




 本文详细介绍了如何利用CTF-wiki学习heap exploitation,通过两个实例展示了如何利用堆溢出、UAF和格式化字符串漏洞进行内存操纵,实现chunk overlapping和任意地址读写,最终达到代码执行的目的。涉及的知识点包括ptmalloc、fastbin、tcachebins、chunk extend、fini_array等。
本文详细介绍了如何利用CTF-wiki学习heap exploitation,通过两个实例展示了如何利用堆溢出、UAF和格式化字符串漏洞进行内存操纵,实现chunk overlapping和任意地址读写,最终达到代码执行的目的。涉及的知识点包括ptmalloc、fastbin、tcachebins、chunk extend、fini_array等。
CTF-wiki真是太好一学习网站了。
原文链接:https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/chunk-extend-overlapping/#_1
Chunk Extend
实现条件
要实现chunk extend需要满足的条件:有堆漏洞,并且该漏洞可以修改chunk header里的数据。
实现原理
原理大概就是:
①:ptmalloc通过chunk header里面的prev_size和size来对前后堆块进行定位。
②:ptmalloc通过查看下一个堆的prev_inuse值来判断该chunk是否被使用。(不能通过prev_size来判断,因为虽然**”该chunk为空时,下一个堆块的pre_size会记录该chunk的大小。“**但是不能判断pre_size里记录的数据到底是上一个chunk的size还是上一个chunk的末尾数据)
因此我们如果能控制chunk header里面的数据,就可以导致chunk overlapping,可以控制chunk里面的内容,如果可以控制的chunk内容范围里存在指针等,就可以修改指针值达到任意地址读写或者控制程序流程。
实现步骤
个人笔记:①:fastbin由于追求效率,安全检验机制机制较弱,free时找到fastbin链表中符合大小的堆块就直接加入了,不会检测pre_insue的值。同时,物理地址相邻的fastbin不会合并。
②:fastbin的最大使用范围为0x70,若不属于fastbin,在合并时会与topchunk合并。因此free的堆块必须和top chunk中间需要有一个小堆块将这两者隔开。
③:通过extend前向overlapping,利用的是unlink机制,修改free掉的堆块的prev_insue值和prev_size值即可。
具体见上文中链接。
例题一
链接:https://pan.baidu.com/s/1gJCCP81xegAFZGPs7hJVRw
提取码:F1re
很友好的一道题,题目是常见的菜单。
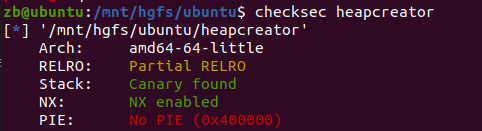
checksec一下:
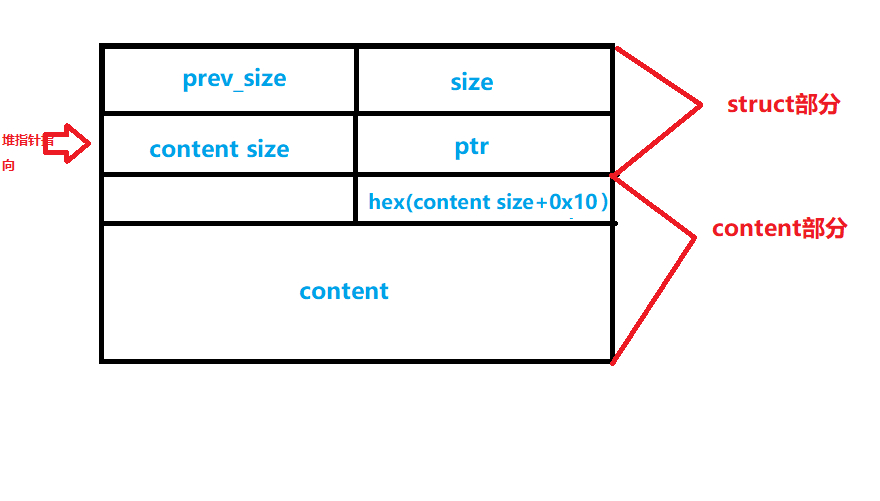
gdb调试后还原堆结构体:
-
功能一:create_heap:在选择创造堆块的功能时,系统会先自动分配了0x20的内存,拿来存放结构体。然后可以分配用户输入的大小的堆。
-
功能二:edit_heap:能修改堆块的content值,查看read_input函数后发现存在off-by-one漏洞,可以通过该漏洞在一定条件下覆盖下一个堆块的size值。
-
功能三:show_heap:将content size的值和content打印出来。
-
功能四:delete_heap:先free掉我们的content部分,然后free掉系统帮我们自动申请的struct部分,最后将堆指针置为零。
基本思路
该题满足了实现chunk-extend的两个条件。因此我的基本思路是:
①:创建两个堆,利用edit_heap函数的off-by-one漏洞修改第一个堆的content值,然后覆盖修改第二个堆的chunk header里面的size值。
②:通过delete_heap函数free掉第二个堆,再通过create_heap函数重新申请回来,造成chunk-overlapping,即可使chunk header里的指针域处于可修改的content域中,可控制指针,达到任意地址跳转和读写。
③:改写free_got成system函数地址,并在free的参数里放置“/bin/sh",最后利用delete_heap函数调用free函数实现get shell。
实现步骤①:
这是正常创建两个堆后的内存图,content size均为0x10.
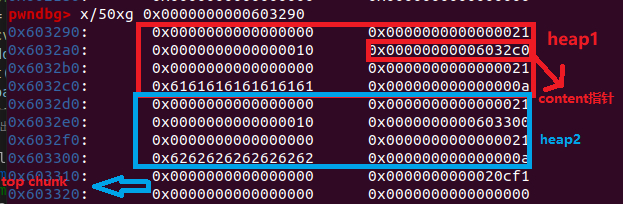
由于我们能输入到content里面的数据是content size+1个,因此我们最多只能覆盖到0x6032d0的第一个字节,也就是覆盖到第二个堆块的prev_size字节。但我们知道,前一个堆不为空的时候,该堆的prev_size是不起作用的,置为0,而此时该堆的prev_size是可以拿来储存物理相邻的前一个堆的数据的(该机制被称为chunk 的空间复用)。且根据堆分配机制,用户请求的字节是拿来储存数据的,若我们一开始给heap1请求0x18的内存,由于chunk空间复用的关系,系统只会多分配0x10的内存给heap1,而由于edit_heap函数里的:
read_input(*((void **)*(&heaparray + v1) + 1), *(_QWORD *)*(&heaparray + v1) + 1LL);
因此我们可以读入0x19个字符,此时就可以覆盖到heap2的size字段。
实操:
先定义基本操作函数:
def create(size,content):
r.recvuntil(b":")
r.sendline(b'1')
r.recvuntil(b"Size of Heap : ")
r.sendline(str(size))
r.recvuntil(b"Content of heap:")
r.sendline(content)
def edit(index,content):
r.recvuntil(b":")
r.sendline(b'2')
r.recvuntil(b"Index :")
r.sendline(str(index))
r.recvuntil(b"Content of heap : ")
r.sendline(content)
def show(id):
r.recvuntil(b":")
r.sendline(b'3')
r.recvuntil(b"Index :")
r.sendline(str(id))
def delete(id):
r.recvuntil(b":")
r.sendline(b'4')
r.recvuntil(b"Index :")
r.sendline(str(id 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 133
133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









