



sync.Pool 深度解析
本期分享
sync.Pool:短生命周期对象的复用技巧,以及它在 Go Runtime 与 GC 背后发生的那些事。
一、为什么需要 sync.Pool
要理解 为什么会有 sync.Pool,我们需要先理解 Heap Allocation(堆分配)。
1. 什么情况下会发生堆分配?
当某个值的生命周期比创建它的函数更长时,这个值就必须分配到堆(heap)上。
在任何一个 Go 程序中,堆对象都是不可避免的,而它们会带来两类成本:
(1)Allocation:内存分配
为对象在堆上预留内存空间。
虽然 Go 的分配器已经非常快了,但相比栈分配,仍然要慢不少。

(2)Deallocation:内存回收
当对象不再被使用或不可达时,其占用的内存需要被回收。

2. Go 是如何回收堆内存的?
在 Go 中,我们不需要像 C 一样手动 free,而是由 垃圾回收器(GC) 来完成:
- 标记仍然存活的对象
- 未被标记的对象会被视为垃圾
- 清扫(sweep)并回收这些内存

3. GC 的代价
GC 并不是免费的,它会带来额外开销:
- 占用 CPU 时间进行遍历与标记
- Sweep 阶段清理内存
- 启用写屏障(Write Barrier),导致写操作变慢
- 在 GC 阶段切换时,会发生短暂的 Stop The World
 **
**
减少堆对象的产生 = 降低 GC 压力
而 sync.Pool,正是为此而生。
二、sync.Pool 是什么
sync.Pool 本质上是 由 Go Runtime 管理的对象缓存池。

你可以把暂时不用的对象交给它,在需要时再取回来,而不是重新分配。
- 并发安全
- 面向短生命周期对象
- 自动与 GC 周期协作
- 高效(并发场景下几乎无额外成本)
- 基于 P(Processor)本地缓存,绝大多数
Get / Put操作发生在当前 P 上 - 无全局锁竞争,避免高并发场景下的 Mutex 瓶颈
- 快路径仅涉及指针读写与调度器的
pin / unpin,CPU 指令开销极低 - 相比频繁的
new / make,可显著减少堆分配次数与 GC 压力
- 基于 P(Processor)本地缓存,绝大多数
sync.Pool用极小的并发管理成本,换来了对堆分配和 GC 压力的显著削减。
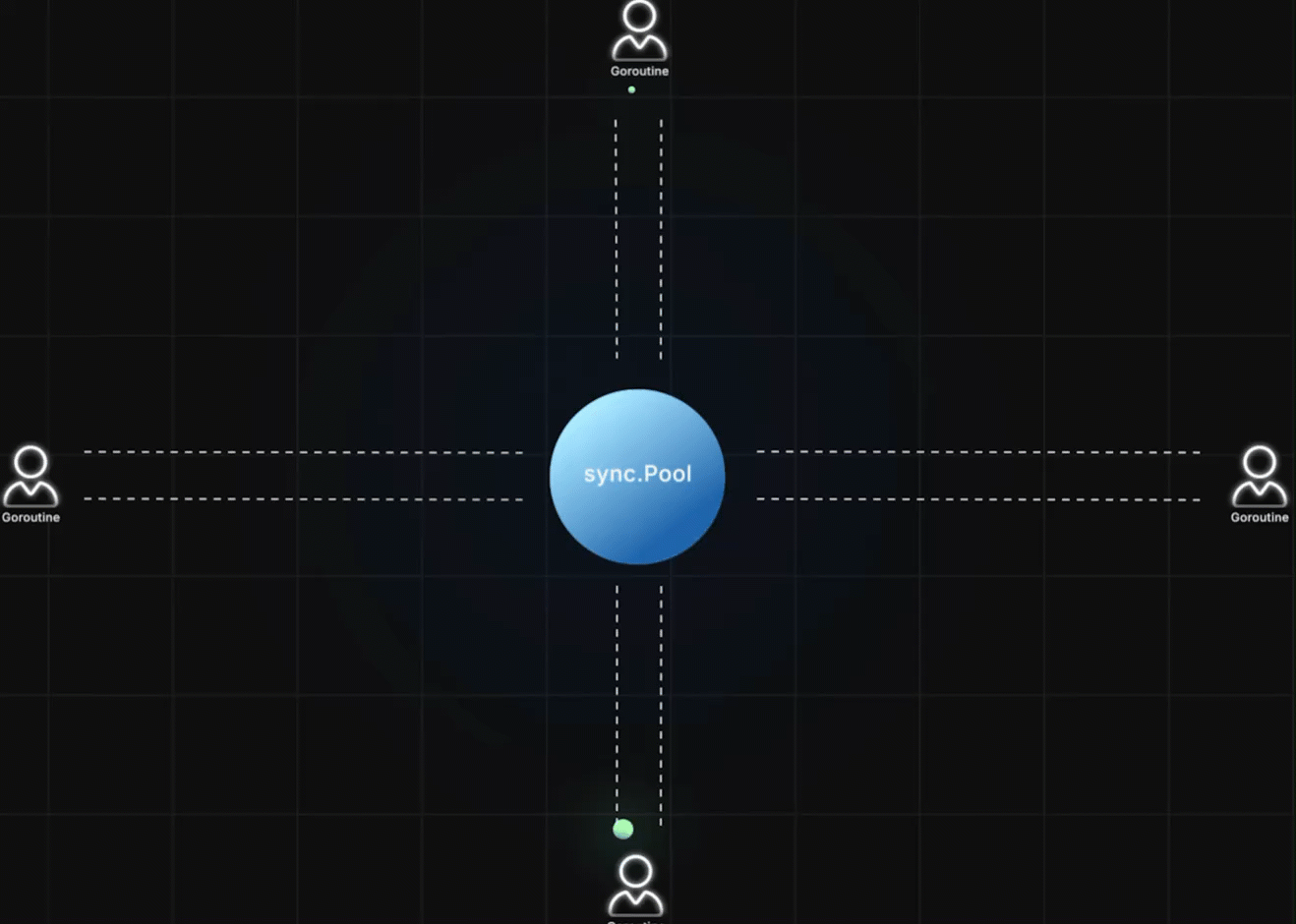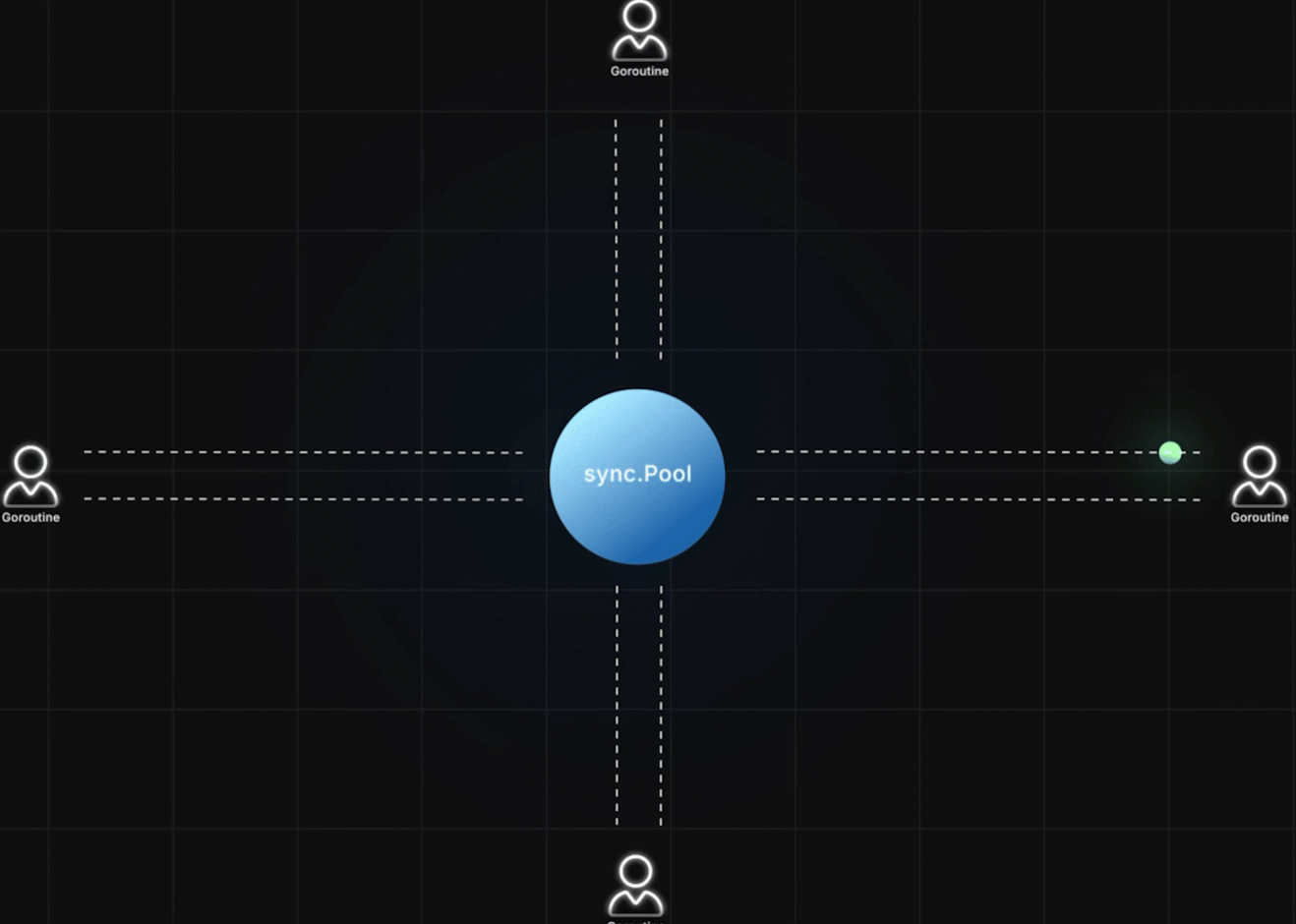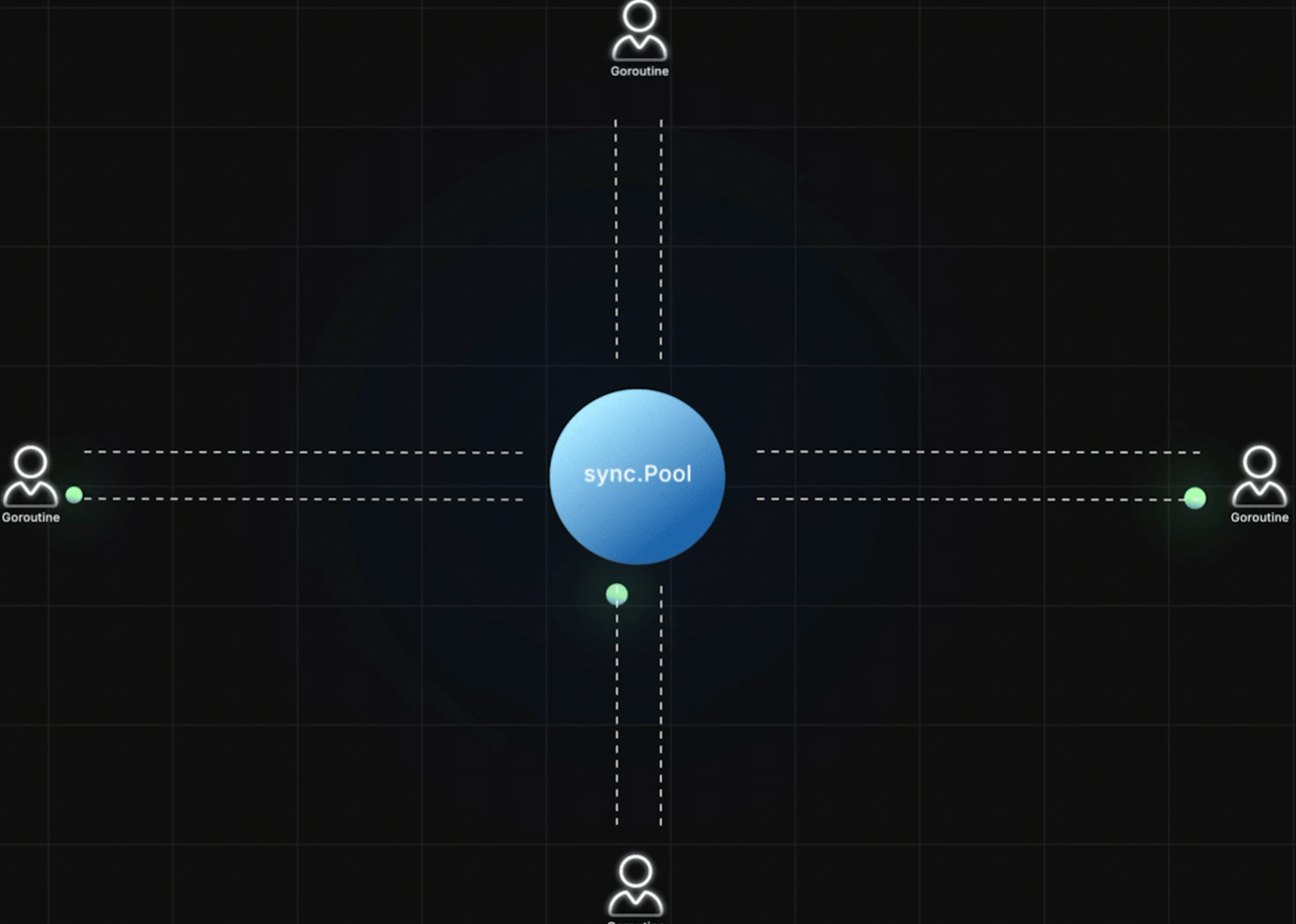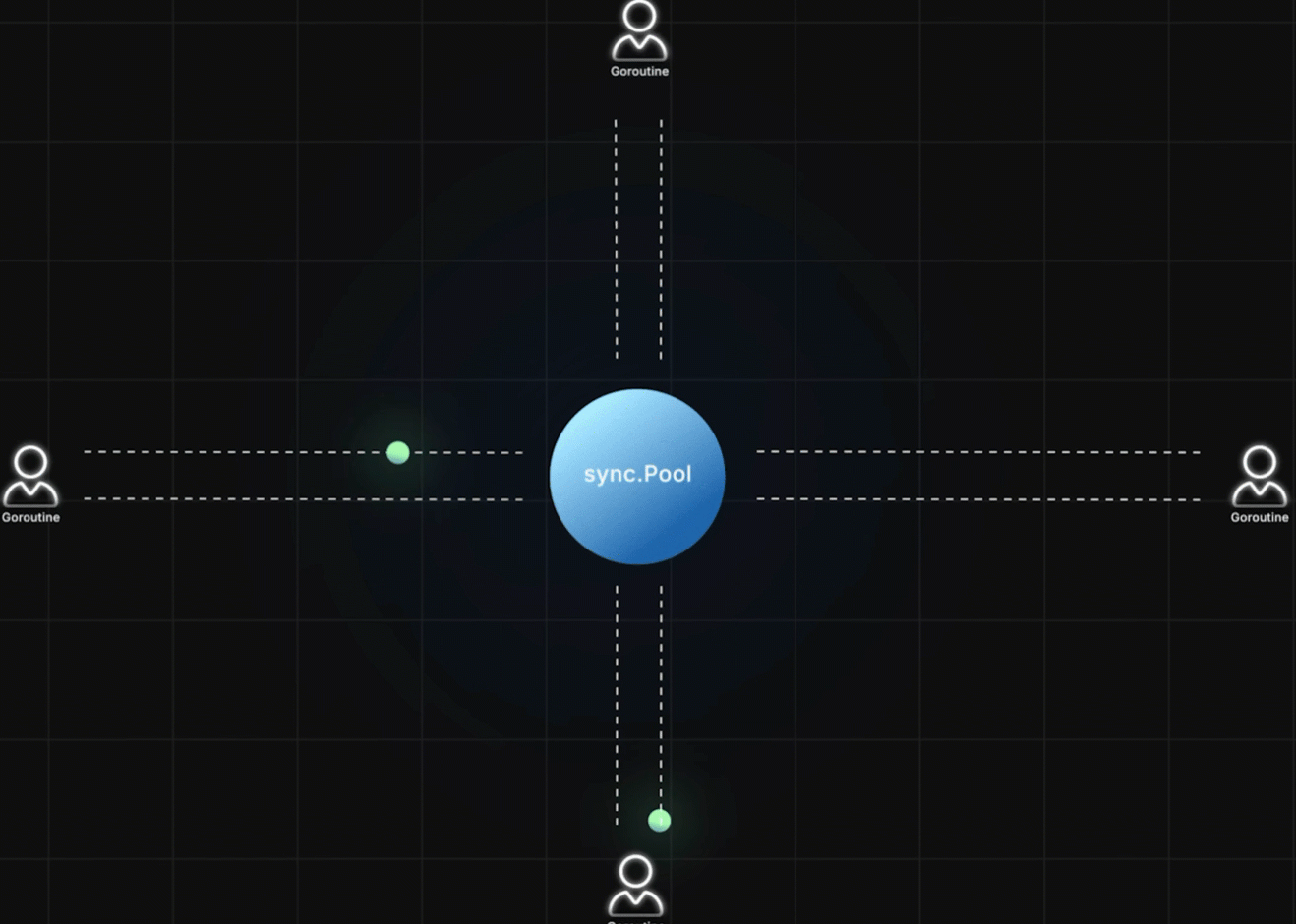
多个 goroutine 可以同时:
- 从 pool 中取对象
- 使用并修改对象状态
- 再放回 pool 复用
你不需要关心:
- pool 里当前有多少对象
- 对象什么时候被丢弃(pool 会管理自己持有对象的生命周期)
三、sync.Pool 的基本用法
1. 定义一个 Pool
import "sync"
var pool = sync.Pool{}
2. 配置 New 函数(推荐)
当 pool 为空时,自动创建新对象:
var pool = sync.Pool{
New: func() any {
return new(bytes.Buffer)
},
}
3. Get / Put 使用示例
buf := pool.Get().(*bytes.Buffer)
buf.Reset()
// 使用 buf
pool.Put(buf)
⚠️ 注意:
Get返回的是any,需要类型断言- 一定要在复用前重置对象状态
4. Get 的内部行为规则
- pool 中有对象 → 直接返回
- pool 为空:
- 有
New→ 调用New - 无
New→ 返回nil
- 有
如果对象初始化需要参数,New 无法满足,就需要手动封装一层。
四、标准库中的真实案例
HTTP 包中有一个经典用法:
//go:linkname newBufioReader
func newBufioReader(r io.Reader) *bufio.Reader {
if v := bufioReaderPool.Get(); v != nil {
br := v.(*bufio.Reader)
br.Reset(r)
return br
}
return bufio.NewReader(r)
}
特点:
- pool 不提供 New
- 自定义构造函数接收参数
- Get 返回 nil 时,直接创建新对象
这是标准库中一个非常经典的使用sync.Pool 的案例。
五、什么时候该用 sync.Pool
1. 适合的场景
sync.Pool 只适合短生命周期对象,满足以下三点:
- 频繁创建
- 很快被丢弃
- 高并发复用
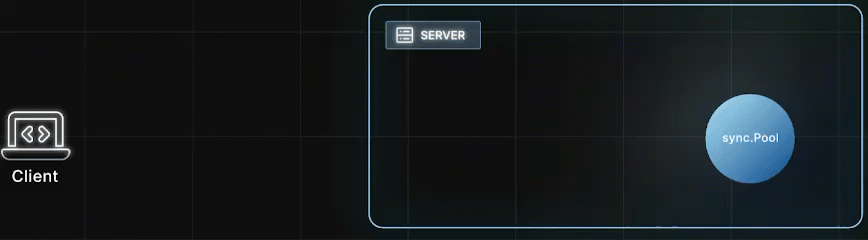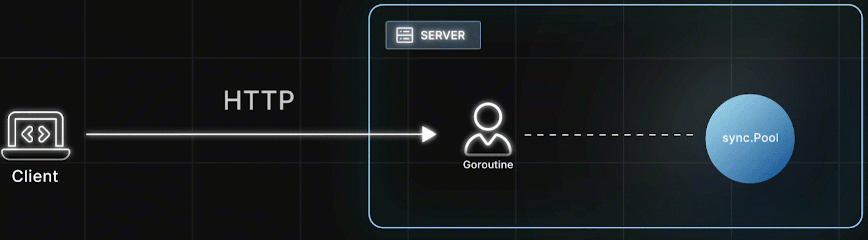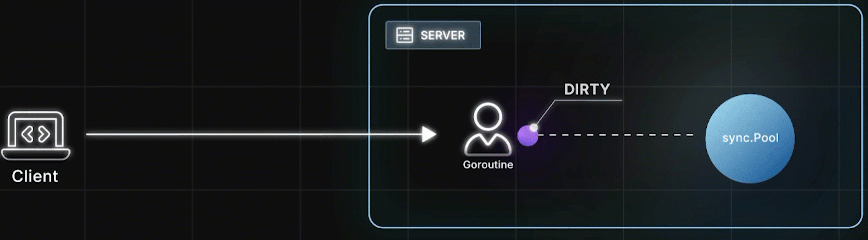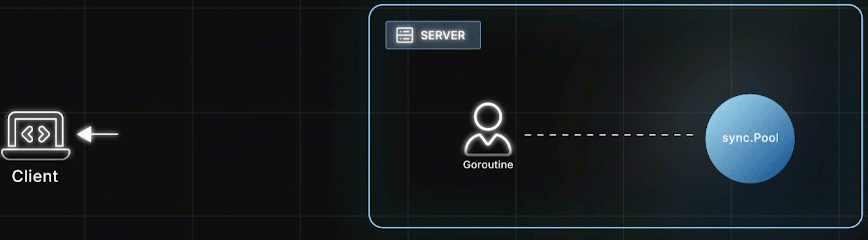
典型场景:HTTP请求
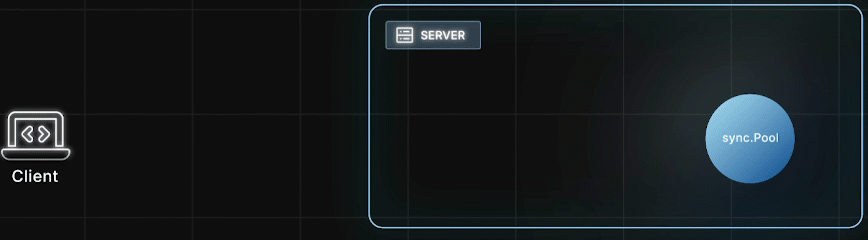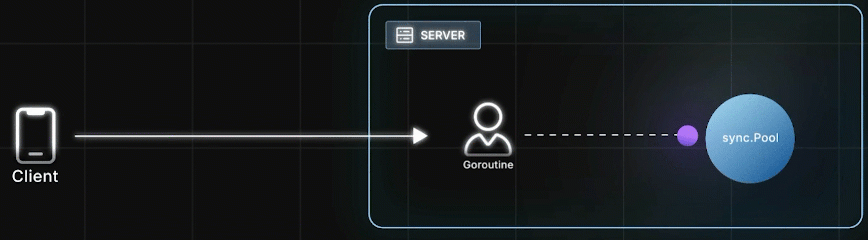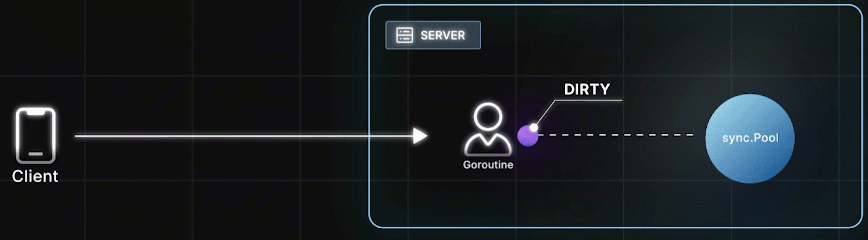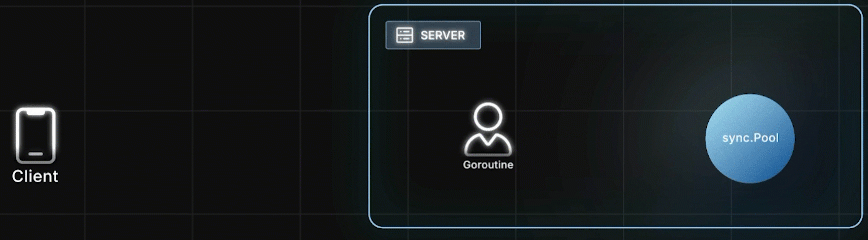
处理HTTP请求时,Goroutine 从 Pool 里取出一个对象,使用它并修改状态,完成后把这个"脏对象" Put 回 Pool,然后给客户端响应
之后又来了一个请求,另一个Goroutine 再把这个"脏对象"取出来,重置其状态,继续使用。
2. 不适合的场景
- 生命周期很长
- 使用频率很低
- 占用内存巨大且不可控
如果对象在 pool 中长时间得不到复用,最终一定会被 GC 清理。
六、sync.Pool 与 GC 的关系(重点)
官方文档说:
Pool 中的对象可能在任何时候被自动移除
这听起来很模糊,但实际上它和 GC 周期强相关。
1. Pool 内部结构
// [the Go memory model]: https://go.dev/ref/mem
type Pool struct {
noCopy noCopy
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
localSize uintptr // size of the local array
victim unsafe.Pointer // local from previous cycle
victimSize uintptr // size of victims array
// New optionally specifies a function to generate
// a value when Get would otherwise return nil.
// It may not be changed concurrently with calls to Get.
New func() any
}
- local:当前 GC 周期使用
- victim:上一个 GC 周期遗留
2. 生命周期流程
第 1 个 GC 周期
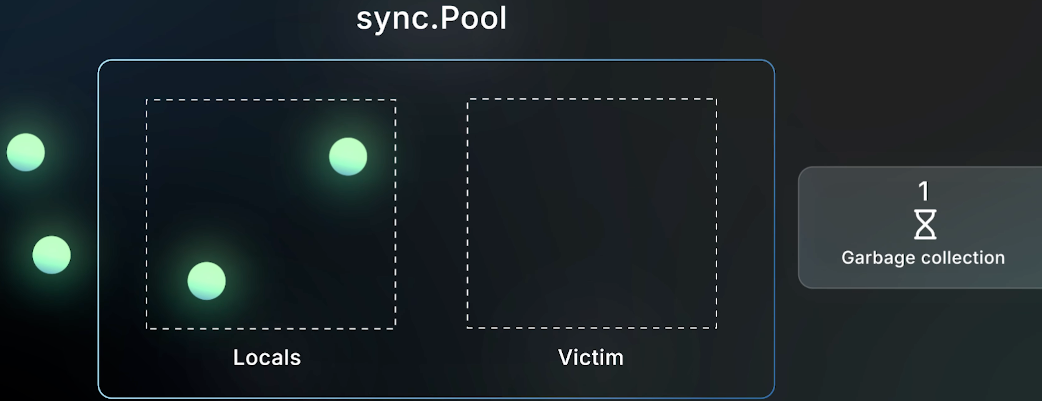
Put 或 New 对象进入
localpool, Goroutine 可能会取走一部分,也会有一部分留在localpool 里
第 2 个 GC 周期

local中剩下的对象全部转移到victim
Put或New的对象继续进入localpool
第 3 个 GC 周期

victim被清空
local里上一个周期遗留的对象又全部进入victim中
对象被 GC 回收
结论: 放入
sync.Pool的对象,最多只能“存活”两个 GC 周期(除非再次被复用)。
七、为什么 bytes.Buffer 非常适合 sync.Pool
bytes.Buffer 本质上是对 []byte 的封装:
type Buffer struct {
buf []byte
off int
lastRead readOp
}
1. slice 扩容的 GC 成本
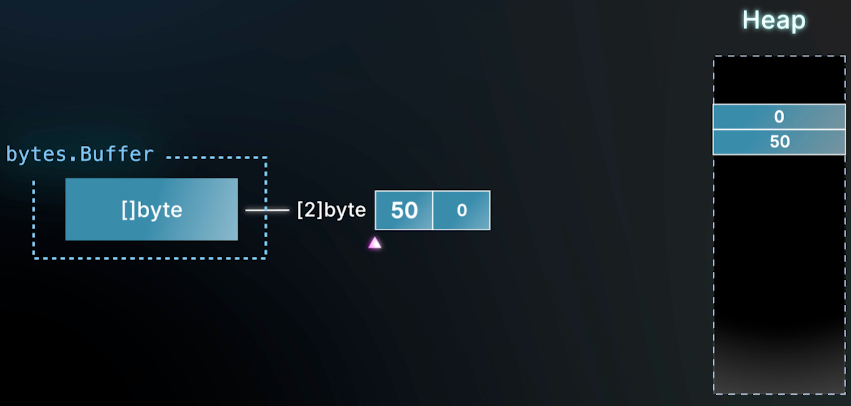
从pool里取到一个bytes.Buffer,它的底层数组当前容量是2,你可以append 不超过其容量的数据
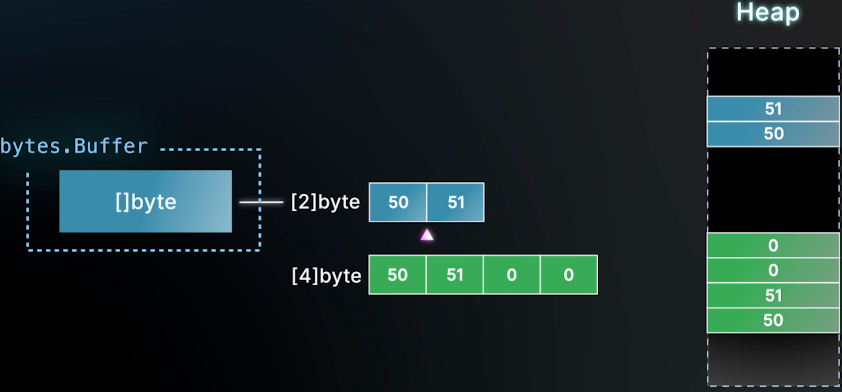
一旦append 超过其原本数组容量,go 在 heap 上会分配一个更大的数组,并把内容复制过去
- buffer 不断 append
- 超过容量 → 分配更大的底层数组
- 旧数组变成垃圾
如果每个请求都 new 一个 buffer:
- 会制造大量短命垃圾
- GC 压力显著上升
2. Pool + Reset 的优势
- Reset 只清空长度
- 保留底层容量
- 避免重复扩容与拷贝
八、为什么 Pool 里几乎总是放指针
这是一个关键设计点,有助于避免额外分配。要理解这一点,需要先了解 interface 的工作原理,因为当你调用 Put 函数把对象放进pool 时,它会被封装成 interface。
1. empty interface 的内部结构
type eface struct {
_type *_type
data unsafe.Pointer
}
- _type: 指向类型的指针
- data: 指向实际值的指针
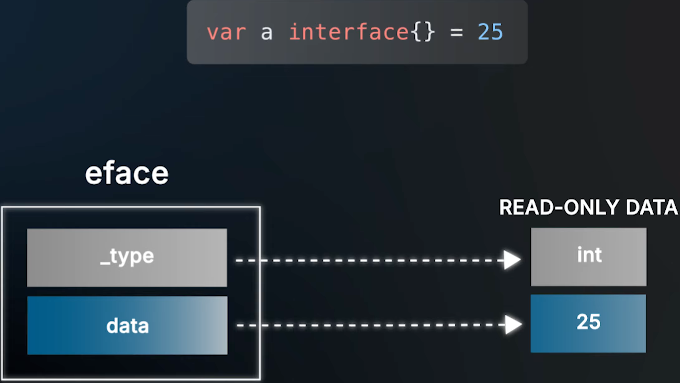
关键是这里的data字段本身就是一个指针,当你把一个byte、int或者一个struct赋值给interface时,Go会复制这个值,然后让data指针指向那份拷贝
2.案例
放值(int )
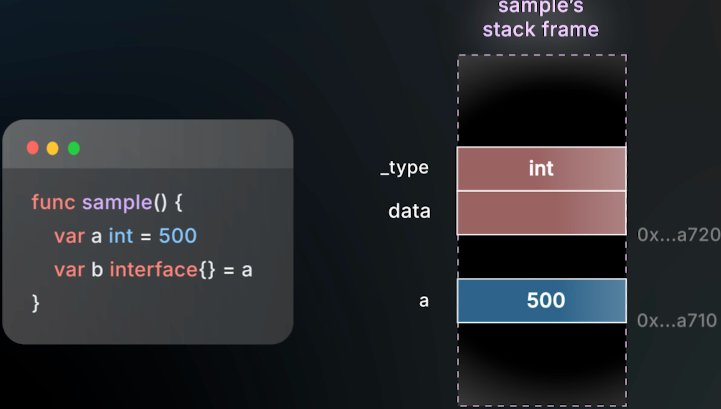
把整数
a赋值给 interfaceb,整数a和interfaceb的值都会存放在栈上
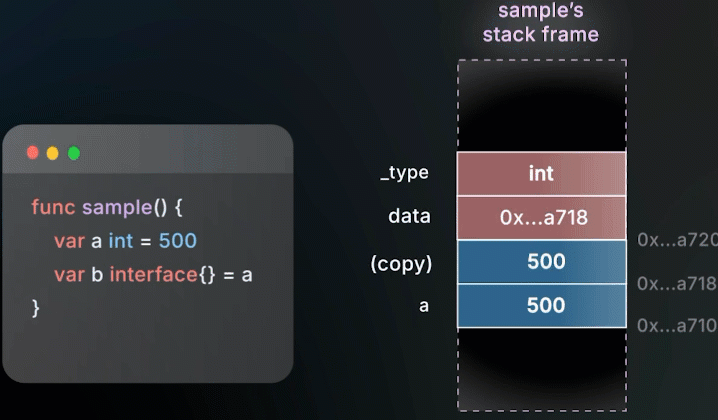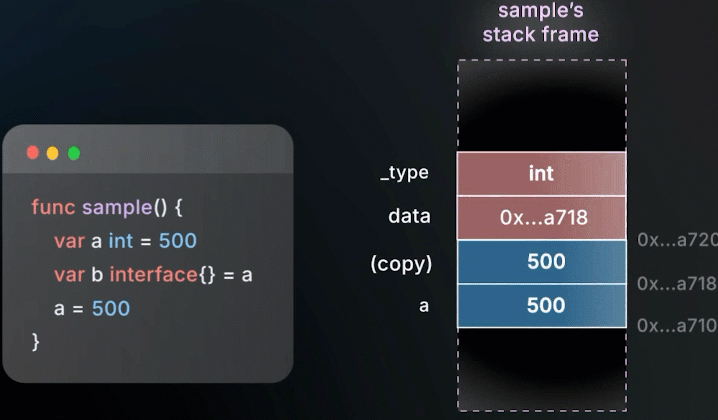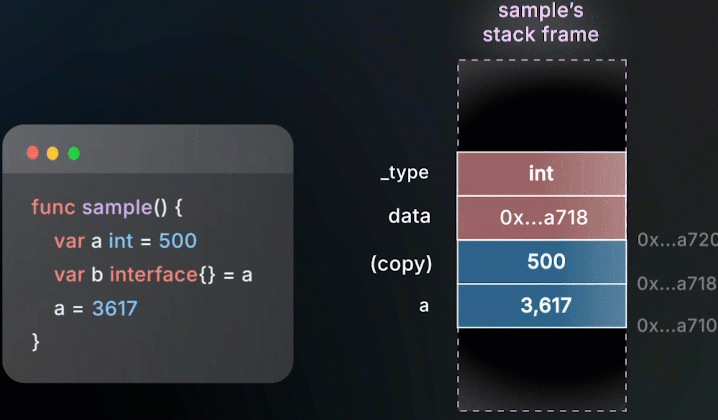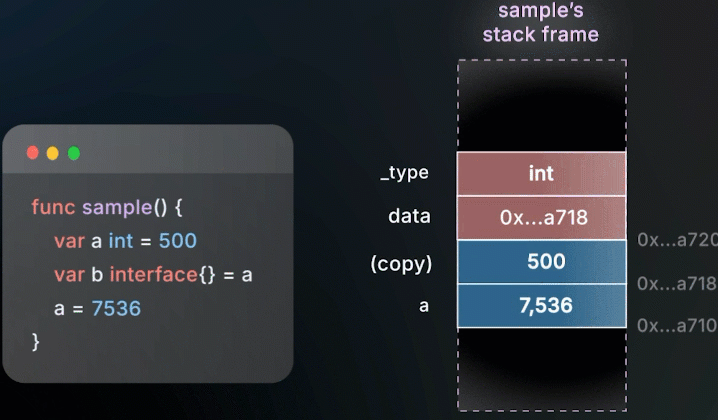
把整数
a赋值给 interfaceb→ 会创建一份a的拷贝 → 可能分配在栈上
改变a的值,不会影响 interface 内存储的值
放指针
Interface 有个优化,当我们使用指针时,情况会完全不同

把指针
x赋值给 interfaceb→ interface 的 data 直接指向原对象 → 不会产生拷贝
在sync.Pool中使用指针可以避免每次使用都做 heap allocation
Example:

如果从整数 pool 里取出一个,把它设置为500,然后用Put函数把它放回pool
由于Put 接受的是一个interface,把int 值传进去会导致创建一份 int 的拷贝,变量a和interface 可能分配在栈上(具体是由逃逸分析决定的),但是拷贝的内容就会被分配到堆上。
3. escape analysis 的视角
当你调用 Put(x any):
- 编译器无法证明 x 仍然只在当前 goroutine 使用
- 为了安全,必须让数据位于 heap
可以通过:
go build -gcflags="-m"
看到类似:
a escapes to heap
把上面那个例子改为使用指针

从pool 获取到一个指针时,该指针指向的对象已经分配在heap上
当用完后调用Put 还回时,因为已经是一个指针,最终interface data 会直接指向同一个对象,不需要额外的 heap allocation(期望的目的便是如此)
九、总结
sync.Pool是为 短生命周期、高频使用对象 设计的- 它通过对象复用来显著降低 GC 压力
- Pool 中的对象会随 GC 周期自动清理
- 永远优先放指针,而不是值
- 非常适合:
bytes.Buffer、临时 struct、slice 容器
如果在高并发服务中频繁创建临时对象,sync.Pool 往往是一个低成本、高收益的优化手段。
如果你觉得这篇文章有帮助,欢迎点赞 +关注



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











