






待优化sql
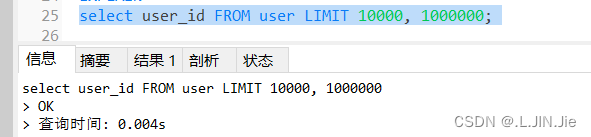
相同偏移量,不同数据量

数据不多,表现不太明显,但是总体是数据量越大,花费时间越长
相同数据量,不同偏移量
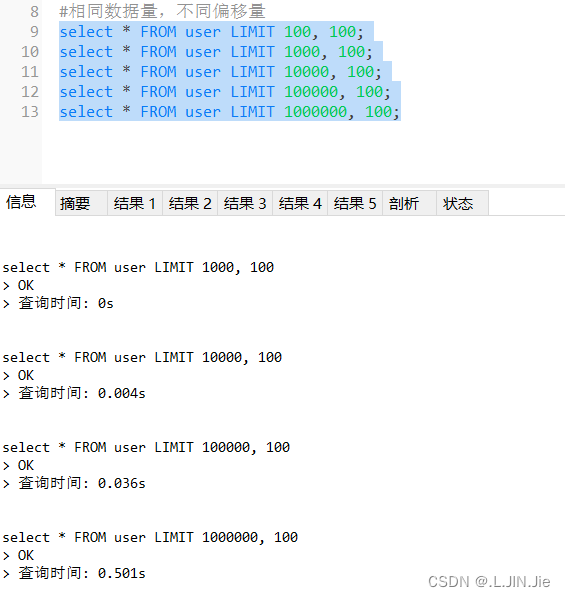
偏移量约大,花费时间越长
优化方案:
1.MySQL自身
2.网络io
3.sql自身
MySQL自身:
避免使用select *
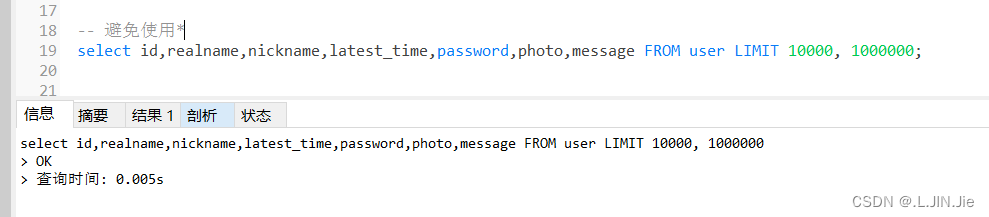
可以看出,不使用*,换字段查询,花费时间越短
这是避免了MySQL解析sql时将*转为所有字段的操作;
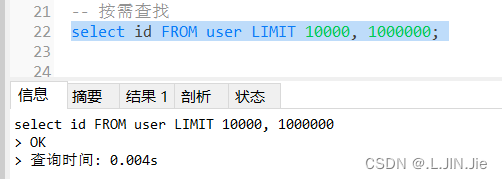
1.按需查找:
也可以减少花费时间
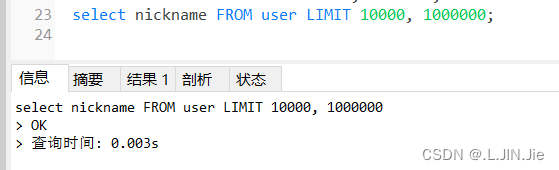
这里,对上面两个sql添加explain关键字进行sql分析
第一条,可以看出使用了索引(index),而且是主键索引(PRIMARY)
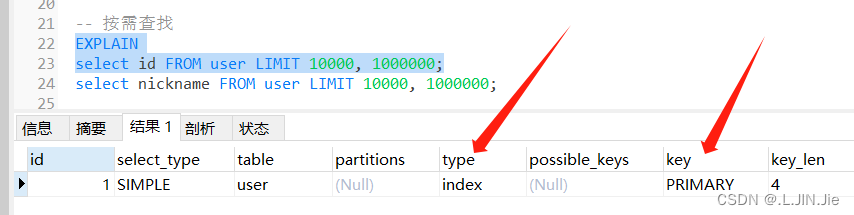
第二条,可以看出没用使用到索引,而是做了全表扫描,因为查询的字段没有索引约束
2. 覆盖索引:此时我们给user_id 这个字段添加索引
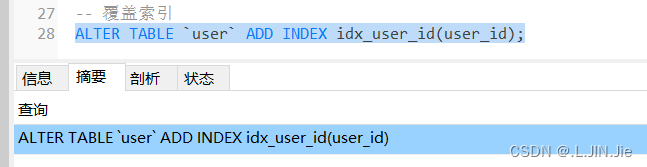
然后再看看原来第二条sql查询花费时间,看出会短些
我再次explain,可以看出已经使用到了索引,索引类型是idx_user_id

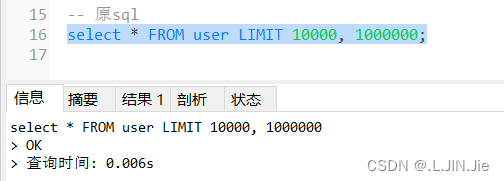
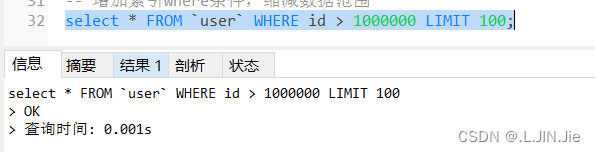
3.添加索引where条件,缩减数据范围
添加where:
原sql:
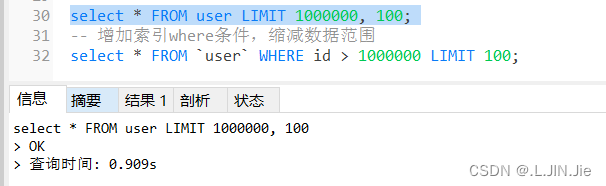
可以看出,添加了where条件,花费时间很少了,查询效率提升很多
此外,
当数据量大时,解决方案如下:
- 按需查询字段,减少网络IO消耗
- 避免使用select *,减少MySQL优化器负担
- 查询的字段尽量保证索引覆盖
- 借助nosql缓存数据环节MySQL数据库的压力
当偏移量大时,解决方案如下
- 偏移量大的场景我们也可以使用数据量大的优化方案,除此之外还可以将偏移量改为使用id限定的方式提升查询效率(比如添加where关键字限制id的范围、限制扫描条数)
(同时数据量大的方案也适用于偏移量大的解决方案)

















 603
603



 到【灌水乐园】发言
到【灌水乐园】发言








