




 本文介绍如何使用Python进行数据分析,详细步骤包括导入模块、读取数据、数据清洗、合并数据和汇总,以统计导演与演员的合作次数,并探讨关系网络的可视化方法。
本文介绍如何使用Python进行数据分析,详细步骤包括导入模块、读取数据、数据清洗、合并数据和汇总,以统计导演与演员的合作次数,并探讨关系网络的可视化方法。
版权声明:本文为博主原创文章,未经博主允许不得转载。
- 将数据中导演与演员的关系整理出来,得到导演与演员的关系数据,并统计合作次数
一、导入模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# 不发出警告
import warnings
warnings.filterwarnings('ignore')
二、读取数据
import os
os.chdir('C:/Users/lsj/Desktop/')
df = pd.read_excel('豆瓣电影数据.xlsx', sheet_name = 0, header = 0)
# 数据总条数
l = len(df)
print('数据总共%i条'% l)
# 数据字段
cols = df.columns.tolist()
print('数据字段为:\n', cols)

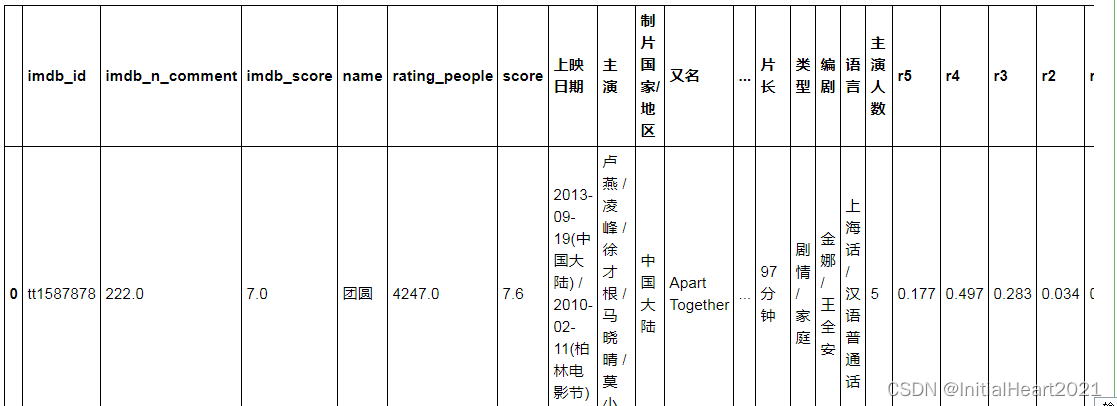
三、数据清洗
data = df[['name', '导演', '主演']]
data.dropna(inplace = True)
data.head()
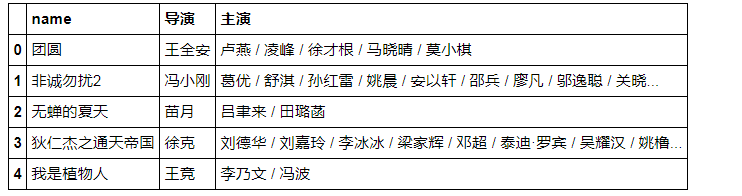
data_yy = data['主演'].str.split('/', expand = True)
col_len_1 = len(data_yy.columns)
data_yy.columns = ['yy'+ str(i) for i in range(col_len_1)]
print(data_yy.head())

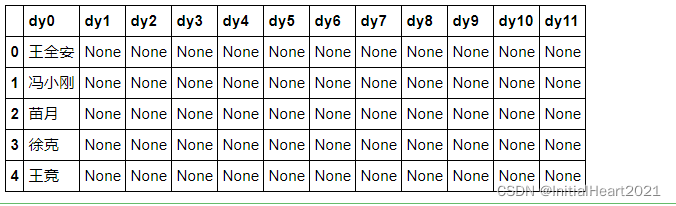
data_dy = data['导演'].str.split('/', expand = True)
col_len_2 = len(data_dy.columns)
data_dy.columns = ['dy' + str(i) for i in range(col_len_2)]
print(data_dy.head())
data_2 = data_dy.join(data_yy).join(data['name'])
print(data_2.head())

四、合并数据
data_re = pd.DataFrame(columns = ['name', '导演', '演员'])
# 创建一个空的 DataFrame
col_yy = data_yy.columns
col_dy = data_dy.columns
for dy in col_dy:
for yy in col_yy:
# 提取数据
data_i = data_2[['name', dy, yy]].dropna()
# 列名重命名
data_i.columns = ['name', '导演', '演员']
# 添加数据
data_re = pd.concat([data_re, data_i])
print(data_re)
# 遍历数据后,得到一个导演与演员的关系数据,并做去重处理
# 这里index是有重复的,但作为过程数据可忽略

五、汇总数据
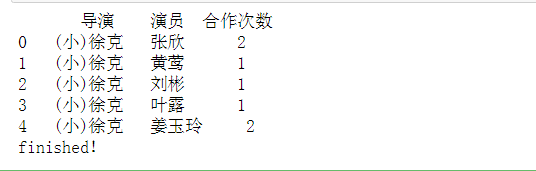
# 汇总统计导演和演员的合作次数
# 按照导演——演员进行计数统计,得到结果数据
result = data_re.groupby(['导演', '演员']).count()
result.reset_index(inplace = True) # 将所有索引级别转换为列
result.columns = ['导演', '演员', '合作次数']
# 存为excel
# 注意:output.xlsx 文件不能是打开状态
writer = pd.ExcelWriter('output.xlsx')
result.to_excel(writer, 'sheet1')
writer.save()
print('Finished !')
版权声明:本文为博主原创文章,未经博主允许不得转载。


















 1385
1385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











