






 本文通过一个具体的数据集,详细介绍了如何进行数据预处理、构建及训练神经网络模型,并使用相关系数评估了模型性能。
本文通过一个具体的数据集,详细介绍了如何进行数据预处理、构建及训练神经网络模型,并使用相关系数评估了模型性能。
数据集准备
这里使用一个宏观数据集,因变量是Y,一共有六个自变量,共计228条记录。数量有点少,不过凑合着用用吧。
> head(data_csdn)
Y X1 X2 X3 X4 X5 X6
1 5.361104 4.531524 9.392412 4.593098 7.886871 3.018472 2.8848007
2 5.284320 4.550292 9.455950 4.592085 7.839289 3.739573 0.7419373
3 5.678670 4.560487 9.336268 4.587006 7.784515 4.295924 2.1972246
4 5.657459 4.552824 9.325899 4.582925 7.765060 4.628887 2.2082744
5 5.676377 4.542443 9.295508 4.582925 7.768110 4.934690 2.1860513
6 5.701146 4.533030 9.294773 4.583947 7.795153 5.223917 2.2082744
> nrow(data_csdn)
[1] 228探索性数据分析
由于多层前馈神经网络需要输入值为0附近小范围的数据,因此,我们需要进行一下探索性数据分析,以便于判断是否进行中心化处理。
> summary(data_csdn)
Y X1 X2 X3 X4 X5 X6
Min. :5.284 Min. :4.405 Min. : 9.295 Min. :4.583 Min. : 7.765 Min. :2.908 Min. :-1.470
1st Qu.:6.630 1st Qu.:4.506 1st Qu.: 9.820 1st Qu.:4.613 1st Qu.: 8.341 1st Qu.:5.275 1st Qu.: 2.089
Median :7.557 Median :4.586 Median :10.344 Median :4.623 Median : 9.093 Median :5.956 Median : 2.481
Mean :7.307 Mean :4.611 Mean :10.345 Mean :4.625 Mean : 9.086 Mean :5.801 Mean : 2.381
3rd Qu.:8.068 3rd Qu.:4.733 3rd Qu.:10.924 3rd Qu.:4.635 3rd Qu.: 9.844 3rd Qu.:6.494 3rd Qu.: 2.773
Max. :8.316 Max. :4.875 Max. :11.369 Max. :4.689 Max. :10.455 Max. :7.178 Max. : 3.347 我们发现,Y、X2等特征范围比较大,因此需要进行中心化(标准化)处理。
有两种中心化(标准化)处理方法:
- (数据-均值)/标准差
这个方法可以用R里面的scale()函数来实现。
#center:是否中心化
#scale:是否标准化
scale(x, center = TRUE, scale = TRUE)- (数据-min)/(max-min)
这个暂时没有现成的方法,可以自定义函数来实现。
normalize<-function(x){
return((x-min(x))/(max(x)-min(x)))
}
data_normal<-as.data.frame(lapply(data_csdn,normalize)) 现在我们来看看是否达到了我们的目的:
> summary(data_normal)
Y X1 X2 X3 X4 X5 X6
Min. :0.0000 Min. :0.0000 Min. :0.0000 Min. :0.0000 Min. :0.0000 Min. :0.0000 Min. :0.0000
1st Qu.:0.4438 1st Qu.:0.2147 1st Qu.:0.2534 1st Qu.:0.2859 1st Qu.:0.2140 1st Qu.:0.5543 1st Qu.:0.7387
Median :0.7496 Median :0.3839 Median :0.5060 Median :0.3784 Median :0.4935 Median :0.7138 Median :0.8201
Mean :0.6671 Mean :0.4376 Mean :0.5062 Mean :0.3970 Mean :0.4910 Mean :0.6774 Mean :0.7995
3rd Qu.:0.9180 3rd Qu.:0.6967 3rd Qu.:0.7855 3rd Qu.:0.4903 3rd Qu.:0.7727 3rd Qu.:0.8399 3rd Qu.:0.8807
Max. :1.0000 Max. :1.0000 Max. :1.0000 Max. :1.0000 Max. :1.0000 Max. :1.0000 Max. :1.0000 各个特征值的max和min均为0和1,OK!
划分训练集和测试集
考虑到在划分过程中,测试集和训练集都要具有对原始集的代表性,所以这里使用随机抽样的原理进行划分:
set.seed(33333)
data_rand<-data_normal[order(runif(nrow(data_normal))),]
data_train<-data_rand[1:205,]
data_test<-data_rand[206:228,]训练模型
简单介绍三个R中可以做神经网络的package:
- neuralnet:常用,本文只用的就是这个;
- nnet:R原生库自带,最常用;
- RSNNS:功能最强大,学习成本也最高。
使用前安装加载:
install.packages("neuralnet")
library(neuralnet)训练一个仅含一个hidden layer的神经网络:
neuromodel<-neuralnet(Y~X1+X2+X3+X4+X5+X6,data=data_train,hidden=1)神经网络可视化:
plot(neuromodel)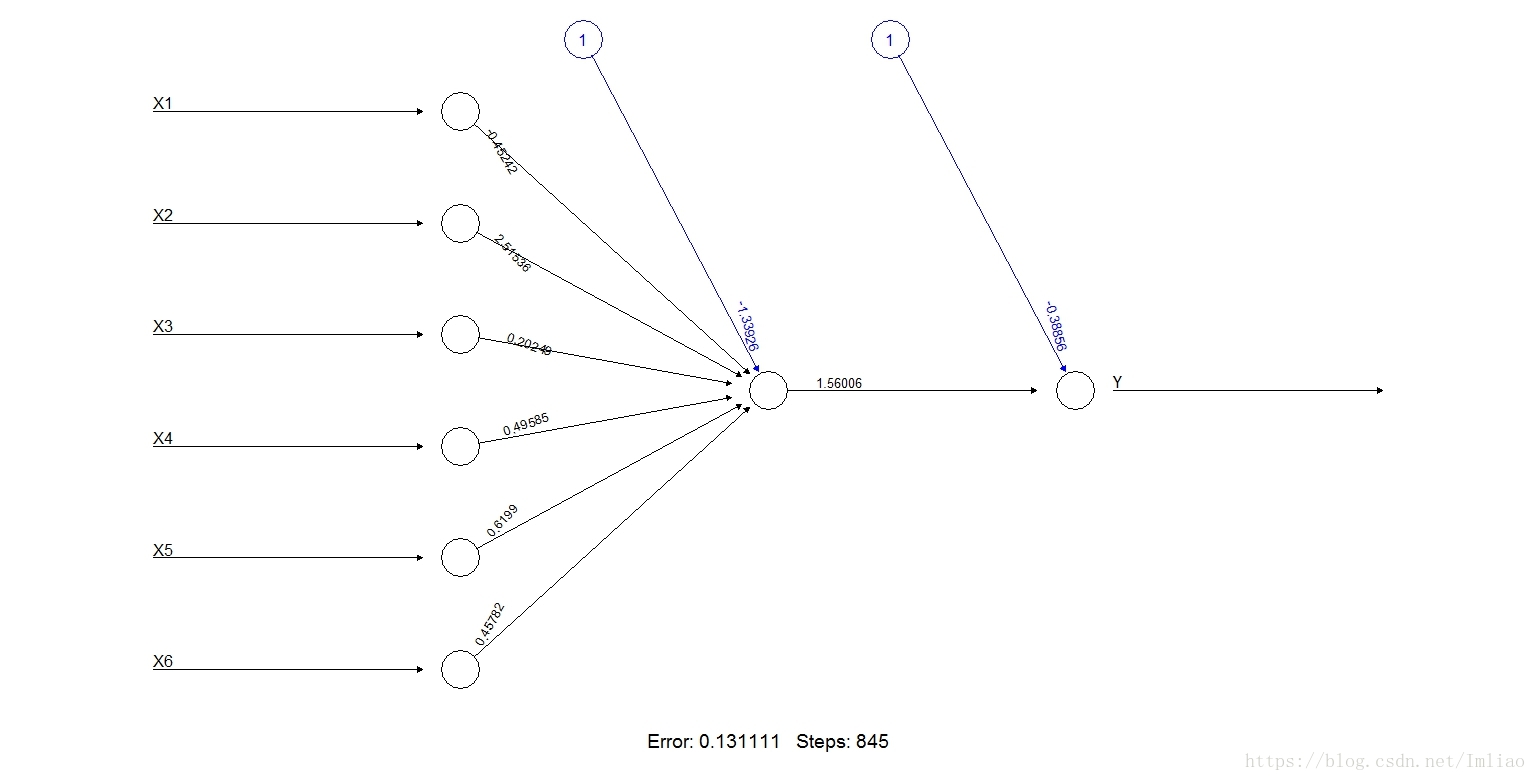
图中,圈中有1代表的是偏差项,从输入层到隐藏层的每个箭头上的数字表示的是权重,图下面的Error表示的误差平方和,可以用来评估模型优劣,step是训练的步数。
模型性能评估
这里使用相关系数来评估系统性能:
neuropredict<-compute(neuromodel,data_test[,-1])
neuroresult<-neuropredict$net.result
cor(neuroresult,data_test$Y)
> cor(neuroresult,data_test$Y)
[,1]
[1,] 0.9873125732可以看到,cor超过0.9,说明性能很出色。
by Yuhua20180531


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









