




目录
使用文本内容定位的原因
在元素定位过程中有的元素只有标签没有属性,而只是具有文本信息,这时在定位的时候需要通过文本内容来定位。
定位的方式:通过xpath定位方法定位,文本内容的选择形式有两种方法,精确匹配和模糊匹配
如访问:控制台 · 天气API
定位如图元素是否存在
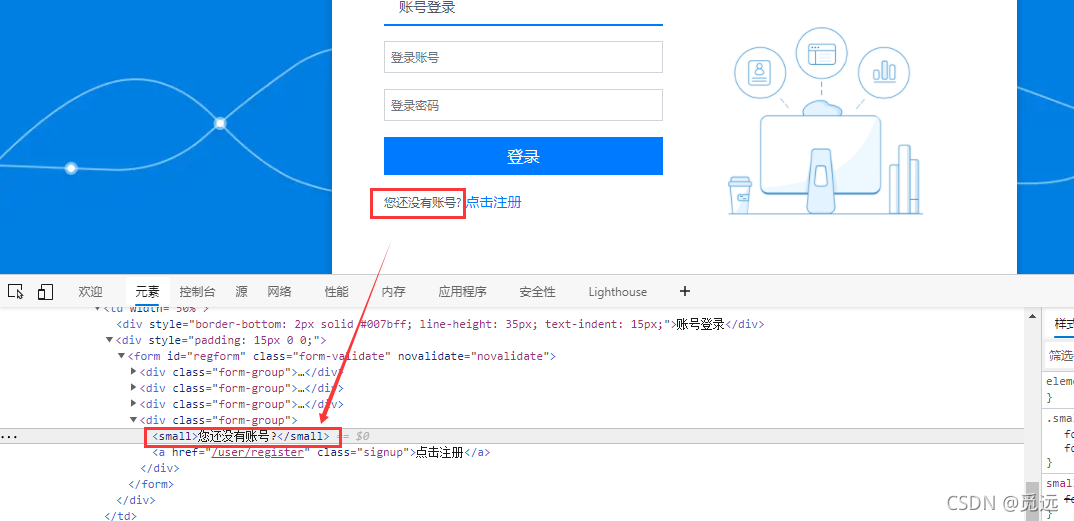
精确匹配:text()方法
from selenium import webdriver import
 本文介绍了在web自动化测试中,如何利用Python的Selenium库通过元素的文本内容进行定位。当元素仅有文本信息而无特定属性时,可以使用text()方法进行精确匹配,或用contains()进行模糊匹配。示例中展示了这两种方法在定位含有‘登陆’文本的元素时的应用。
本文介绍了在web自动化测试中,如何利用Python的Selenium库通过元素的文本内容进行定位。当元素仅有文本信息而无特定属性时,可以使用text()方法进行精确匹配,或用contains()进行模糊匹配。示例中展示了这两种方法在定位含有‘登陆’文本的元素时的应用。
目录
在元素定位过程中有的元素只有标签没有属性,而只是具有文本信息,这时在定位的时候需要通过文本内容来定位。
定位的方式:通过xpath定位方法定位,文本内容的选择形式有两种方法,精确匹配和模糊匹配
如访问:控制台 · 天气API
定位如图元素是否存在
from selenium import webdriver import
 7714
2432
7416
7714
2432
7416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言






 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























