溯”;将通过学生1的成绩推导学生4的成绩的过程称为“递推”。
图解:
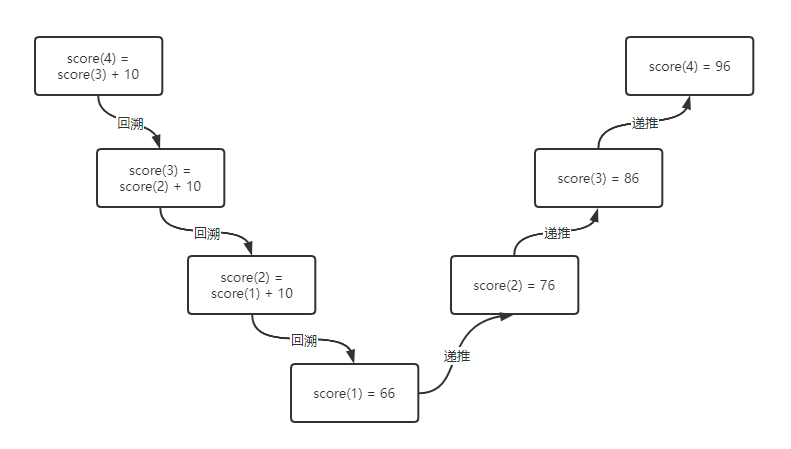
练习题:逐个打印列表l中的值:l = [1, [2, [3, [4, [5, [6, [7, [8, [9, [10, ]]]]]]]]]]
l = [1, [2, [3, [4, [5, [6, [7, [8, [9, [10, ]]]]]]]]]]
# 第一种方式:
# 第一种方式:
for i in l:
if type(i) is int:
print(i)
else:
# 说明当前循环的数据类型是列表
for j in i:
# 判断j是什么类型
if type(j) is int:
print(j)
else:
# 说明当前循环的数据类型是列表
for k in j:
if type(k) is int:
print(k)
else:
# 说明当前循环的数据类型是列表
for x in k:
if type(x) is int:
print(x)
...
# 很显然方式一的代码重复很多,因此我们采用函数递归的方式
# 第二种方式:函数递归调用
def get_num(l):
for i in l:
if type(i) is int:
print(i)
else:
get_num(i)
get_num(l)
三元表达式
三元表达式是python对于if双分支结构的一种代码简化。
- 传统写法
def my_max(a, b):
if a > b:
return a
else:
return b
print(my_max(1, 2))
- 使用三元表达式写法
a = 1111
b = 211
res = a if a > b else b
print(res)
# 本质就是传统的写法,只是对代码进行简化
练习题:
a = 1111
b = 2111
username = 'mark'
res = a if a > b else ('world' if False else ('靓仔' if username == 'mark' else '小伙子'))
print(res)
# 让用户输入判断
cmd = input('username:').strip()
res = '靓仔' if cmd == 'mark' else '小伙子'
print(res)
列表生成式
列表生成式是python对于生成列表的方式,是简化代码的解决方案。
- 传统写法:
# 题目:生成一个新列表,内容为愿列表中所有元素拼接plus字符串
phone_list = ['huawei', 'vivo', 'iphone']
new_phone_list = []
for i in phone_list:
new_phone_list.append(i +'plus')
print(new_phone_list)
- 使用列表生成式:
new_phone_list = [i + 'plus' for i in phone_list]
print(new_phone_list)
练习:为列表中的元素为’huawei’的元素添加plus,其余元素添加 ’++‘
# 传统写法:
new_phone_list = []
for i in phone_list:
if i != 'huawei':
new_phone_list.append(i+'++')
else:
new_phone_list.append(i + 'plus')
# 列表生成式实现:
new_phone_list = [i + '++' if i != 'huawei' else i + 'plus' for i in phone_list]
print(new_phone_list)
字典生成式、集合生成式、生成器
l1 = ['name', 'age', 'hobby']
l2 = ['mark', 18, 'music']
# 传统写法:
new_dict = {}
for i in range(len(l1)):
new_dict[l1[i]] = l2[i]
print(new_dict)
# 字典生成式
res = {l1[i]: l2[i] for i, j in enumerate(l1)}
print(res)
# 执行结果:{'name': 'mark', 'age': 18, 'hobby': 'music'}
# 集合生成式
res = {l1[i] for i, j in enumerate(l1)}
print(res)
# 执行结果:{'hobby', 'age', 'name'}
# 生成器
res = (l1[i] for i, j in enumerate(l1))
print(res)
# 执行结果:<generator object <genexpr> at 0x000001C2687A5F90> 表示一个生成器对象,通过next()方法来生成元素
print(next(res))
# name
补充:
# 枚举
l1 = ['name', 'age', 'hobby']
for i,j in enumerate(l1, start=2):
print(i,j)
# 执行结果:
2 name
3 age
4 hobby
匿名函数
即没有名字的函数。
-
语法格式:
lambda 参数:返回值 -
示例:
def index(x): return x ** 2 print(index) print((lambda x:x**2)(2)) res = lambda x:x**2 print(res(2)) # 但目的不是这样用的,一般情况下不会单独使用匿名函数 # 会结合一些内置函数来使用 # map函数 l = [1, 2, 3, 4, 5, 6] res=list(map(lambda x:x**3, l)) print(res) # 执行结果:[1, 8, 27, 64, 125, 216]
算法之二分法
二分法查找相比较与for循环来讲,查找效率大大提升,这就体现出了算法的优越性。
- 前提条件:列表有序
- 示例:查找元素66,返回是否找到
l = [1, 2, 3, 4, 5, 6, 11, 22, 34, 44, 55, 66, 67, 333, 444]
# 方式一:for循环查找,挨个比对,需要在进行第12次比对结果才会停止
for i in l:
if i == 66:
print('找到了')
break
# 方式二:利用二分法查找,递归两次就可结束,效率大大提升
# 1. 先进行排序
l.sort()
def my_half(target_num, l):
# 1. 从列表中去一个中间值
middle_index = len(l) // 2
# 2. 比较
if target_num > l[middle_index]:
# 要找的元素在右边
l_right = l[middle_index + 1:]
my_half(target_num, l_right)
print(l_right)
elif target_num < l[middle_index]:
# 要找的元素一定在左边
l_left = l[:middle_index]
my_half(target_num, l_left)
print(l_left)
else:
print('找到了,哈哈哈哈')
my_half(66,l)

















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









