







 本文深入解析阻塞队列的概念,包括ArrayBlockingQueue与LinkedBlockingQueue的特性、数据结构及核心操作方法。对比两者在队列大小、数据存储、GC回收和锁实现等方面的差异。
本文深入解析阻塞队列的概念,包括ArrayBlockingQueue与LinkedBlockingQueue的特性、数据结构及核心操作方法。对比两者在队列大小、数据存储、GC回收和锁实现等方面的差异。
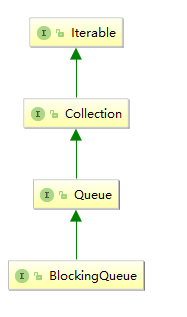
【1】阻塞队列
① 基础定义
阻塞队列与我们平常接触的普通队列(LinkedList或ArrayList等)的最大不同点,在于阻塞添加和阻塞删除方法。
阻塞添加
所谓的阻塞添加是指当阻塞队列元素已满时,队列会阻塞加入元素的线程,直到队列元素不满时才重新唤醒线程执行元素加入操作。
阻塞删除
阻塞删除是指在队列元素为空时,删除队列元素的线程将被阻塞,直到队列不为空再执行删除操作(一般都会返回被删除的元素)
BlockingQueue不接受null元素,当试图add、put或者offer一个null元素时将抛出NullPointerException异常。null是一个特殊值,作为poll方法失败的返回值。
BlockingQueue可能是有容量限制的,在任何给定的时间它可能持有一个remainingCapacity。如果超过remainingCapacity,那么任何元素都不能put(而不阻塞)。没有任何内在容量约束的 BlockingQueue总是报告剩余容量为 Integer.MAX_VALUE。
BlockingQueue实现主要用于生产者-消费者队列,但还支持 java.util.Collection接口。因此,例如,可以使用 remove(x)从队列中删除任意元素。但是,这些操作通常执行效率不高,并且仅用于偶尔使用,例如当队列消息被取消时。
BlockingQueue的实现是线程安全的。所有排队方法都使用内部锁或其他形式的并发控制以原子方式实现其效果。但是,除非在实现中另有规定,否则Collection的批量操作如 addAll、containsAll、retainAll和 removeAll不必以原子方式执行。因此,例如,在addAll©中只添加了一些元素之后,addAll©可能会失败(引发异常)。
BlockingQueue本质上不支持任何类型的 close 或 shutdown 操作,以指示不再添加任何元素。这些功能的需求和使用往往取决于实现。例如,一种常见的策略是生产者插入特殊的 end-of-stream 或 poison 对象,当消费者使用这些对象时,会对其进行相应的处理。
内存一致性影响:与其他并发集合一样,将对象放入 BlockingQueue的动作 Happens-Before于随后而来的另一个线程的访问或删除动作。
② 基本方法与分类
由于Java中的阻塞队列接口BlockingQueue继承自Queue接口,因此先来看看阻塞队列接口为我们提供的主要方法。
public interface BlockingQueue<E> extends Queue<E> {
//将指定的元素插入到此队列的尾部(如果立即可行且不会超过该队列的容量)
//在成功时返回 true,如果此队列已满,则抛IllegalStateException。
boolean add(E e);
//将指定的元素插入到此队列的尾部(如果立即可行且不会超过该队列的容量)
// 将指定的元素插入此队列的尾部,如果该队列已满,
//则在到达指定的等待时间之前等待可用的空间,该方法可中断
boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException;
//将指定的元素插入此队列的尾部,如果该队列已满,则一直等到(阻塞)。
void put(E e) throws InterruptedException;
//获取并移除此队列的头部,如果没有元素则等待(阻塞),
//直到有元素将唤醒等待线程执行该操作
E take() throws InterruptedException;
//获取并移除此队列的头部,在指定的等待时间前一直等到获取元素,
//超过时间方法将结束
E poll(long timeout, TimeUnit unit) throws InterruptedException;
//从此队列中移除指定元素的单个实例(如果存在)。
boolean remove(Object o);
}
//除了上述方法还有继承自Queue接口的方法
//获取但不移除此队列的头元素,没有则抛异常NoSuchElementException
E element();
//获取但不移除此队列的头;如果此队列为空,则返回 null。
E peek();
//获取并移除此队列的头,如果此队列为空,则返回 null。
E poll();
这里我们把上述操作进行分类:
- 插入方法:
- add(E e) : 将元素插入此队列的尾部添加成功返回true,如果空间不足抛出IllegalStateException异常
- offer(E e) : 将元素插入此队列的尾部成功返回 true,如果此队列已满,则返回 false。
- put(E e) :将元素插入此队列的尾部,如果该队列已满,则一直阻塞
- 删除方法:
- remove(Object o) :移除指定元素,成功返回true,失败返回false
- remove() : 获取并移除此队列的头元素,如果队列为空则抛出异常
- poll() : 获取并移除此队列的头元素,若队列为空,则返回 null
- take():获取并移除此队列头元素,若没有元素则一直阻塞。
- 检查方法
- element() :获取但不移除此队列的头元素,没有元素则抛异常
- peek() : 获取但不移除此队列的头;若队列为空,则返回 null。
| Throws exception | Special value | Blocks | Times out | |
|---|---|---|---|---|
| Insert | add(e)} | offer(e) | put(e) | offer(e, time, unit) |
| Remove | remove() | poll() | take() | poll(time, unit) |
| Examine | element() | peek() | not applicable | not applicable |
③ 经典实例生产者消费者
如下是一个经典的生产者-消费者使用场景,BlockingQueue可以被多个生产者和消费者线程安全地使用。
class Producer implements Runnable {
private final BlockingQueue queue;
Producer(BlockingQueue q) { queue = q; }
public void run() {
try {
while (true) { queue.put(produce()); }
} catch (InterruptedException ex) { ... handle ...}
}
Object produce() { ... }
}
class Consumer implements Runnable {
private final BlockingQueue queue;
Consumer(BlockingQueue q) { queue = q; }
public void run() {
try {
while (true) { consume(queue.take()); }
} catch (InterruptedException ex) { ... handle ...}
}
void consume(Object x) { ... }
}
class Setup {
void main() {
BlockingQueue q = new SomeQueueImplementation();
Producer p = new Producer(q);
Consumer c1 = new Consumer(q);
Consumer c2 = new Consumer(q);
new Thread(p).start();
new Thread(c1).start();
new Thread(c2).start();
}
}
接下来我们学习常见的ArrayBlockingQueue和LinkedBlockingQueue。
【2】ArrayBlockingQueue
① 概念介绍
ArrayBlockingQueue 是一个用数组实现的有界阻塞队列,其内部按先进先出的原则对元素进行排序,其中 put 方法和 take 方法为添加和删除的阻塞方法。
这是一个经典的有界缓冲区,其中固定大小的数组保存生产者插入和消费者提取的元素。一旦创建,容量将无法更改。尝试将元素 put放入 full 队列将导致操作阻塞,尝试从空队列中 take 一个元素也会类似地阻塞。
ArrayBlockingQueue内部的阻塞队列是通过重入锁ReenterLock和Condition条件队列实现的,所以ArrayBlockingQueue中的元素存在公平访问与非公平访问的区别。
- 对于公平访问队列,被阻塞的线程可以按照阻塞的先后顺序访问队列,即先阻塞的线程先访问队列。公平性通常会降低吞吐量,但会降低可变性并避免饥饿。
- 而非公平队列,当队列可用时,阻塞的线程将进入争夺访问资源的竞争中,也就是说谁先抢到谁就执行,没有固定的先后顺序。
创建公平与非公平阻塞队列代码如下:
//默认非公平阻塞队列
ArrayBlockingQueue queue = new ArrayBlockingQueue(2);
//公平阻塞队列
ArrayBlockingQueue queue1 = new ArrayBlockingQueue(2,true);
//构造方法源码
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
② 核心成员变量
ArrayBlockingQueue的内部是通过一个可重入锁ReentrantLock和两个Condition条件对象来实现阻塞,这里先看看其内部成员变量:
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
/** 存储数据的数组 */
final Object[] items;
/**获取数据的索引,主要用于take,poll,peek,remove方法 */
int takeIndex;
/**添加数据的索引,主要用于 put, offer, or add 方法*/
int putIndex;
/** 队列元素的个数 */
int count;
/** 控制并发访问的锁 */
final ReentrantLock lock;
/**notEmpty条件对象,用于通知take方法队列已有元素,可执行获取操作 */
private final Condition notEmpty;
/**notFull条件对象,用于通知put方法队列未满,可执行添加操作 */
private final Condition notFull;
//迭代器
transient Itrs itrs = null;
//...
}
从成员变量可看出,ArrayBlockingQueue内部确实是通过数组对象items来存储所有的数据,值得注意的是ArrayBlockingQueue通过一个ReentrantLock来同时控制添加线程与移除线程的并发访问,这点与LinkedBlockingQueue区别很大(稍后会分析)。
而对于notEmpty条件对象则是用于存放等待或唤醒调用take方法的线程,告诉他们队列已有元素,可以执行获取操作。
同理notFull条件对象是用于等待或唤醒调用put方法的线程,告诉它们队列未满,可以执行添加元素的操作。
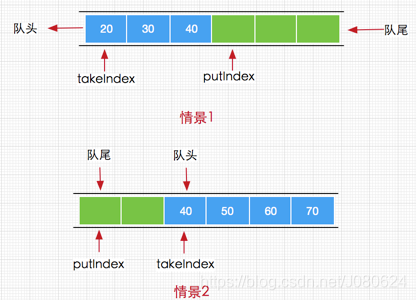
takeIndex代表的是下一个方法(take,poll,peek,remove)被调用时获取数组元素的索引。
putIndex则代表下一个方法(put, offer, or add)被调用时元素添加到数组中的索引。
图示如下 :

其他方法如下:
// 原子性地移除此队列中的所有元素。
// 移除前解锁,移除后解锁
void clear()
//如果此队列包含指定的元素,则返回 true。
boolean contains(Object o)
//移除此队列中所有可用的元素,并将它们添加到给定collection中。
int drainTo(Collection<? super E> c)
//从此队列中移除给定数量maxElements的可用元素,并将这些元素添加到给定collection 中。
int drainTo(Collection<? super E> c, int maxElements)
//返回在此队列中的元素上按适当顺序进行迭代的迭代器。
Iterator<E> iterator()
//返回队列还能添加元素的数量
int remainingCapacity()
//返回此队列中元素的数量。
int size()
//返回一个按适当顺序包含此队列中所有元素的数组。
Object[] toArray()
//返回一个按适当顺序包含此队列中所有元素的数组;返回数组的运行时类型是指定数组的运行时类型。
<T> T[] toArray(T[] a)
③ 核心操作添加元素
主要有add、offer和put。
① add & offer
// java.util.AbstractQueue#add
//add方法实现,间接调用了offer(e)
public boolean add(E e) {
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
}
//offer方法 返回true或者false
public boolean offer(E e) {
checkNotNull(e);//检查元素是否为null
final ReentrantLock lock = this.lock;
lock.lock();//加锁
try {
if (count == items.length)//判断队列是否满
return false;
else {
enqueue(e);//添加元素到队列
return true;
}
} finally {
lock.unlock();
}
}
//入队操作
private void enqueue(E x) {
//获取当前数组
final Object[] items = this.items;
//通过putIndex索引对数组进行赋值
items[putIndex] = x;
//索引自增,如果已是最后一个位置,重新设置 putIndex = 0;
if (++putIndex == items.length)
putIndex = 0;
count++;//队列中元素数量加1
//唤醒调用take()方法的线程,执行元素获取操作。
notEmpty.signal();
}
这里的add方法和offer方法实现比较简单,其中需要注意的是enqueue(E x)方法,其方法内部通过putIndex索引直接将元素添加到数组items中。
这里可能会疑惑的是当putIndex索引大小等于数组长度时,需要将putIndex重新设置为0。这是因为当前队列执行元素获取时总是从队列头部获取,而添加元素从队列尾部添加。所以当队列索引(从0开始)与数组长度相等时,下次我们就需要从数组头部开始添加了。
② put
我们继续看看put是如何阻塞等待进行放入的。
//put方法,阻塞时可中断
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();//该方法可中断
try {
//当队列元素个数与数组长度相等时,无法添加元素
while (count == items.length)
//将当前调用线程挂起,添加到notFull条件队列中等待唤醒
notFull.await();
enqueue(e);//如果队列没有满直接添加。。
} finally {
lock.unlock();//释放锁
}
}
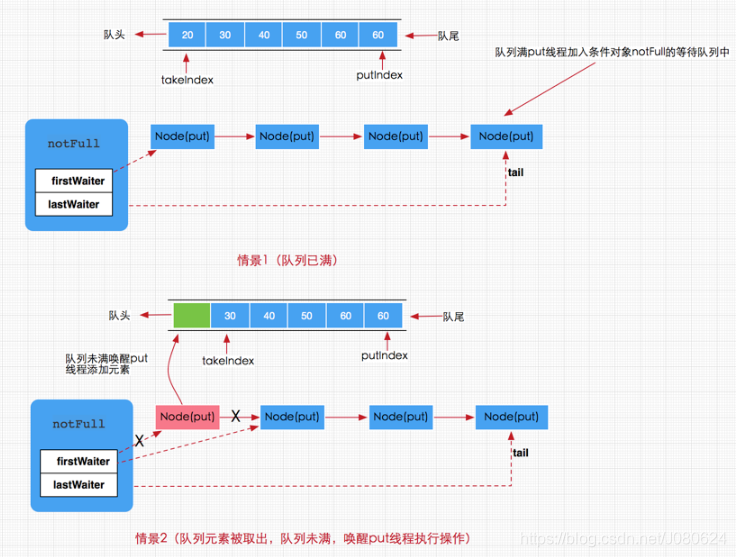
put方法是一个阻塞的方法,如果队列元素已满,那么当前线程将会被notFull条件对象挂起加到等待队列中,直到队列有空档才会唤醒执行添加操作。但如果队列没有满,那么就直接调用enqueue(e)方法将元素加入到数组队列中。
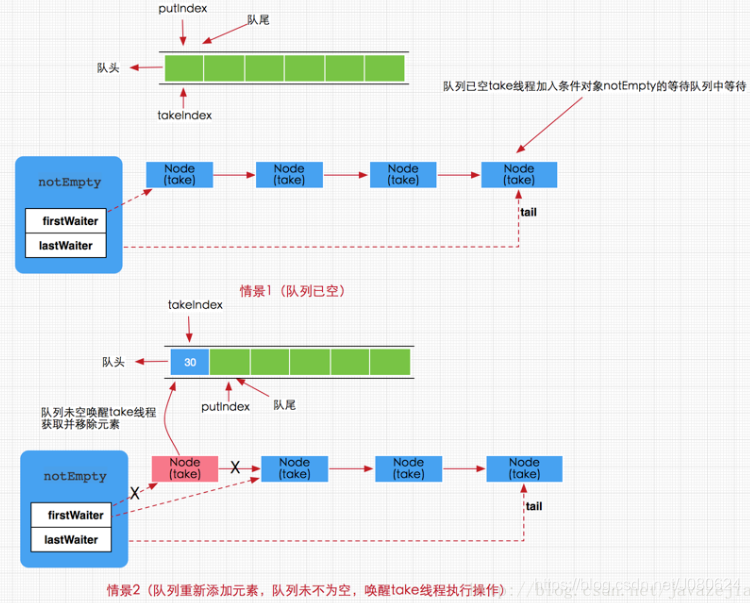
总得来说添加线程的执行存在以下两种情况:
- 队列已满,那么新到来的put线程将添加到notFull的条件队列中等待,
- 有移除线程执行移除操作,移除成功同时唤醒put线程,如下图所示 :
④ 核心操作移除元素
移除元素主要有poll、take与remove方法。
① poll
先看poll方法,该方法获取并移除此队列的头元素,若队列为空,则返回 null。
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
//判断队列是否为null,不为null执行dequeue()方法,否则返回null
return (count == 0) ? null : dequeue();
} finally {
lock.unlock();
}
}
//删除队列头元素并返回
private E dequeue() {
//拿到当前数组的数据
final Object[] items = this.items;
//获取要删除的对象
E x = (E) items[takeIndex];
// 将数组中takeIndex索引位置设置为null
items[takeIndex] = null;
//takeIndex索引加1并判断是否与数组长度相等,
//如果相等说明已到尽头,恢复为0
if (++takeIndex == items.length)
takeIndex = 0;
count--;//队列个数减1
if (itrs != null)
itrs.elementDequeued();//同时更新迭代器中的元素数据
//删除了元素说明队列有空位,唤醒notFull条件对象添加线程,执行添加操作
notFull.signal();
return x;
}
poll(),获取并删除队列头元素,队列没有数据就返回null,内部通过dequeue()方法删除头元素。
② remove(Object o) & removeAt
接着看remove(Object o)方法。
// 返回 true false
public boolean remove(Object o) {
if (o == null) return false;
//获取数组数据
final Object[] items = this.items;
final ReentrantLock lock = this.lock;
lock.lock();//加锁
try {
//如果此时队列不为null,这里是为了防止并发情况
if (count > 0) {
//获取下一个要添加元素时的索引
final int putIndex = this.putIndex;
//获取当前要被删除元素的索引
int i = takeIndex;
//执行循环查找要删除的元素
do {
//找到要删除的元素
if (o.equals(items[i])) {
// 这里触发了removeAt
removeAt(i);//执行删除
return true;//删除成功返回true
}
//当前删除索引执行加1后判断是否与数组长度相等
//若为true,说明索引已到数组尽头,将i设置为0
if (++i == items.length)
i = 0;
} while (i != putIndex);//继承查找
}
return false;
} finally {
lock.unlock();
}
}
//根据索引删除元素,实际上是把删除索引之后的元素往前移动一个位置
void removeAt(final int removeIndex) {
final Object[] items = this.items;
//先判断要删除的元素是否为当前队列头元素
if (removeIndex == takeIndex) {
//如果是直接删除
items[takeIndex] = null;
//当前队列头元素加1并判断是否与数组长度相等,若为true设置为0
if (++takeIndex == items.length)
takeIndex = 0;
count--;//队列元素减1
if (itrs != null)
itrs.elementDequeued();//更新迭代器中的数据
} else {
//如果要删除的元素不在队列头部,
//那么只需循环迭代把删除元素后面的所有元素往前移动一个位置
//获取下一个要被添加的元素的索引,作为循环判断结束条件
final int putIndex = this.putIndex;
//执行循环
for (int i = removeIndex;;) {
//获取要删除节点索引的下一个索引
int next = i + 1;
//判断是否已为数组长度,如果是从数组头部(索引为0)开始找
if (next == items.length)
next = 0;
//如果查找的索引不等于要添加元素的索引,说明元素可以再移动
if (next != putIndex) {
items[i] = items[next];//把后一个元素前移覆盖要删除的元
i = next;
} else {
// next == putIndex 说明移动完毕
// 清空最后一个元素
items[i] = null;
this.putIndex = i;
break;//结束循环
}
}
count--;//队列元素减1
if (itrs != null)
itrs.removedAt(removeIndex);//更新迭代器数据
}
notFull.signal();//唤醒添加线程
}
remove(Object o)方法的删除过程相对复杂些,因为该方法并不是直接从队列头部删除元素。
- 首先线程先获取锁,再一步判断队列count>0,这点是保证并发情况下删除操作安全执行。
- 接着获取下一个要添加源的索引putIndex以及takeIndex索引 ,作为后续循环的结束判断,因为只要putIndex与takeIndex不相等就说明队列没有循环完。
- 然后通过while循环找到要删除的元素索引,执行removeAt(i)方法删除。
- 在removeAt(i)方法中实际上做了两件事:
- 一是首先判断队列头部元素是否为删除元素,如果是直接删除,并唤醒添加线程,
- 二是如果要删除的元素并不是队列头元素,那么执行循环操作,从要删除元素的索引removeIndex之后的元素都往前移动一个位置,那么要删除的元素就被removeIndex之后的元素替换,从而也就完成了删除操作。
③ take
接着看take()方法,是一个阻塞方法,直接获取队列头元素并删除。
//从队列头部删除,队列没有元素就阻塞,可中断
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();//中断
try {
//如果队列没有元素
while (count == 0)
//执行阻塞操作
notEmpty.await();
return dequeue();//如果队列有元素执行删除操作
} finally {
lock.unlock();
}
}
take方法其实很简单,有就删除没有就阻塞,注意这个阻塞是可以中断的。如果队列没有数据那么就加入notEmpty条件队列等待(有数据就直接取走,方法结束)。如果有新的put线程添加了数据,那么put操作将会唤醒take线程,执行take操作。
图示如下 :
⑤ 核心操作获取元素
peek方法非常简单,直接返回当前队列的头元素但不删除任何元素:
public E peek() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
//直接返回当前队列的头元素,但不删除
return itemAt(takeIndex); // null when queue is empty
} finally {
lock.unlock();
}
}
final E itemAt(int i) {
return (E) items[i];
}
// element直接触发了 peek
public E element() {
E x = peek();
if (x != null)
return x;
else
throw new NoSuchElementException();
}
到这里我们就分析完了ArrayBlockingQueue,接下来我们分析LinkedBlockingQueue。
【4】LinkedBlockingQueue
LinkedBlockingQueue是一个由链表实现的有界阻塞队列,队列维持FIFO的元素次序。队列的头结点是留存时间最久的元素,队列的尾部 是在队列中时间最短的元素。新元素插入到队列的尾部,而队列执行获取操作会获得位于队列头部的元素。链表队列通常比基于数组的队列有更大的吞吐量,但在大多数并发应用中,性能不太可预测。
因为其内部实现添加和删除操作使用的两个ReenterLock来控制并发执行,而ArrayBlockingQueue内部只是使用一个ReenterLock控制并发,因此
LinkedBlockingQueue的吞吐量要高于ArrayBlockingQueue。
如果未指定capacity,LinkedBlockingQueue大小默认值为Integer.MAX_VALUE。所以建议使用带有capacity的构造函数。
① 核心成员和构造
① 核心成员
// 队列的最大容量,默认是Integer.MAX_VALUE
private final int capacity;
// 原子类, 记录当前元素的个数
private final AtomicInteger count = new AtomicInteger();
// 链表的头结点 head.item == nul
transient Node<E> head;
// 链表的尾结点 last.next == null
private transient Node<E> last;
// 被 take, poll 等移除元素的方法持有的锁
private final ReentrantLock takeLock = new ReentrantLock();
// notEmpty条件对象,用于阻塞或者唤醒 take poll 等
private final Condition notEmpty = takeLock.newCondition();
// 被 put, offer 等添加元素的方法持有的锁
private final ReentrantLock putLock = new ReentrantLock();
// notEmpty条件对象,用于阻塞或者唤醒 put offer 等
private final Condition notFull = putLock.newCondition();
② 核心构造
//默认大小为Integer.MAX_VALUE
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
//创建指定大小为capacity的阻塞队列
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
//创建大小默认值为Integer.MAX_VALUE的阻塞队列并添加c中的元素到阻塞队列
public LinkedBlockingQueue(Collection<? extends E> c) {
this(Integer.MAX_VALUE);
final ReentrantLock putLock = this.putLock;
putLock.lock(); // Never contended, but necessary for visibility
try {
int n = 0;
for (E e : c) {
if (e == null)
throw new NullPointerException();
if (n == capacity)
throw new IllegalStateException("Queue full");
enqueue(new Node<E>(e));
++n;
}
count.set(n);
} finally {
putLock.unlock();
}
}
通常建议创建指定大小的LinkedBlockingQueue阻塞队列。
③ 数据结构
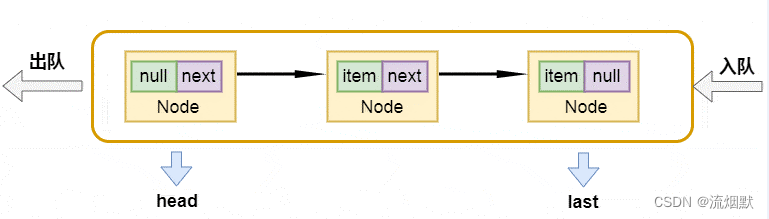
链表基本元素Node如下所示,其维护了数据和next指针用来形成单向链表。
static class Node<E> {
E item;
/**
* One of:
* - the real successor Node
* - this Node, meaning the successor is head.next
* - null, meaning there is no successor (this is the last node)
*/
Node<E> next;
Node(E x) { item = x; }
}
数据结构图示如下,其是一个单向链表,持有head和last结点指针。
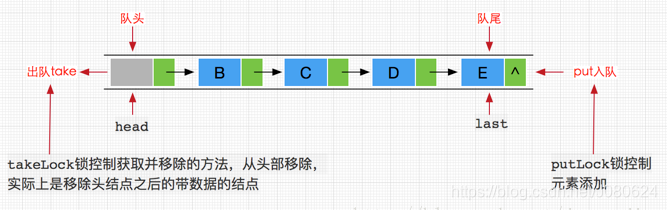
与ArrayBlockingQueue不同的是,LinkedBlockingQueue内部分别使用了takeLock 和 putLock 对并发进行控制。也就是说,添加和删除操作并不是互斥操作,可以同时进行,这样也就可以大大提高吞吐量。
至于LinkedBlockingQueue的实现原理图与ArrayBlockingQueue是类似的,除了对添加和移除方法使用单独的锁控制外,两者都使用了不同的Condition条件对象作为等待队列,用于挂起take线程和put线程。
② 核心操作添加元素
对于添加方法,主要指的是add,offer以及put,这里先看看add方法和offer方法的实现。
① add & offer
public boolean add(E e) {
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
}
从源码可以看出,add方法间接调用的是offer方法,如果add方法添加失败将抛出IllegalStateException异常,添加成功则返回true,那么下面我们直接看看offer的相关方法实现。
public boolean offer(E e) {
//添加元素为 null 直接抛出异常
if (e == null) throw new NullPointerException();
//获取队列的个数
final AtomicInteger count = this.count;
//判断队列是否已满
if (count.get() == capacity)
return false;
// 初始为-1 !!!
int c = -1;
//构建节点
Node<E> node = new Node<E>(e);
// 获取putLock 锁并加锁
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
//再次判断队列是否已满,考虑并发情况
if (count.get() < capacity) {
enqueue(node);//添加元素
//队列元素个数 原子性+1 然后赋予C
c = count.getAndIncrement();
//如果容量还没满 唤醒下一个添加线程,执行添加操作
if (c + 1 < capacity)
notFull.signal();
}
} finally {
putLock.unlock();//释放锁
}
// 注意哦,这个过程可能一直在take元素,所以 C 会变化
//这里的if条件表示如果队列中还有1条数据,那么就唤醒消费锁
if (c == 0)
signalNotEmpty();
return c >= 0; // 添加成功返回true,否则返回false
}
//入队操作,追加到队尾
private void enqueue(Node<E> node) {
//队列尾节点指向新的node节点
last = last.next = node;
}
//signalNotEmpty方法 前后进行了加锁、释放锁
private void signalNotEmpty() {
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
notEmpty.signal();
} finally {
takeLock.unlock();
}
}
② 两个唤醒时机分析
这里我们可能会有点疑惑,为什么添加完成后是继续唤醒在条件对象notFull上的添加线程而不是像ArrayBlockingQueue那样直接唤醒notEmpty条件对象上的消费线程?而又为什么要当if (c == 0)时才去唤醒消费线程呢?
唤醒添加线程的原因
在添加新元素完成后,会判断队列是否已满,不满就继续唤醒在条件对象notFull上的添加线程,这点与前面分析的ArrayBlockingQueue很不相同。
在ArrayBlockingQueue内部完成添加操作后,会直接唤醒消费线程对元素进行获取。这是因为ArrayBlockingQueue只用了一个ReenterLock同时对添加线程和消费线程进行控制,这样如果在添加完成后再次唤醒添加线程的话,消费线程可能永远无法执行。
而对于LinkedBlockingQueue来说就不一样了,其内部对添加线程和消费线程分别使用了各自的ReenterLock锁对并发进行控制,也就是说添加线程和消费线程是不会互斥的。
所以添加锁只要管好自己的添加线程即可,添加线程自己直接唤醒自己的其他添加线程。如果没有等待的添加线程,直接结束了。如果队列已满那么put线程将会挂起等待唤醒而offer方法并不会挂起,而是直接结束。注意消费线程的执行过程也是如此。这也是为什么LinkedBlockingQueue的吞吐量要相对大些的原因。
为什么要判断if (c == 0)时才去唤醒消费线程呢
这是因为消费线程一旦被唤醒是一直在消费的(前提是有数据),所以c值是一直在变化的。c值是添加完元素前队列的大小,此时c只可能是0或c>0。
如果是c=0,那么说明之前消费线程已停止,条件对象上可能存在等待的消费线程,添加完数据后应该是c+1,那么有数据就直接唤醒等待消费线程,如果没有就结束啦,等待下一次的消费操作。
那为什么不是条件c>0才去唤醒呢?我们要明白的是消费线程一旦被唤醒会和添加线程一样,一直不断唤醒其他消费线程。如果添加前c>0,那么很可能上一次调用的消费线程后,数据并没有被消费完,条件队列上也就不存在等待的消费线程了,所以c>0唤醒消费线程得意义不是很大。当然如果添加线程一直添加元素,那么一直c>0,消费线程执行的话就要等待下一次调用消费操作了(poll、take、remove)。
③ put
我们继续再看看put方法,可以看到与offer不同的是当队列满的时候put直接挂起阻塞等待被唤醒。
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
// Note: convention in all put/take/etc is to preset local var
// holding count negative to indicate failure unless set.
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
/*
* Note that count is used in wait guard even though it is
* not protected by lock. This works because count can
* only decrease at this point (all other puts are shut
* out by lock), and we (or some other waiting put) are
* signalled if it ever changes from capacity. Similarly
* for all other uses of count in other wait guards.
*/
// 如果队列满了,直接挂起等待被唤醒
while (count.get() == capacity) {
notFull.await();
}
// 添加元素 - 入队
enqueue(node);
// 统计个数自增 1
c = count.getAndIncrement();
// 唤醒其他添加线程
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
// 唤醒消费线程
if (c == 0)
signalNotEmpty();
}
③ 核心操作移除元素
关于移除的方法主要是指remove和poll以及take方法,下面一一分析。
① remove(Object o)
成功返回true,失败返回false。
public boolean remove(Object o) {
if (o == null) return false;
fullyLock();//同时对putLock和takeLock加锁
try {
//循环查找要删除的元素
for (Node<E> trail = head, p = trail.next;
p != null;
trail = p, p = p.next) {
if (o.equals(p.item)) {//找到要删除的节点
unlink(p, trail);//直接删除
return true;
}
}
return false;
} finally {
fullyUnlock();//解锁
}
}
//两个同时加锁
void fullyLock() {
putLock.lock();
takeLock.lock();
}
void fullyUnlock() {
takeLock.unlock();
putLock.unlock();
}
remove方法删除指定的对象,这里我们可能会诧异,为什么同时对putLock和takeLock加锁?这是因为remove方法删除的数据的位置不确定,为了避免造成并发安全问题,所以需要对2个锁同时加锁。
② poll
删除队列的头结点(实际删除的是head的next),如果不存在,返回null。如果存在,返回移除的结点(返回的是node.item)。
public E poll() {
//获取当前队列的大小
final AtomicInteger count = this.count;
if (count.get() == 0)//如果没有元素直接返回null
return null;
E x = null;
int c = -1;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
//判断队列是否有数据
if (count.get() > 0) {
//如果有,直接删除并获取该元素值
x = dequeue();
//当前队列大小减一
c = count.getAndDecrement();
//如果队列未空,继续唤醒等待在条件对象notEmpty上的消费线程
if (c > 1)
notEmpty.signal();
}
} finally {
takeLock.unlock();
}
//判断c是否等于capacity,这是因为如果满说明NotFull条件对象上
//可能存在等待的添加线程
if (c == capacity)
signalNotFull();
return x;
}
// 也就是把head.next 变成head
private E dequeue() {
Node<E> h = head;//获取头结点
// 获取头结的下一个节点(要删除的节点)
Node<E> first = h.next;
h.next = h; // help GC//自己next指向自己,即被删除
head = first;//更新头结点
E x = first.item;//获取删除节点的值
////清空数据,因为first变成头结点是不能带数据的,
//这样也就删除队列的带数据的第一个节点
first.item = null;
return x;
}
方法逻辑梳理如下:
- 如果队列没有数据就返回null,
- *如果队列有数据,那么就取出来,
- 如果队列还有数据那么唤醒等待在条件对象notEmpty上的消费线程。
- 然后判断if (c == capacity)为true就唤醒添加线程,这点与前面分析if(c==0)是一样的道理。因为只有可能队列满了,notFull条件对象上才可能存在等待的添加线程。
③ take
与poll不同的是,如果没有元素take将会阻塞等待,直到被唤醒(或者中断)。
public E take() throws InterruptedException {
E x;
int c = -1;
//获取当前队列大小
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();//可中断
try {
//如果队列没有数据,挂机当前线程到条件对象的等待队列中
while (count.get() == 0) {
notEmpty.await();
}
//如果存在数据直接删除并返回该数据
x = dequeue();
c = count.getAndDecrement();//队列大小减1
if (c > 1)
notEmpty.signal();//还有数据就唤醒后续的消费线程
} finally {
takeLock.unlock();
}
//满足条件,唤醒条件对象上等待队列中的添加线程
if (c == capacity)
signalNotFull();
return x;
}
下面再看看两个获取(但不移除)方法,即peek和element。
④ 核心操作获取元素
这里element、peek获取的是队列的头结点。这个头结点可不是head指针结点,而是第一个拥有数据的结点也就是head.next。
//构造方法,head 节点不存放数据
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
// 要么返回元素的item,要么抛出异常
public E element() {
E x = peek();//直接调用peek
if (x != null)
return x;
else
throw new NoSuchElementException();//没数据抛异常
}
// 队列为空,返回null,否则返回head.next.item
public E peek() {
if (count.get() == 0)
return null;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
//获取头结节点的下一个节点
Node<E> first = head.next;
if (first == null)
return null;//为null就返回null
else
return first.item;//返回值
} finally {
takeLock.unlock();
}
}
⑥ 指定时间阻塞添加
下面我们最后来看两个根据时间阻塞的方法,比较有意思,利用Conditin来实现的。
//在指定时间内阻塞添加的方法,超时就结束
public boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException {
if (e == null) throw new NullPointerException();
//将时间转换成纳秒
long nanos = unit.toNanos(timeout);
int c = -1;
//获取锁
final ReentrantLock putLock = this.putLock;
//获取当前队列大小
final AtomicInteger count = this.count;
//锁中断(如果需要)
putLock.lockInterruptibly();
try {
//如果队列满了,就等待
while (count.get() == capacity) {
if (nanos <= 0)
return false;
//如果队列满根据阻塞的等待
nanos = notFull.awaitNanos(nanos);
}
//队列没满直接入队
enqueue(new Node<E>(e));
c = count.getAndIncrement();
//唤醒条件对象上等待的线程
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
//唤醒消费线程
if (c == 0)
signalNotEmpty();
return true;
}
对于这个offer方法,我们重点来看看阻塞的这段代码。
//如果队列满 阻塞等待 nanos
while (count.get() == capacity) {
if (nanos <= 0)
return false;
nanos = notFull.awaitNanos(nanos);
}
// java.util.concurrent.locks.AbstractQueuedSynchronizer.ConditionObject#awaitNanos
//CoditionObject(Codition的实现类)中的awaitNanos方法
public final long awaitNanos(long nanosTimeout)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
//这里是将当前添加线程封装成NODE节点加入Condition的等待队列中
//注意这里的NODE是AQS的内部类Node
Node node = addConditionWaiter();
//加入等待,那么就释放当前线程持有的锁
int savedState = fullyRelease(node);
//计算过期时间
final long deadline = System.nanoTime() + nanosTimeout;
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
if (nanosTimeout <= 0L) {
transferAfterCancelledWait(node);
break;
}
//主要看这里!!由于是while 循环,这里会不断判断等待时间
//nanosTimeout 是否超时
//static final long spinForTimeoutThreshold = 1000L;
if (nanosTimeout >= spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanosTimeout);//挂起线程
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
//重新计算剩余等待时间,while循环中继续判断下列公式
//nanosTimeout >= spinForTimeoutThreshold
nanosTimeout = deadline - System.nanoTime();
}// while循环结束的地方
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null)
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
return deadline - System.nanoTime();
}
awaitNanos方法中,根据传递进来的时间计算超时阻塞nanosTimeout。然后通过while循环中判断nanosTimeout >= spinForTimeoutThreshold 该公式是否成立。当其为true时则说明超时时间nanosTimeout 还未到期,再次计算nanosTimeout = deadline - System.nanoTime();持续判断,直到nanosTimeout 小于spinForTimeoutThreshold结束超时阻塞操作,方法也就结束。
这里的spinForTimeoutThreshold其实更像一个经验值,因为非常短的超时等待无法做到十分精确,因此采用了spinForTimeoutThreshold这样一个临界值。
offer(E e, long timeout, TimeUnit unit)方法内部正是利用这样的Codition的超时等待awaitNanos方法实现添加方法的超时阻塞操作。同样对于poll(long timeout, TimeUnit unit)方法也是一样的道理。
【5】LinkedBlockingQueue和ArrayBlockingQueue对比
① 队列大小有所不同
ArrayBlockingQueue是有界的初始化必须指定大小,而LinkedBlockingQueue可以是有界的也可以是无界的(Integer.MAX_VALUE)。对于后者而言,当添加速度大于移除速度时,在无界的情况下,可能会造成内存溢出等问题。
② 数据存储容器不同
ArrayBlockingQueue采用的是数组作为数据存储容器,而LinkedBlockingQueue采用的则是以Node节点作为连接对象的链表。
③ GC回收
由于ArrayBlockingQueue采用的是数组的存储容器,因此在插入或删除元素时不会产生或销毁任何额外的对象实例,而LinkedBlockingQueue则会生成一个额外的Node对象。这可能在长时间内需要高效并发地处理大批量数据时,对于GC可能存在较大影响。
④ 两者的实现队列添加或移除的锁不一样
ArrayBlockingQueue实现的队列中的锁是没有分离的,即添加操作和移除操作采用的同一个ReenterLock锁。
而LinkedBlockingQueue实现的队列中的锁是分离的,其添加采用的是putLock,移除采用的则是takeLock。
这样能大大提高队列的吞吐量,也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。

















 1240
1240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









