




 这篇论文介绍了StereoNet,一种利用神经网络实现高效、精确亚像素级立体匹配的方法。它展示了低分辨率costvolume也能达到高精度,并减少了传统方法的冗余参数,降低了计算成本和存储需求。实验在KITTI 12和15数据集上验证了其优越性能。
这篇论文介绍了StereoNet,一种利用神经网络实现高效、精确亚像素级立体匹配的方法。它展示了低分辨率costvolume也能达到高精度,并减少了传统方法的冗余参数,降低了计算成本和存储需求。实验在KITTI 12和15数据集上验证了其优越性能。
【论文学习笔记-11】StereoNet(Google ECCV)
又一篇快速立体匹配文章。
Contribution
①证明了基于神经网络的亚像素级别匹配的精度比传统方法高一个数量级
②通过一个低分辨率的costvolume就可以达到高精度的亚像素级别匹配精度
③说明了之前的方法使用的costvolume的参数冗余了,通过本文的方法可以显著降低运算时间和存储空间,代价的很小的精度损失。
网络

模型采用two-stage approach
首先提取特征,使用的是siamise网络结构,提取低分辨率特征。其中用了K个stride=2的55卷积,K=3/4,channel控制在32。之后使用过了6个残差块的33卷积。
这样提取的特征有两个好处。
- 感受野大,适用于纹理缺失区域
- 它是特征向量紧凑
之后提取CostVolume,还是采用直接拼接特征的方式获取4D Costvolume,之后经过4个3D卷积层获取维度为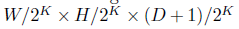
的特征向量。采用Softargmin做视差预测。
最后是Hierarchical Refinement网络:获取粗视差图后,首先通过双线性上采样到原图大小。
之后采用了上采样-卷积的方式。把视差图和原图(RGB三通道)concat在一起然后经过卷积成为32维的特征图,再经过6个残差块。使用了1-2-4-8-1-1的dialation,,最后经过一个3*3的卷积。这个结果和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 832
832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









