






 本文详细介绍R语言的基础知识,包括对象类型、数据结构如向量、矩阵、数据框、列表及时间序列,数据读写,绘图,数值处理,以及矩阵运算等内容。适合初学者快速掌握R语言的基本操作。
本文详细介绍R语言的基础知识,包括对象类型、数据结构如向量、矩阵、数据框、列表及时间序列,数据读写,绘图,数值处理,以及矩阵运算等内容。适合初学者快速掌握R语言的基本操作。
对象
R是通过一些特定的对象来运行的。所有对象都有两个内在属性:类型和长度。类型分为数值型、字符型、复数型和逻辑型。对象的类型和长度可以用mode()和length()来得到。
下表给出了对象类型的概览:

注:如果不允许多种数据类型的对象中存在不同种类数据,那么R会自动转换,向高级别。如:
> x<-c(12,"ss")
> x
[1] "12" "ss"
缺失值用NA来表示。
转义字符,和其他语言(C、Python)类似。例如:
> x<-"please print this sentense \"I love you\""
> x
[1] "please print this sentense \"I love you\""
> cat(x)
please print this sentense "I love you"
读取数据
工作目录,也就是R自动调用的硬盘地址,可以自行更改。
getwd():获取工作目录
setwd():设置工作目录
注:相对地址和绝对地址的概念,以及\和/的区别。
read.table()
scan()
read.csv()
read.xlsx() 此函数需要调用相关package,如下:
#载入excel数据
library(xlsxjars)
library(rJava)
library(xlsx)
存储数据
write.table()
write.csv()
write.xlsx() 同read.xlsx()
存储图片
1.用Rstudio里面的export按钮,粘贴或者保存,up to u
2.写函数批量化进行。因为有时候会跑很多次,或者跑很多个函数,所以批量化操作还是很重要的。
首先,对单个图像文件的处理:
#设置你想要的图片参数
png(file="plot_sample.png",width=120,height=80)
#绘图
plot(carat, price, data=dsamp, colour=clarity)
#关闭设备
dev.off()
然后,批量化处理(根据需要自行修改细节):
#定义函数
tsgraphfunction<-function(x){
temp<-get(x)
name<-paste(x,"_plot",".png",sep='')
png(name,width=1200,height=600)
plot(temp)
dev.off()
}
#生成时序图
names.ts<-paste(names.variable,"_ts",sep = "")
for(i in names.ts){
tsgraphfunction(i)
}
生成数据
无论是数据清洗还是绘图,还是挑选test set,有时候会需要生成一个有序or有规则or随机产生的数列。
1.规则数据
直接生成数列:
> 1:10
[1] 1 2 3 4 5 6 7 8 9 10
seq(from,to,by):
> seq(1,10,2)
[1] 1 3 5 7 9
rep():同一个数列反复n次
> rep(1:2,3)
[1] 1 2 1 2 1 2
键盘直接输入(scan()):当键入空白内容时,自动退出函数
> x<-scan()
1: 1
2: 4
3: 5
4: 6
5: 7
6:
Read 5 items
> x
[1] 1 4 5 6 7
2.随机数据
随机数据主要用在抽样中,比如机器学习测试集和训练集的划分。

对象的具体操作
1.创建对象
R中的对象类型大致有以下几种:
- 向量
c():将不同的向量或者列表合并。
vector():创建新向量。可以指定长度和元素数据类型,因此可以先声明(创建)向量,再往里面赋值,这在循环操作里面很常见。如下:
> x<-vector(mode="numeric",length = 5); x[1]=5;x[2]=6
> x
[1] 5 6 0 0 0
- 因子
因子可以简单的理解为带有水平标签的向量。比如一群人是一个向量,里面分为男的和女的。因子具有因子水平(Levels),用于限制因子的元素的取值范围,R强制:因子水平是字符类型,因子的元素只能从因子水平中取值,这意味着,因子的每个元素要么是因子水平中的字符(或转换为其他数据类型),要么是缺失值,这是因子的约束,是语法上的规则。
这个东西有点复杂,一言难尽。 - 矩阵
method1
matrix():其中byrow这个参数用来申明按行还是按列排列,默认按列(F)
> x<-matrix(1:12,nrow=3,ncol = 4)
> x
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
> x<-matrix(1:12,nrow=3,ncol = 4,byrow=T)
> x
[,1] [,2] [,3] [,4]
[1,] 1 2 3 4
[2,] 5 6 7 8
[3,] 9 10 11 12
method2
dim()函数可以用来指定对象的维数。因此,也可以用来生成矩阵。
> x<-c(1:12); dim(x)<-c(3,4)
> x
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
- 数据框
数据框是最常用的数据结构,也是最直观易懂的一种。和excel表极其类似。
很多函数return的对象就是数据框,比如read.table()。
> x1<-c(1:3); x2<-c("a","b","c")
> x<-data.frame(NO1=x1,NO2=x2,row.names = c("boy","girl","NAA"))
> x
NO1 NO2
boy 1 a
girl 2 b
NAA 3 c
row.names()可以用来给数据框的行命名和重命名:
> row.names(x)<-c("1","2","3")
> x
NO1 NO2
1 1 a
2 2 b
3 3 c
names()可以用来给数据框的列命名和重命名:
> names(x)<-c("col1","col2")
> x
col1 col2
1 1 a
2 2 b
3 3 c
- 列表
这个类型太自由了。 - 时间序列
时间序列分析的对象类型。
ts():创建时间序列对象。
> data<-c(1:12)
> ts(data, frequency = 4, start = c(2018, 1)) #季度
Qtr1 Qtr2 Qtr3 Qtr4
2018 1 2 3 4
2019 5 6 7 8
2020 9 10 11 12
> ts(data, frequency = 12, start = c(2018, 1)) #月度
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
2018 1 2 3 4 5 6 7 8 9 10 11 12
> ts(data, frequency = 1, start = c(2018, 1)) #年度
Time Series:
Start = 2018
End = 2029
Frequency = 1
[1] 1 2 3 4 5 6 7 8 9 10 11 12
> ts(data, frequency = 1, start = 2018) #年度
Time Series:
Start = 2018
End = 2029
Frequency = 1
[1] 1 2 3 4 5 6 7 8 9 10 11 12
> ts(data, frequency = 12, start = 2018) #月度
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
2018 1 2 3 4 5 6 7 8 9 10 11 12
值得注意的是,start参数,默认c(a,b)中的b=1
7. 表达式
表达式(Expression)可以生成一个不被立刻求解的表达式。用eval()可以得到结果。
> x<-2; y<-4
> z<-expression(x+y)
> eval(z)
[1] 6
2.对象类型转换
在R中,主要用as.***形式的函数来进行转换。

运算符以及运算先后顺序

另外需要注意的这个函数:
identical():判断两个对象是否完全相等。
> identical(x=12,y=13)
[1] FALSE
> identical(x=12,y=12)
[1] TRUE
访问对象元素
注意:
- R语言的下标是从1开始,而不是从0开始。
- 既然可以访问元素,那么就可以通过访问元素来赋值,或者替换元素。
- 访问对象元素过程中,经常会出现数据类型降维的情况,可以通过以下方法解决(drop参数):
> x<-data.frame(NO1=x1,NO2=x2,row.names = c("boy","girl","NAA"))
> x
NO1 NO2
boy 1 a
girl 2 b
NAA 3 c
> temp<-x[,1]
> temp
[1] 1 2 3
> class(temp)
[1] "integer"
> temp<-x[,1,drop=F]
> temp
NO1
boy 1
girl 2
NAA 3
> class(temp)
[1] "data.frame"
访问对象名称
names是一个对象元素的字符型标签, 它们一般情况下是可选的属性, 名
称有多个种类(names, colnames, rownames, dimnames)。
names是一个和对象有同样长度的向量并且可以通过函数names来访问。
> x<-data.frame(NO1=x1,NO2=x2,row.names = c("boy","girl","NAA"))
> names(x)
[1] "NO1" "NO2"
> rownames(x)
[1] "boy" "girl" "NAA"
> colnames(x)
[1] "NO1" "NO2"
> dimnames(x)
[[1]]
[1] "boy" "girl" "NAA"
[[2]]
[1] "NO1" "NO2"
数值处理
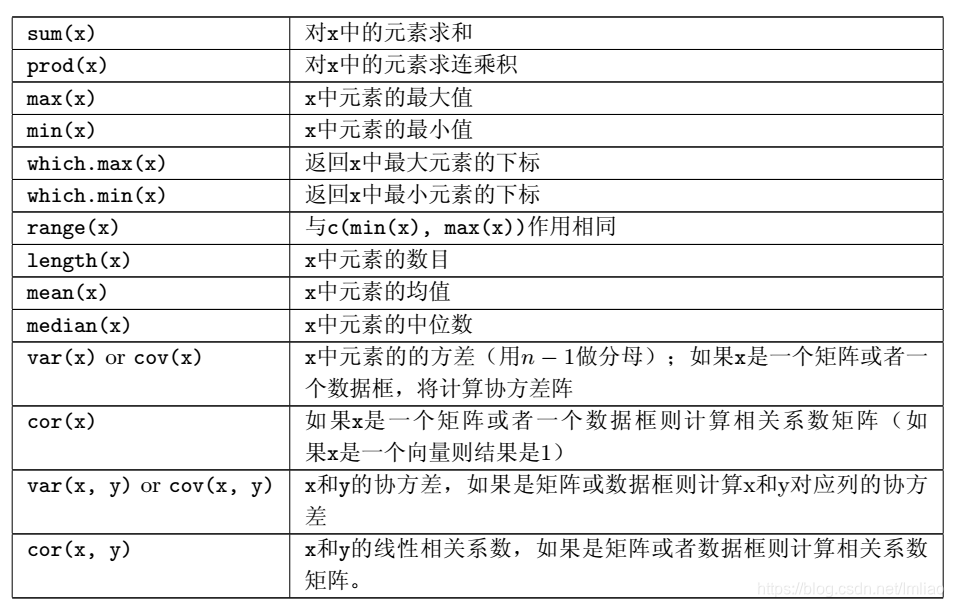
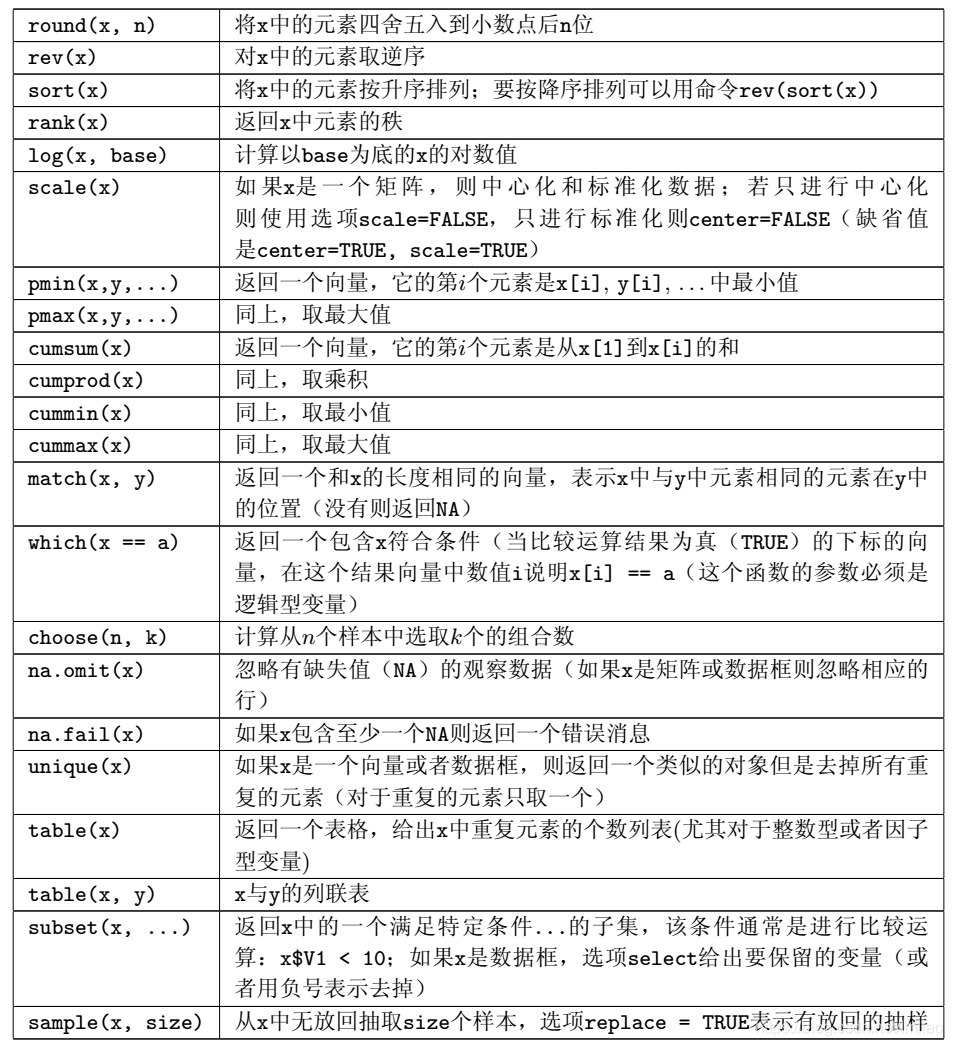
矩阵运算
R语言的矩阵运算能力很强。
1.矩阵合并
rbind()
cbind()
2.矩阵转置(t())
R中矩阵的转置可以用t()函数完成:
> x<-matrix(1:12,nr=3,nc=4)
> x
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
> x<-t(x)
> x
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
[3,] 7 8 9
[4,] 10 11 12
3.矩阵乘法(%*%)
> x<-matrix(1:12,nr=3,nc=4)
> y<-matrix(13:24,nr=4,nc=3)
> x%*%y
[,1] [,2] [,3]
[1,] 334 422 510
[2,] 392 496 600
[3,] 450 570 690
4.矩阵数乘
> x
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
> 3*x
[,1] [,2] [,3] [,4]
[1,] 3 12 21 30
[2,] 6 15 24 33
[3,] 9 18 27 36
5.矩阵加(减)法
> x<-matrix(1:12,nr=3,nc=4)
> y<-matrix(13:24,nr=3,nc=4)
> x-y
[,1] [,2] [,3] [,4]
[1,] -12 -12 -12 -12
[2,] -12 -12 -12 -12
[3,] -12 -12 -12 -12


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









