




 本文深入探讨Java集合类如Stack、LinkedList、LinkedHashMap的工作原理,对比分析HashMap、HashTable及ConcurrentHashMap在存储机制、线程安全性及性能上的区别。
本文深入探讨Java集合类如Stack、LinkedList、LinkedHashMap的工作原理,对比分析HashMap、HashTable及ConcurrentHashMap在存储机制、线程安全性及性能上的区别。
1、stack 继承vector,是synchronized
2、LinkedList的底层Node,是双链表,同时实现了Deque(双端队列),所以也有了stack的功能
https://www.cnblogs.com/yakovchang/p/java_linkedlist.html
3、LinkedHashMap的底层Entry,也是双链表
https://www.imooc.com/article/22931
一张图让你看清Java集合类(Java集合类的总结)
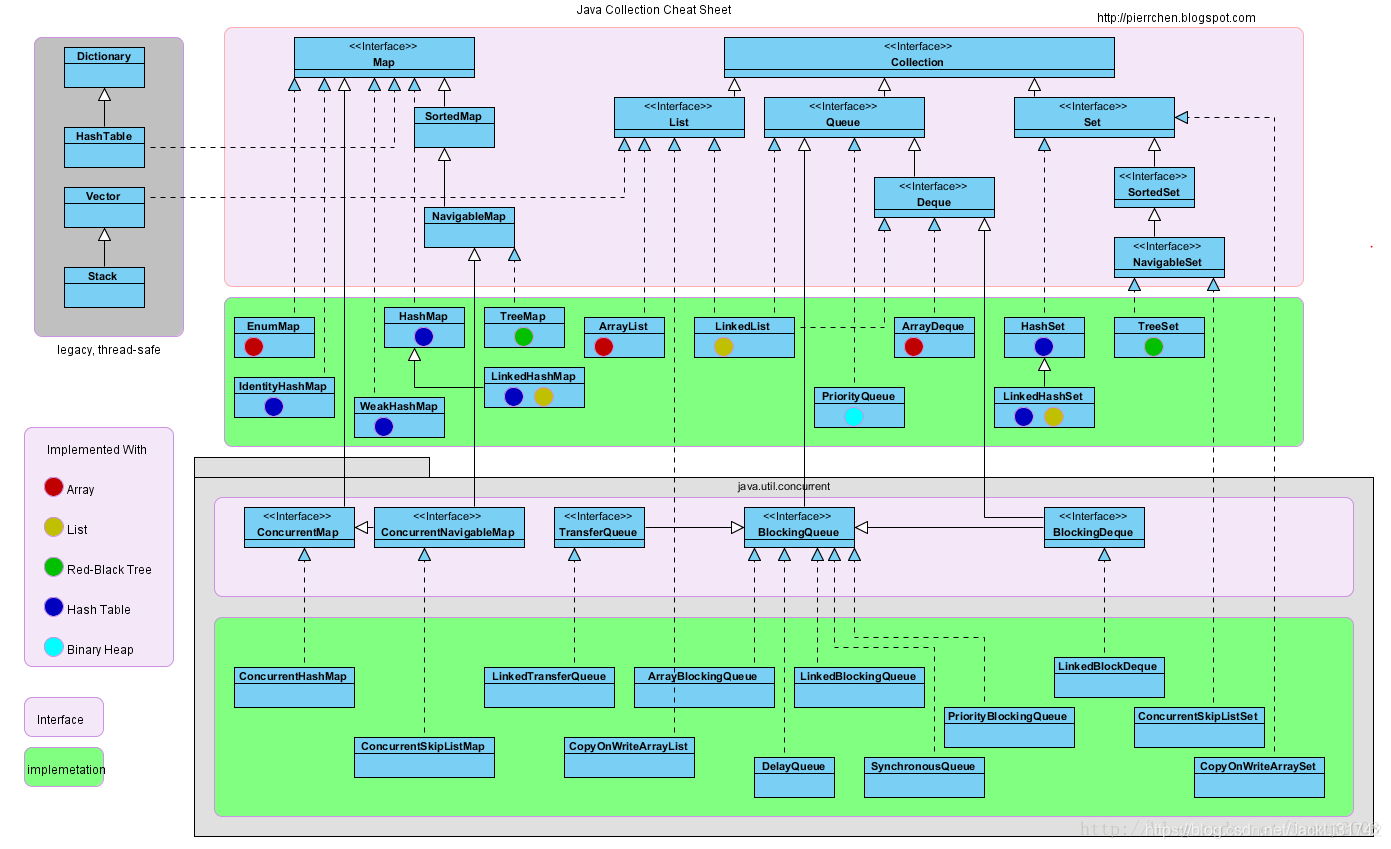
https://blog.youkuaiyun.com/iamzp2008/article/details/38151971
java集合系列——Set之HashSet和TreeSet介绍
https://blog.youkuaiyun.com/u010648555/article/details/60573808
Java中的排序比较方式:自然排序和比较器排序
https://crazylittle-163-com.iteye.com/blog/513900
hashmap和hashtable的区别
HashTable
底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相关优化
HashMap
底层数组+链表实现,可以存储null键和null值,线程不安全
ConcurrentHashMap
底层采用分段的数组+链表实现,线程安全
通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于HashEntry的value变量是 volatile的,也能保证读取到最新的值。)
Hashtable的synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术
在HashMap中,null可以作为键,这样的键只有一个,但可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示HashMap中没有该key,也可以表示该key所对应的value为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个key,应该用containsKey()方法来判断。
ConcurrentHashMap比HashMap多出了一个类Segment,而Segment是一个可重入锁。
初始容量不同
Hashtable的初始长度是11,之后每次扩充容量变为之前的2n+1(n为上一次的长度)
而HashMap的初始长度为16,之后每次扩充变为原来的两倍
https://blog.youkuaiyun.com/yu849893679/article/details/81530298

















 4063
4063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









