






前言
先上代码,带引包就24行代码,简单易懂,适合小白
一、上模板代码
import requests
from lxml import etree
import time
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36'
}
url = 'https://www.baidu.com'
# while 1:
r = requests.get(url=url,headers=headers).text
e = etree.HTML(r)
div_list = e.xpath('//*[@id="articleMeList-blog"]/div[2]/div')
href_list = []
for div in div_list:
href = div.xpath('./h4/a/@href')[0]
href_list.append(href)
while 1:
for i in range(len(href_list)):
visit = href_list[i]
page = requests.get(url=visit,headers=headers).text
tree = etree.HTML(page)
count = tree.xpath('//span[@class="read-count"]/text()')[0]
print(count)
time.sleep(5)
二、讲解
1.找到需要的网址
然后用request.get访问,然后获取值
url = 'https://www.baidu.com'
# while 1:
r = requests.get(url=url,headers=headers).text
啥都别问,盘它就对了
2.找到Xpath的值
怎么找?
F12→鼠标右键→获取Xpath
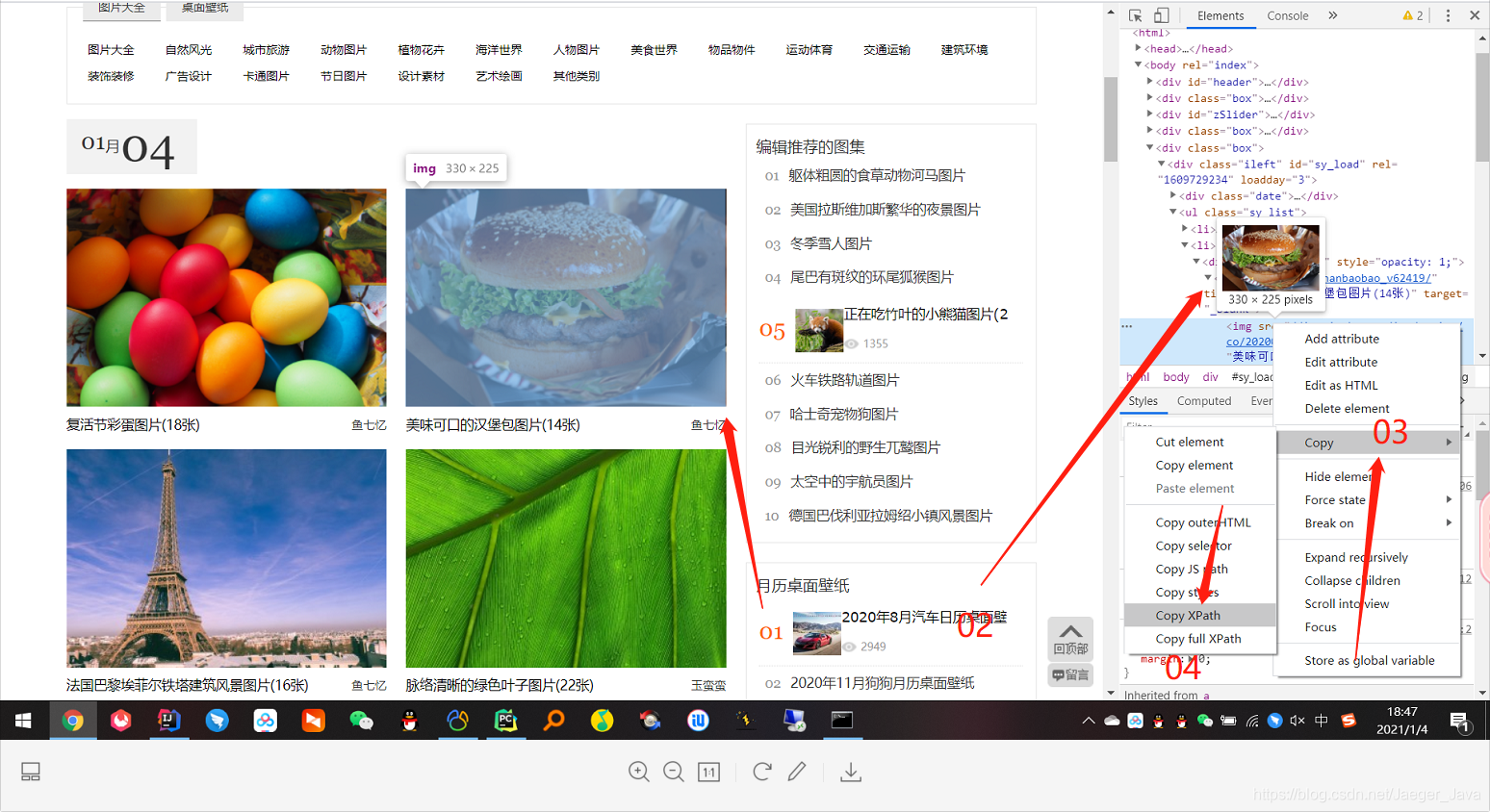
看不懂?那就别往下看了
3.替换Xpath
div_list = e.xpath('//*[@id="articleMeList-blog"]/div[2]/div')
4.组装
href_list = []
for div in div_list:
href = div.xpath('./h4/a/@href')[0]
href_list.append(href)
5.运行
总结
说白了,利用XPath爬数据跟bs4的find_all差不多,都是先定位到地方,找到集合,然后一行一行怼就完了


















 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









