 倾向得分匹配(PSM)算法论文解读
倾向得分匹配(PSM)算法论文解读





 本文是对论文《Some Practical Guidance for The Implementation of Propensity Score Matching》的解读。介绍了PSM的5个步骤及各步骤决策,探讨了估计倾向性得分、选择匹配算法等问题,还分析了选择偏差、无偏假设和正值假设,阐述了PSM具体实施步骤及评估方法。
本文是对论文《Some Practical Guidance for The Implementation of Propensity Score Matching》的解读。介绍了PSM的5个步骤及各步骤决策,探讨了估计倾向性得分、选择匹配算法等问题,还分析了选择偏差、无偏假设和正值假设,阐述了PSM具体实施步骤及评估方法。
文章目录
- 一、写在前面
- 二、论文总结、评价和应用。
- 三、论文讨论的主要问题
- 四、结论
- 五、文章脉络
-
- Abstract
- Section 1: Introduction
- Section 2: Evaluation Framework and Matching Basics
- Section 3: Implementation of Propensity Score Matching
-
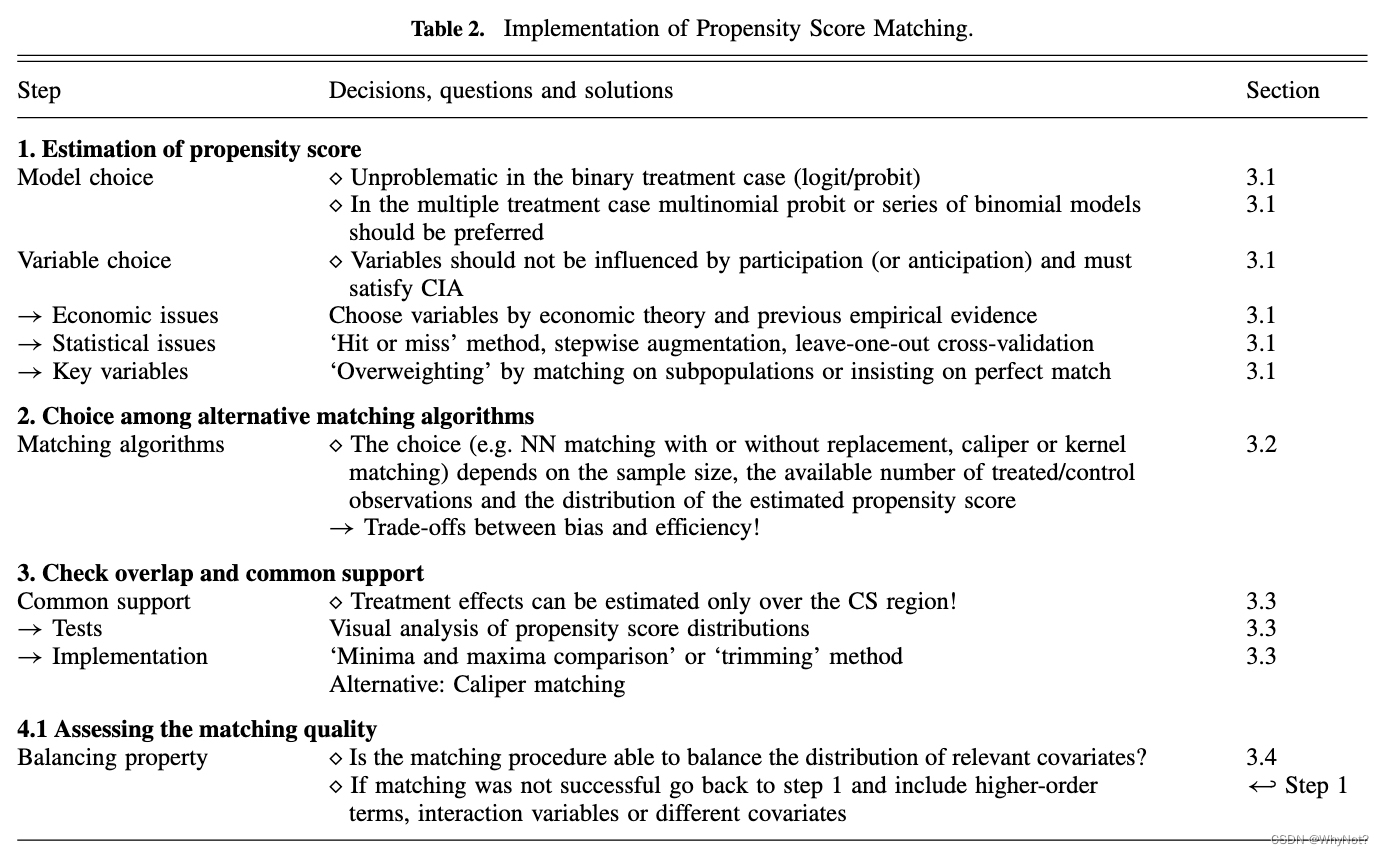
- 3.1 Estimating the Propensity Score
- 3.2 Choosing a Matching Algorithm
- 3.3 Overlap and Common Support(正值假设)
- 3.4 Assessing the Matching Quality (评估匹配质量)
- Choice-Based Sampling
- 3.6 When to Compare and Locking-in Effects?
- 3.7 Estimating the Variance of Treatment Effects?
- 3.8 Combined and Other Propensity Score Methods
- 3.9 Sensitivity Analysis
一、写在前面
本文来自对论文"Some Practical Guidance for The Implementation of Propensity Score Matching"的解读,需要读者了解因果推断的基本概念,如果需要快速了解相关概念,可以查阅我的因果推断专栏。
对于入门小白,重点推荐因果推断学习框架这篇文章,帮助你在开始学习前对这门学科有一个整体的把握。
论文的笔记方式采用了Ruth博士分享的方法,分为:
- 论文总结、评价和应用(需要自己思考和总结);
- 文章的主要问题(论文中可以找到,但要求自己归纳);
- 结论;
- 文章脉络(全文结构和关键点梳理)。
二、论文总结、评价和应用。
【总结】
PSM的5个步骤,以及每个步骤里涉及到的决策都有提及;总的来说非常全面。
【评价】
评估ATE估计的质量这一块儿涉及的内容不够深。
【应用】
工作:动调的处置效应挖掘。
三、论文讨论的主要问题
- 如何估计倾向性得分?
- 选择什么样的匹配算法?如何确定the region of common support(正值假设成立的区间)?
- 匹配的质量如何估计?处置效应和标准差怎么计算?
- 如果存在选择偏差怎么办?什么时候估计效应?
- 怎么做灵敏度分析?
四、结论

五、文章脉络
Abstract
提出了本文将要讨论的5个问题,上面👆第三部分已经提到了。
Section 1: Introduction
- 论述了目前匹配方法的广泛应用,综述了一些paper的研究方向。
- 介绍了选择偏差
因为我们想知道处置和不处置的差别,但是同一个个体不可能既被处置,又不被处置;
此时,如果我们以处置和不处置的群体的平均表现之差作为效应的估计,就可能出现选择偏差。
原因是两个群体可能不具备可比性。
【举个例子】:
高技能个体有更大的概率进入到一个培训项目,从而找到一份工作,获得更高的收入。(除了培训与否这个处置变量外,参加和不参加培训的人之间本身存在差异。)
提到选择偏差其实是想说,匹配方法有可能解决这一问题。
其核心思想是:在实验组和对照组中,找到各方面都比较相似的个体,从而使其具备可比性。隐含的假设是:条件独立假设,不了解的可以查看我的文章因果推断的三个基本假设快速学习,简单来说就是不存在未被观测到的混杂变量。文章后面的内容也都假定「条件独立假设」是成立的。
- 从“维度灾难”(curse of dimensionality)引入得分估计;
在出现高维特征的情况下,对所有的协变量进行匹配就会出现维度灾难。因此有人提出了「平衡得分」的方法,倾向性得分(给定一系列特征,被处置的概率)就是平衡得分的一种。
Propensity Score + Matching = PSM,PSM的流程是:

4. 给出了本文的结构:
- Section 2:基础背景知识介绍:
– 基本的评估框架;
– 一些我们感兴趣的处置效应
– PSM怎么解决评估问题,以及隐藏的重要假设。 - Section 3:PSM的具体实施步骤:
– 3.1 倾向性得分的估计(变量的选择、模型的选择);
– 3.2 比较不同匹配算法的优缺点;
– 3.3 如何检验实验组和对照组的overlap,以及如何实现 common support requirement?
– 3.4 怎么评估匹配的质量?
– 3.5 基于选择的抽样的问题。
– 3.6 when to measure programme effects。
– 3.7 评估处置效应的标准误差;
– 3.8 PSM怎么和其他的评估方法结合?
– 3.9 灵敏度分析。
– 3.10 programme heterogeneity, 动态选择问题, 合适的对照组的选择、实施匹配的可用软件回顾。 - Section 4:所有步骤的回顾和结论。
Section 2: Evaluation Framework and Matching Basics
Roy-Rubin Model
估计因果效应的标准框架是Roy-Rubin的潜在因果模型(我的文章因果推断学习框架有提到)。因为对于个体来说,只有一种结果可以被观测到(另一种未被观测到的结果称之为反事实结果),所以个体处置效应是不可能得到的,因此研究主要关注平均处置效应。
Parameter of Interest and Selection Bias
这部分内容给出了ATE和ATT的计算公式,想要快速区分因果推断中的各种效应(ITE、ATE、LATE、CATE…),可以查阅因果推断中的各种处置效应这篇文章。这里就不再赘述啦!
比较有意思的是这里给出了选择偏差的计算公式,我们快速推一下:
个体处置效应的计算公式:
τ i = Y i ( 1 ) − Y i ( 0 ) (0) \tau_i = Y_i(1) -Y_i(0) \tag{0} τi=Yi(1)−Yi(0)(0)
平均处置效应(针对总体而言)的计算公式是:
τ A T E = E ( τ ) = E [ Y ( 1 ) − Y ( 0 ) ] (1) \tau_{ATE} = E(\tau) = E[Y(1) -Y(0)] \tag{1} τATE=E(τ)=E[Y(1)−Y(0)](1)
但是我们经常很难观测到ATE,举个例子:某个项目是针对低收入群体的,这里我们并不关心该项目对百万富翁的影响,所以其实最重要的评价参数其实是干预组的处置效应,比如这个例子里的干预组就是低收入群体,它的数学表达是:
τ A T T = E ( τ ∣ D = 1 ) = E [ Y ( 1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9363
9363




 到【灌水乐园】发言
到【灌水乐园】发言







