




事情还得从ChatGPT说起。
2022年12月OpenAI发布了自然语言生成模型ChatGPT,一个可以基于用户输入文本自动生成回答的人工智能体。它有着赶超人类的自然对话程度以及逆天的学识。一时间引爆了整个人工智能界,各大巨头也纷纷跟进发布了自家的大模型,如:百度-文心一言、科大讯飞-星火大模型、Meta-LLama等
那么到底多大的模型算大模型呢?截至目前仍没有明确的标准,但从目前各家所发布的模型来看,模型参数至少要在B(十亿)级别才能算作入门级大模型,理论上还可以更大,没有上限。以上只是个人理解,目前还没有人对大模型进行详细的定义。
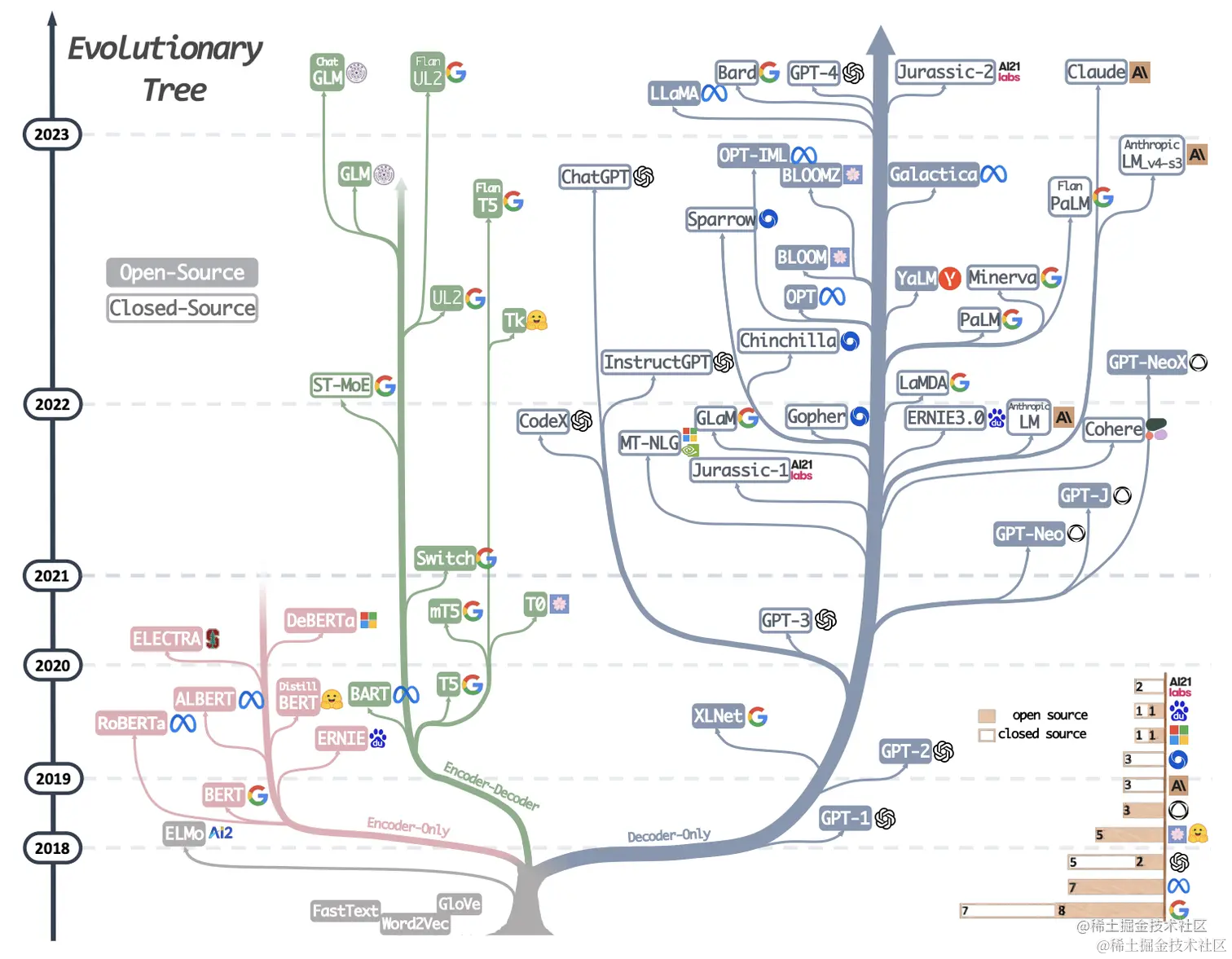
来一张图我们了解一下大模型的发展历程,从图中可以看到所谓大模型家族都有同一个根(elmo这一支除外)即Transformer,我们知道transformer由encoder-decoder两部分组成,encoder部分负责编码,更侧重于信息理解;而decoder部分负责解码,更侧重于文本生成;这样在模型选型方面就会有3种不同的选型,即:【only-encoder】这部分以大名鼎鼎的Bert为代表、【only-decoder】这部分的代表就是我们的当红炸子鸡GPT系列、【encoder-decoder】这部分相比于其他两个部分就显得略微暗淡一些,但同样也有一些相当不错的成果,其中尤以T5为代表。个人理解T5更像一个过渡产品,通过添加一些prefix或者prompt将几乎所有NLP任务都可以转换为Text-to-Text的任务,这样就使得原本仅适合encoder的任务(classification)也可以使用decoder的模式来处理。
图中时间节点可以看到是从2018年开始,2018年应该算是NLP领域的中兴之年,这一年诞生了大名鼎鼎的Bert(仅使用Transformer的Encoder部分),一举革了以RNN/LSTM/GRU等为代表的老牌编码器的命。Bert确立了一种新的范式,在Bert之前我们的模型是与任务强相关的,一个模型绑定一个任务,迁移性差。而Bert将NLP任务划分为预训练+微调的两阶段模式:预训练阶段使用大量的无标记数据训练一个Mask Language Model,而具体的下游任务只需要少量的数据在预训练的基础上微调即可。这样带来两个好处:(a)不需要针对专门的任务设计模型,只需要在预训练模型上稍作调整即可,迁移性好,真的方便。(b)效果是真的好,毕竟预训练学了那么多的知识。所以在接下来的几年内几乎所有的工作都是在围绕Bert来展看,又好用又有效果,谁能不爱呢?如下图就是Bert家族的明星们。
Transformer解决了哪些问题?
在没出现Transformer之前,NLP领域几乎都是以RNN模型为主导,RNN有两个比较明显的缺陷:(a)RNN模型是一个串行模型,只能一个时序一个时序的依次来处理信息,后一个时序需要依赖前一个时序的输出,这样就导致不能并行,时序越长性能越低同时也会造成一定的信息丢失。(b)RNN模型是一个单向模型,只能从左到右或者从右到左进行处理,无法实现真正的双向编码。

Transformer摒弃了RNN的顺序编码方式,完全使用注意力机制来对信息进行编码,如上图所示,Transformer的计算过程是完全并行的,可以同时计算所有时序的注意力得分。另外Transformer是真正的双向编码,如上图所示,在计算input#2的注意力得分时,input#2是可以同时看见input#1、input#3的且对于input#2而言input#1、input#3、甚至input#n都是同等距离的,没有所谓距离的概念,真正的天涯若比邻的感觉。
Tranformer的庐山真面目。
接下来我们从头更加深入的剖析一下Transformer结构,以及为什么大模型都要基于Transformer架构。以及在大模型时代我们都对Transformer做了哪些调整及修改。
同样来一张图,下面这张图就是我们Transformer的架构图,从图中可以看出,Transformer由左右两部分组成,左边这部分是Encoder,右边这部分就是Decoder了。Encoder负责对信息进行编码而Decoder则负责对信息解码 。下面我们从下往上对下图的每个部分进行解读。
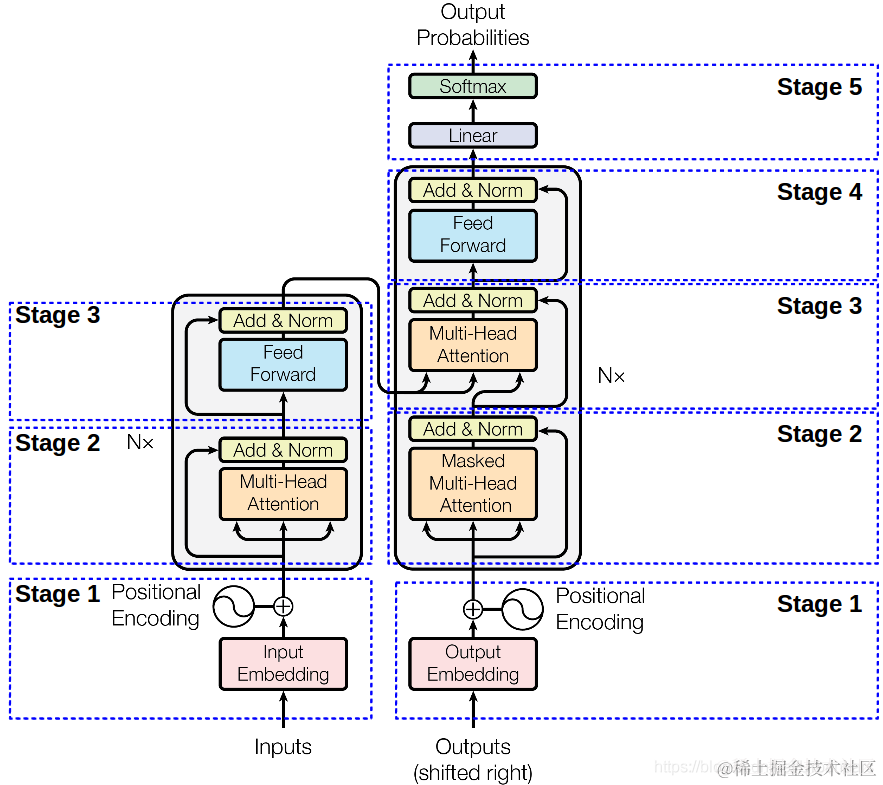
Stage-1部分就做两件事:对输入的文本进行编码、对文本位置进行编码。
Token Embedding
这部分主要是对文本进行编码,其核心部分为如何切分Token。典型的做法有Sentence Piece、Word Picece、BPE、甚至UniGram切词等。切词方式没有定数,个人理解切词的一个原则是:在能够覆盖到你的数据集的同时词汇表尽可能的小。故对切词方式不在赘述。下面啰嗦一下如何得到Token Embedding:

Positional Encoding
位置编码,前面我们有提到过在计算注意力的时候是没有所谓位置的概念的(见图-3),而对于任何一门语言,单词在句子中的位置以及排列顺序是非常重要的,它们不仅是一个句子的语法结构的组成
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2251
2251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









