




 本文介绍了Spark独立集群模式,包括ClusterManager、WorkerNode、Executor和DriverProgram的角色,强调了Driver与Executor的通信和隔离性。此外,详细讲解了如何将Java SpringBoot Maven应用打包为uber jar并提交到Spark集群,包括解决jar包冲突的方法,特别是针对gson、snakeYaml和slf4j的冲突解决方案。
本文介绍了Spark独立集群模式,包括ClusterManager、WorkerNode、Executor和DriverProgram的角色,强调了Driver与Executor的通信和隔离性。此外,详细讲解了如何将Java SpringBoot Maven应用打包为uber jar并提交到Spark集群,包括解决jar包冲突的方法,特别是针对gson、snakeYaml和slf4j的冲突解决方案。
一、ClusterMode
http://spark.apache.org/docs/latest/cluster-overview.html
1、所编写的Spark应用在Spark集群中以独立进程的方式运行,由应用中的SparkContext对象来处理与Spark集群的协同。
2、SparkContext可以连接到多种集群管理器,包括Spark standalone cluster,Mesos 或 YARN。
3、Spark ClusterMode 组件:
(1)ClusterManager 集群管理器
(2)WorkerNode 集群中的节点
(3)Executor执行器:用于数据的计算和存储
(4)DriverProgram 持有SparkContext对象的应用实例
一旦SparkContext与ClusterManager连接,ClusterManager会去各节点获取可用的Executor,并将应用传递给SparkContext的代码发送给Executor,最后由SparkContext发送任务到Executor执行。
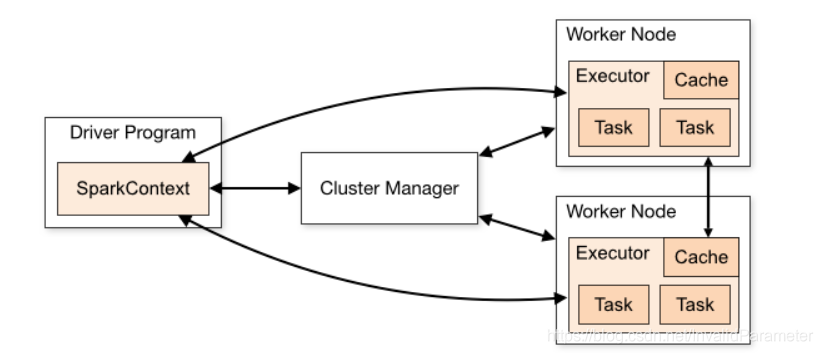
4、每个Executor进程只能同时分配给一个DriverProgram,也就是说每个DriverProgram之间是相互隔离的,他们之间无法直接发生数据的交互。当然,我们可以单独找一个数据库将这些数据存储在一起。
5、DriverProgram与Executor之间的通信是双向的,所以当DriverProgram与Executor在不同服务器时,需要指定DriverProgram
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 324
324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









