




相关链接
0. 简单分析
数据库太大放不进内存,所以需要一个“缓冲池”(Pool Manager),这个Project就是实现这个东西,不过和往年差距挺大的,也不写LRU-K了,整体分为三个Task
- 实现一个ARC调度策略
- 实现一个磁盘调度器
- 实现Buffer Pool Manager
我们一步步来
1. Task #1 - Adaptive Replacement Cache (ARC) Replacement Policy
基本概念
这次的Lab不是简单写一个LRU就完事了,而是让你实现一个ARC,这是一种综合LRU和LFU的自适应算法,
简单来说,我们知道LRU是踢最早使用的页、LFU是踢使用最少的页,而ARC做的事就是将缓存分为两个部分:
- T1(MRU): 最近只访问过 一次 的缓存
- T2(MFU): 最近访问过 多次 的缓存
同时为这两个缓存两个幽灵表(Ghost List),只记录key,不做真实缓存:
- B1: T1 的幽灵缓存,只存键,不存数据
- B2: T2 的幽灵缓存,只存键,不存数据
这样,当cache miss的时候,如果发现键在B1上,ARC就会考虑去提升T1的大小,如果在B2上,就会考虑提升T2的大小,从而实现动态调整LFU与LRU策略。
值得一提的是,我们的ARC还需要实现一个SetEvictable(),这个标记了一个页面是否可以被淘汰,它本身不是ARC的概念,是数据库用的,比如某个页面被Pin住,即便它是当前“最冷”的页面,我们也不能踢他,这意味着我们需要为它维护一个变量。
接口要求
首先我们需要写这两个文件

然后实现这几个接口:

简单看一下:
Size() -> size_t:返回当前可淘汰(evictable) 的 frame 数量,换言之,统计T1 / T2中evictable = true的frame,这个只用维护一个计数器变量,SetEvictable的时候更新它就行了SetEvictable(frame_id_t frame_id, bool set_evictable):控制一个frame的可移除性,顺便可以根据具体情况更新一下size计数器RecordAccess(frame_id_t frame_id, page_id_t page_id):ARC的核心逻辑,记录一个页面被访问Evict() -> std::optional<frame_id_t>:ARC的淘汰逻辑,返回被淘汰的frame_id,特别地,如果没有frame能被淘汰,返回std::nullopt,然后加进Ghost ListRemove(frame_id):用来在Manager删页时调用,手动从ARC中移除某一个frame
Q:注意到这里有两个“淘汰”函数,思考一下他们两个有什么区别呢?
A:个人理解:
Remove的指令是上层Manager调用的,是上层通知 A R C ARC ARC某个frame被淘汰了,因此这个页面不需要加入Ghost,而Evict的选择动作是 A R C ARC ARC自驱完成的, A R C ARC ARC自然需要把选择踢出的页面加入Ghost来学习
容量概念
我们的ARC有五种容量:
replacer_size_ | 缓冲区的总容量(capacity) |
| 四个列表的总长度 | 四个表加起来,最大可以到二倍replacer_size_ |
curr_size_ | 被标记为可移除的容量(也就是Size返回的东西) |
mru_target_size_(p) | 计划给MRU的容量,动态因子 |
mru_.size() | MRU当前的实际容量 |
page vs frame
注意到,我们的ARC同时维护了page_id和frame_id,简单解释一下,前者代表在磁盘(或者说数据库文件)中的编号,是磁盘层决定的东西,后者代表内存缓冲池中的编号,是一个物理位置编号,相当于Pool中的“槽位”,其中,我们的B1 / B2由于存的是被踢出来的页,都不在内存中,自然只能存一个page_id,而T1 / T2是用来具体踢出内存上的某个位置的,因此存的是frame_id,而我们的RecordAccess(frame_id, page_id)两者都要。
策略要求
然后RecordAccess有几种互斥情况:
-
缓存命中:把他挪到MFU的最前面去
-
B1命中:这意味着这个
page是LRU的,因此我们需要扩大p,具体而言:- 若 B1.size >= B2.size → p += 1
- 否则 → p += floor(B2.size / B1.size)
然后把
page放在T2的最前面(因为假设T1稍微大点这个页面没被踢,那它本来就该去T2了) -
B2命中:我们需要偏向
LFU,扩大MFU,也即缩小p,策略和前面一个差不多:- 若 B2.size >= B1.size → p -= 1
- 否则 → p -= floor(B1.size / B2.size)
最低不能低于0,然后把page放在T2的最前面
-
完全miss:把它加入T1的最前面,不过在这之前考虑:
- 当T1.size + B1.size == capacity,说明
LRU存太多了,删一个B1 - 如果四个列表的总大小达到了
2 * capacity,说明ARC满了,删一个B2
- 当T1.size + B1.size == capacity,说明
从这里我们可以看出,这个MFU实际上就是一个LRU-2而非LFU
淘汰策略
淘汰策略也比较简单:
- 当MRU.size < p,还未达到预期,从MFU中踢
- 否则,从MRU中踢
- 当期待淘汰的表没有可淘汰的,就从另一个中淘汰
- 如果另一个也没有,返回
std::nullopt
具体实现
终于到了具体实现了,思考一下数据结构的设计,首先,目前的 L L L和 B B B都是以链表的形式存储,我们暂时可以保持不变,而为了快速反查,模板为我们维护了两个这样的表:
std::unordered_map<frame_id_t, std::shared_ptr<FrameStatus>> alive_map_;
std::unordered_map<page_id_t, std::shared_ptr<FrameStatus>> ghost_map_;
其中的FrameStatus是个很冗杂的结构,定义了一大堆东西:
// TODO(student): You can modify or remove this struct as you like.
struct FrameStatus {
page_id_t page_id_;
frame_id_t frame_id_;
bool evictable_;
ArcStatus arc_status_;
FrameStatus(page_id_t pid, frame_id_t fid, bool ev, ArcStatus st)
: page_id_(pid), frame_id_(fid), evictable_(ev), arc_status_(st) {}
};
显然这里面的很多东西都是不必要的,比如对于
G
h
o
s
t
Ghost
Ghost压根就没有frame_id_这个概念,更别说什么evictable_了,因此我们最好分开管理,实现一个AliveInfo和GhostInfo,尽量简化结构、同时提升效率。
那么哪些信息是需要的、哪些信息是不需要的呢?我们可以一边实现一边看,我们从简单的开始:
Size()没什么好说的,直接返回curr_size_就行了,SetEvictable(frame_id_t frame_id, bool set_evictable)是给定一个frame_id置evictable,显然,我们的AliveInfo应当有一个evictable_,这个函数的实现也很简单;
Remove(frame_id_t frame_id),是删除一个frame_id(不加入
G
h
o
s
t
Ghost
Ghost),其中根据这个是不是
m
r
u
mru
mru决定从
L
1
L_1
L1删还是
L
2
L_2
L2删,这里就涉及两个需求:
- 判断
frame_id是否为 m r u mru mru:我们需要往AliveInfo里维护一个is_mru_变量 - 快速从
frame_id找到对应的节点:我们需要往AliveInfo里维护一个指向该节点的迭代器
有了这两个信息,我们的的删除就可以写成:
(info.is_mru_ ? mru_ : mfu_).erase(info.iter_);
接下来是核心逻辑RecordAccess,这里有一个文档没提到的坑是传入的frame_id对应的存储的page_id与传入的不一致,这意味着这次这个操作是在做覆盖,因此,我们还需要一个手段记录frame_id对应的page_id,于是我们的AliveInfo又多了一个字段;此外,注意到这里需要执行一次“将frame_id踢出alive”的逻辑,前面的Remove也需要执行一次这个逻辑,因此我们完全可以把这一段抽象出一个单独的内部函数复用。
接下来就是按前面提到的case实现就行了,不过需要小小提醒一点,在做“将frame移动到
L
2
L_2
L2头部”这个操作时没必要erase+insert,可以使用std::list的splice函数,如此在简洁语法的同时还保证了迭代器不会失效,也不会涉及到额外的内存释放与申请的开销:
mfu_.splice(mfu_.begin(), info.is_mru_ ? mru_ : mfu_, info.iter_);
info.is_mru_ = false; // 缓存命中后一定在 MFU 列表
此外,*命中
G
h
o
s
t
Ghost
Ghost*这个case中我们涉及到了删除
G
h
o
s
t
Ghost
Ghost节点以及判定某个
G
h
o
s
t
Ghost
Ghost节点是否为
m
r
u
mru
mru,自然地,我们需要为GhostInfo维护两个字段。
Evict()也是按照文档来就行了,这里我说一个小技巧,写到这里你可能发现代码中充斥着各种if-else嵌套,代码冗杂、逻辑混乱、形式丑陋、相当dirty,我们其实可以多抽象出引用将他们统一起来,以Evict()为例(隐去了删除的细节):
auto ArcReplacer::Evict() -> std::optional<frame_id_t> {
std::lock_guard<std::mutex> guard(latch_);
auto try_evict_from = [&](std::list<frame_id_t> &target_alive, std::list<page_id_t> &target_ghost,
bool is_mru) -> std::optional<frame_id_t> {};
bool is_mru = (mru_.size() >= mru_target_size_);
auto &target_alive = is_mru ? mru_ : mfu_;
auto &another_alive = is_mru ? mfu_ : mru_;
auto &target_ghost = is_mru ? mru_ghost_ : mfu_ghost_;
auto &another_ghost = is_mru ? mfu_ghost_ : mru_ghost_;
auto result = try_evict_from(target_alive, target_ghost, is_mru);
return result ? result : try_evict_from(another_alive, another_ghost, !is_mru);
}
通过抽象出target_*和another_*以及try_evict_from,极大提升了代码复用,关于选择那里,还可以借助结构化绑定:
auto &&[target_alive, another_alive, target_ghost, another_ghost] =
is_mru ? std::tie(mru_, mfu_, mru_ghost_, mfu_ghost_)
: std::tie(mfu_, mru_, mfu_ghost_, mru_ghost_);
这个就看个人码风了。
以及关于并行安全,每个公有接口挂把大锁即可,注意别挂到那个private函数上去了就行。
测试
至此,我们就完成了Task1,然后就跑一下这两个Test:
其中第一个测试需要手动删除test\buffer\arc_replacer_test.cpp中的两个DISABLED_标记方能启用

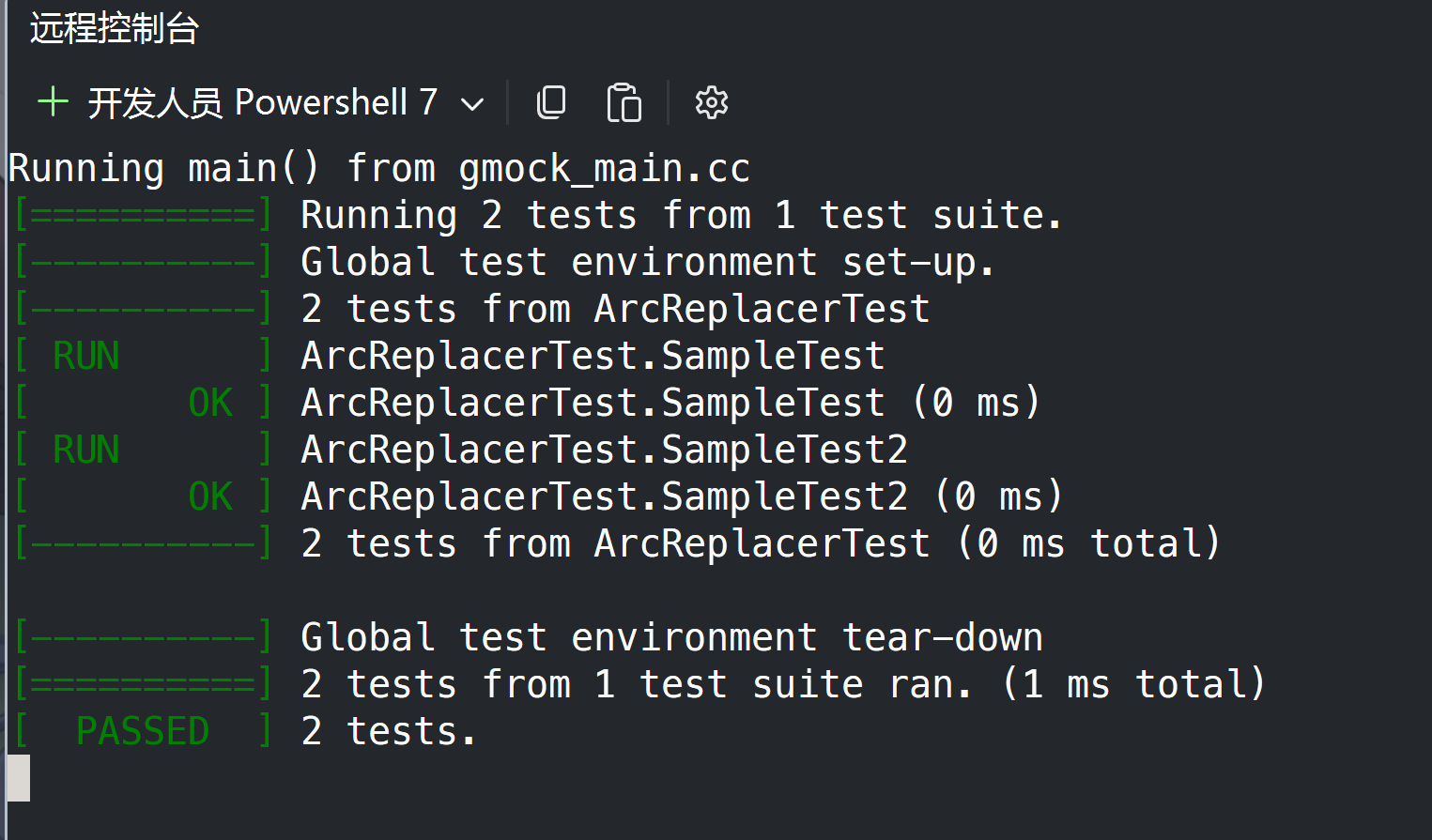
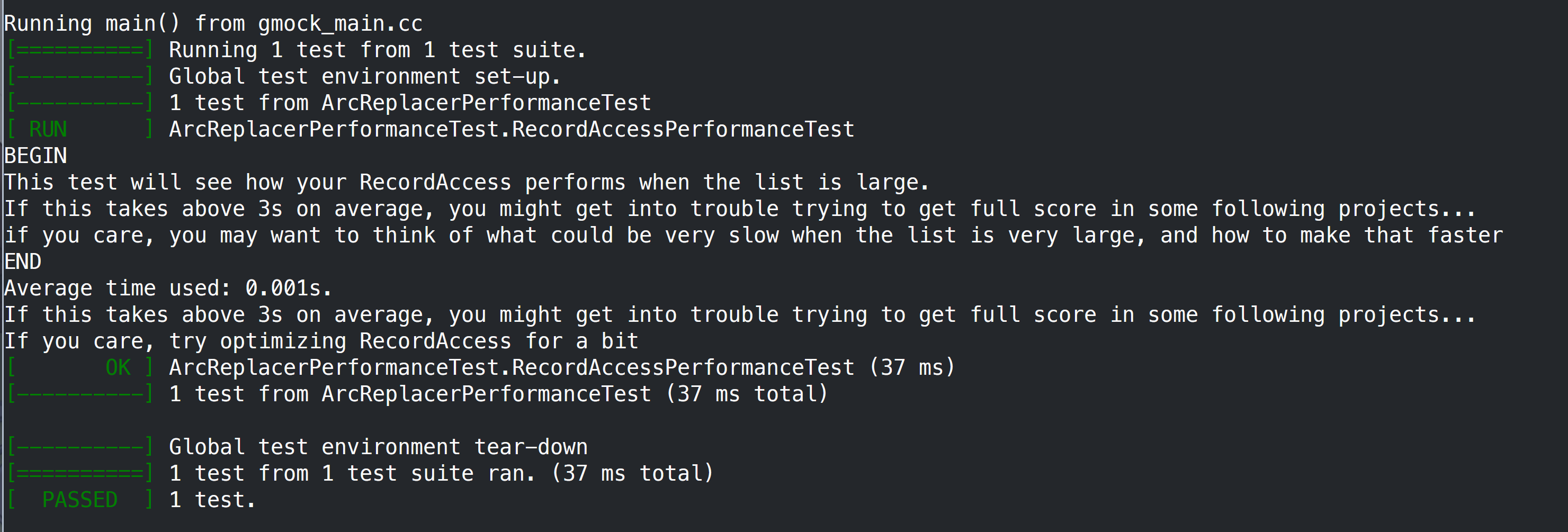
完成后,就可以打个commit:
2. Task #2 - Disk Scheduler

接下来开始实现Task2了,看起来要比Task1短不少
基本概念
刚刚我们实现了 A R C ARC ARC,这是一个页面替换策略器, B u f f e r P o o l M a n a g e r ( B P M ) BufferPoolManager(BPM) BufferPoolManager(BPM) 查找某个页,结果在页表中没有找到, c a c h e m i s s cache\ miss cache miss,缺页了,于是就要从磁盘(数据库文件)中去拿。
要去发送读盘的请求,而我们现在要实现的这个东西,是一个异步调度器,它不负责直接实现磁盘I/O的操作(这个工作由 D i s k M a n a g e r Disk\ Manager Disk Manager 负责),只关心“请求”本身。
某处发起读盘请求,它负责在适当的时候去执行这个请求,请求完成后,再异步通知调用者,这就是这个 D i s k S c h e d u l e r Disk\ Scheduler Disk Scheduler 干的事情。
而
B
P
M
BPM
BPM 拿到页面后,就会调用我们刚刚实现的
A
R
C
ARC
ARC 的RecordAccess更新内部状态,至此,完成了一次缺页处理。
接口要求
我们要实现的文件在这里:
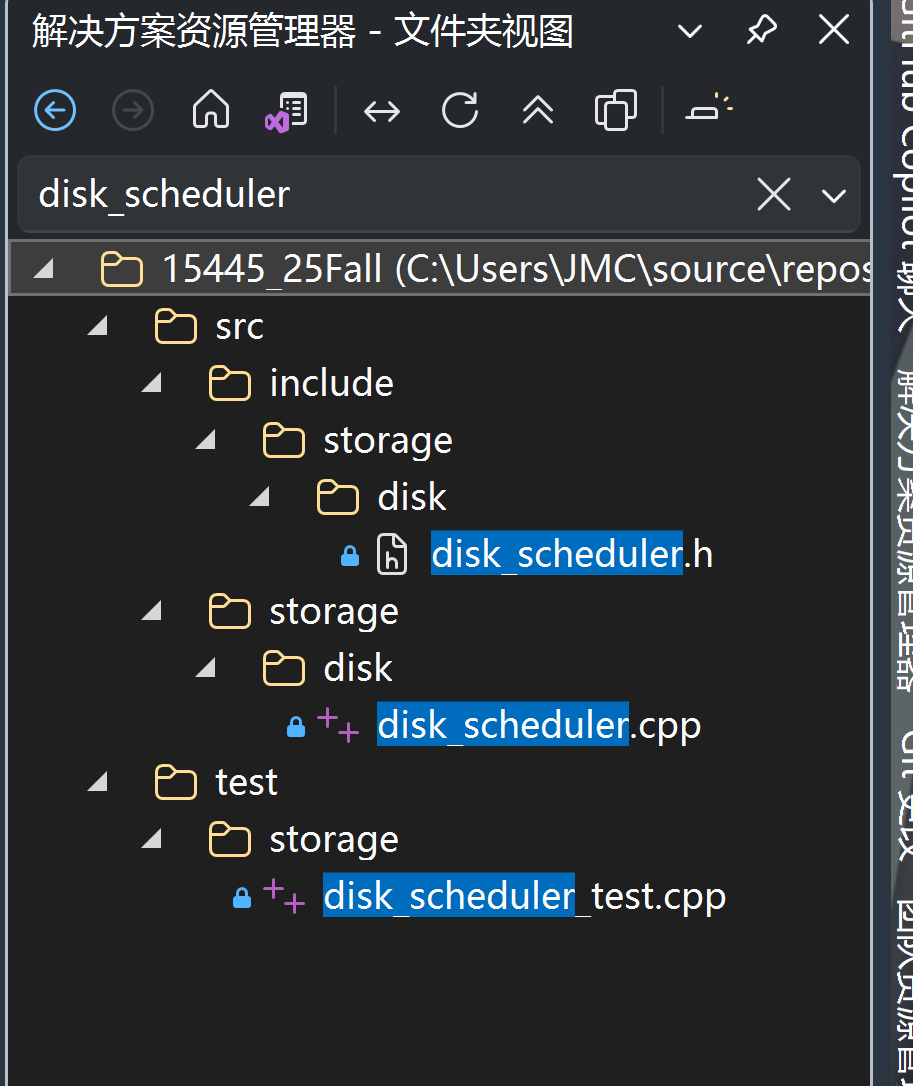
需要实现这几个接口:

Schedule(std::vector<DiskRequest> &requests):这个函数要做的事情很简单,就是收到一个DiskRequest的数组,然后把他们放进一个共享队列(项目提供了一个src/include/common/channel.h可用),没了StartWorkerThread():这个是这个Task的核心函数,是后台工作线程的启动方法,(在析构前)永不返回,阻塞处理消息队列中的请求,并分发给DiskManager(这里是调用DiskManager::ReadPage()和DiskManager::WritePage()处理读写),并在操作完成后通过请求中的promise/callback将结果返回给调用者。
提示:在实现时,要小心处理复制、移动、引用
测试
执行这个测试:
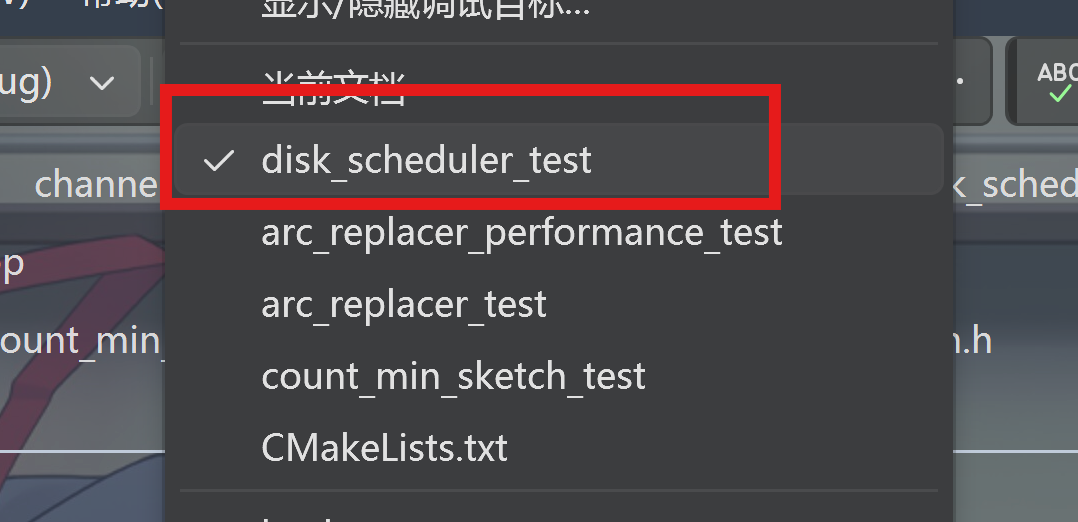
同样的,需要将这个测试启用

显示通过即可
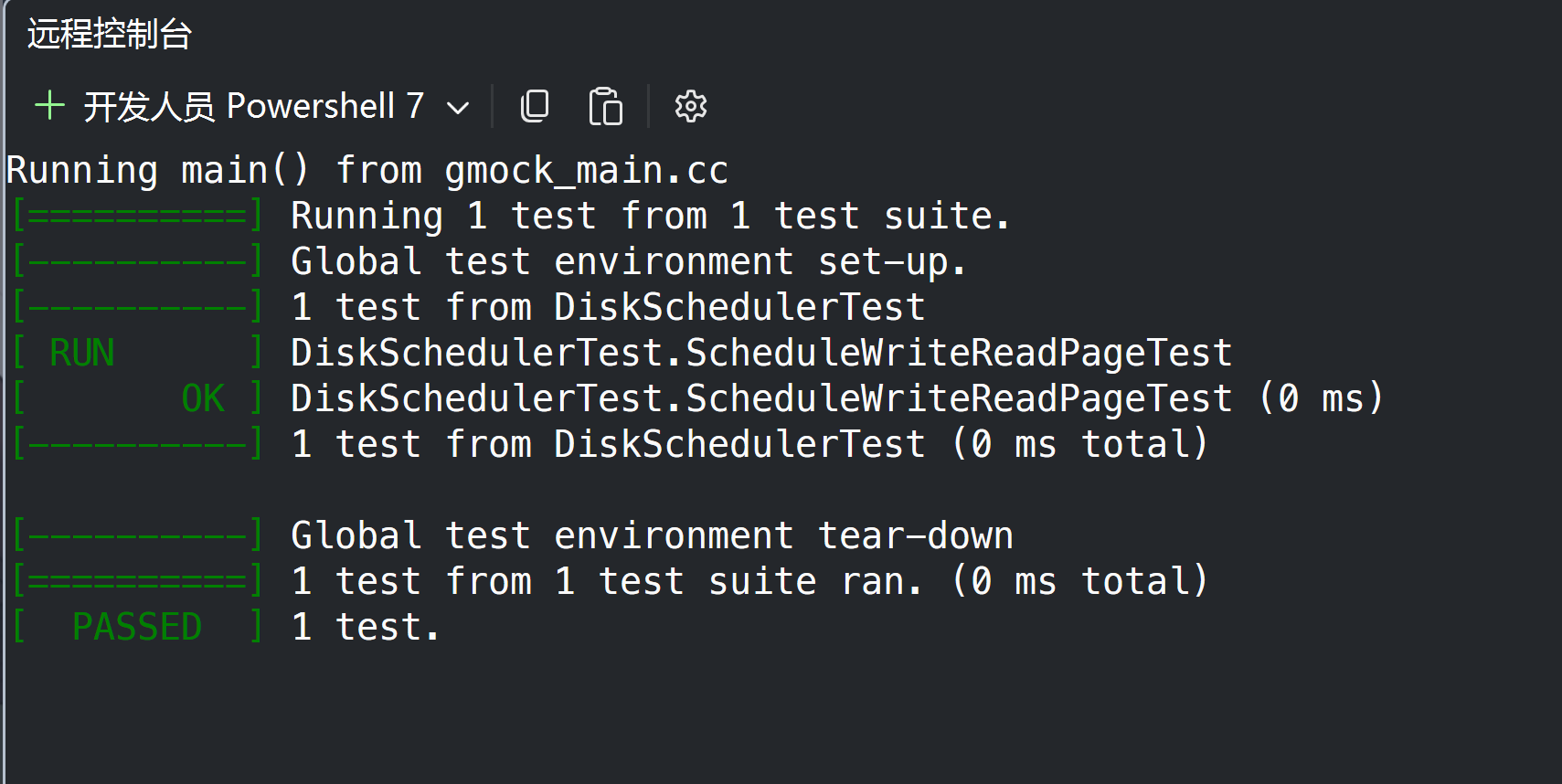
然后提交git,记得改文件编码为UTF-8。
3. Task #3 - Buffer Pool Manager
基本概念
终于来到了Project1的最终章,也是本次Project的核心部分,这个部分将用到前面写的 A R C ARC ARC 与 D S DS DS 此外,
还没写完,后面再接着写

















 1820
1820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









