




最优失败的原因
在梯度下降的过程中,会找到局部最优点和鞍点。
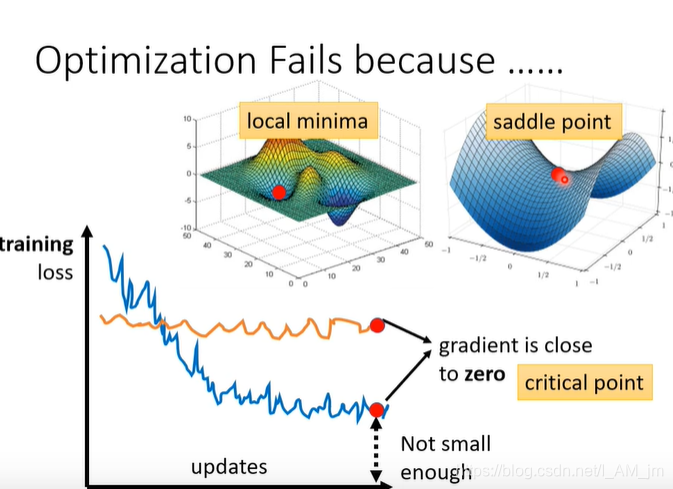
如果说是找到局部最优解,那么我们是无法再进行优化的,如果说是找到鞍点,那么我们还是可以解决的。那么我们怎么判断是局部点还是鞍点呢?
泰勒展开式

g是一阶导数,h是二阶导数,
我们根据泰勒展开式来判断是什么类型的错误,
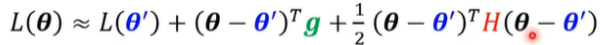
计算H,如果所有的H都是大于0,那么就是局部最优点
计算H,如果所有的H都是小于0,那么就是局部最优点
如果有正有负,那么就说明是鞍点

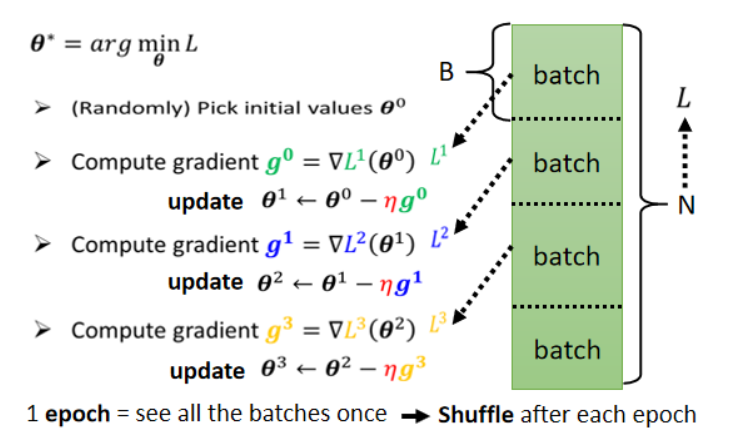
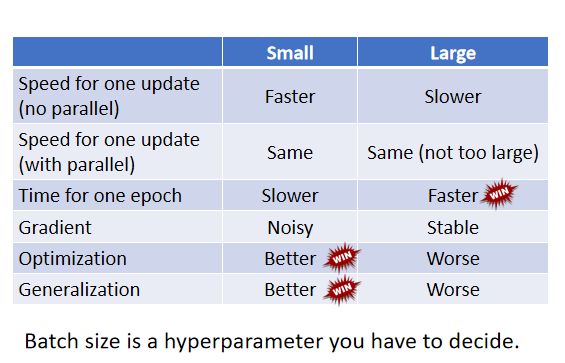
Batch训练技巧
将数据分批次,分批次计算loss,有点像分治算法。
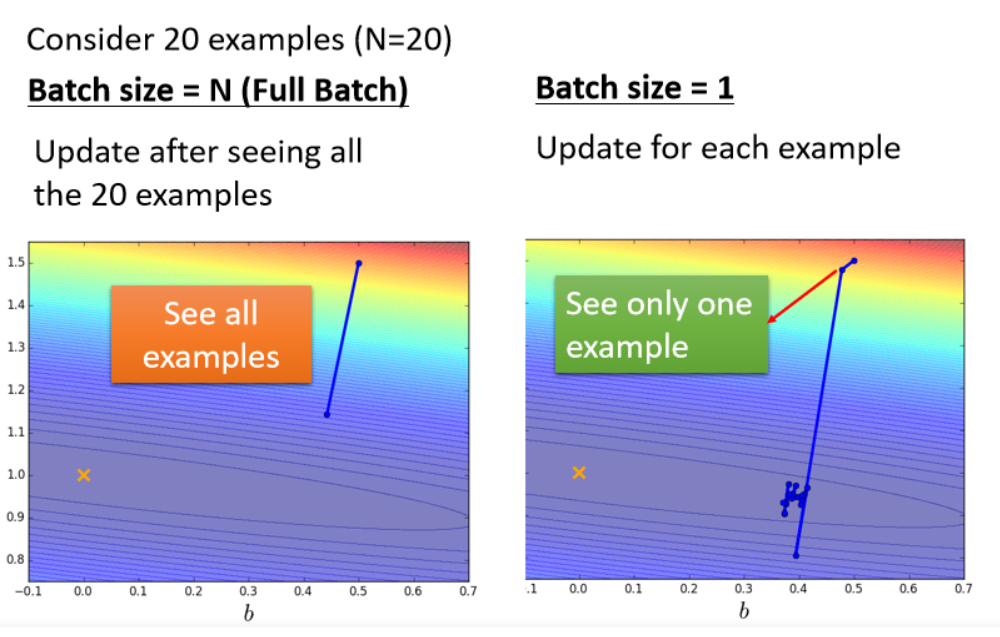
左边的蓄力时间长,但是威力比较大
右边很快,但是是乱枪打鸟
但是考虑并行运算的话,左边的不一定慢。
 gpu上进行并行运算,batch_size=1000的时候,计算的时间其实很短,
gpu上进行并行运算,batch_size=1000的时候,计算的时间其实很短,
但是如果再大的话,时间会再增加。
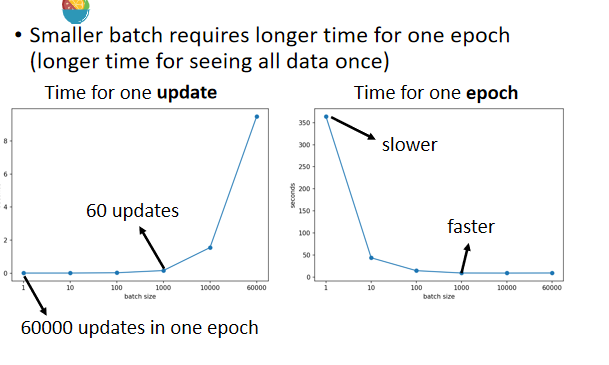
如果batch_size=1,如果有60000条数据,那么就会update60000次
如果batch_size=1000,那么只用updata60次

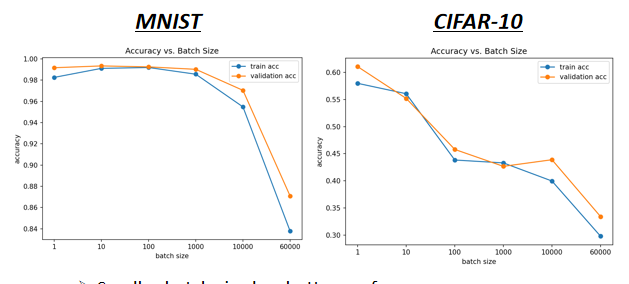
大的batch_size会带来比较差的结果。
小的batch_size会带来比较好的结果
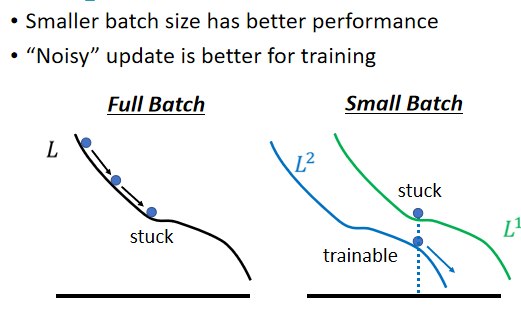
左边的是batch_size较大的,右边是batch_size较小的情况,
可以发现左边的容易被卡住,
但是右边的不容易被卡住

小的batch_size对test也有帮助。
这篇论文Train 了六个 Network 里面面有 CNN 的,有 Fully Connected Network 的,做在不同的 Cover 上,来代表这个实验是很广用的,在很多不同的 Case 都观察到一样的结果,可以看到小batch在test上比大batch的要好。
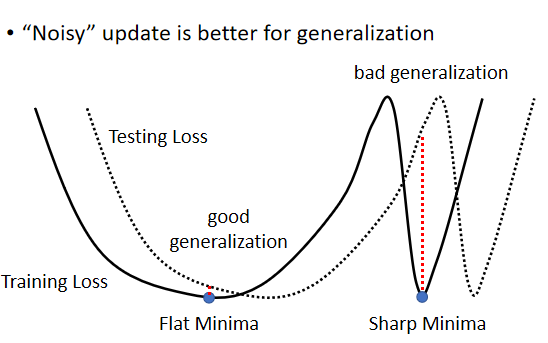
产生这样的原因是,训练集和测试集的不一样,导致结果不一样,可以看上面的那个图,大batch会走到图右边的峡谷里面,小的batch会走到左边那个点,那个点更接近于真实值。
可以看到,其实,也不是小的就一定好,各有各的优点。

那么我们是不是有方法进行兼顾呢?
以上论文都有解决方法。
Momentum
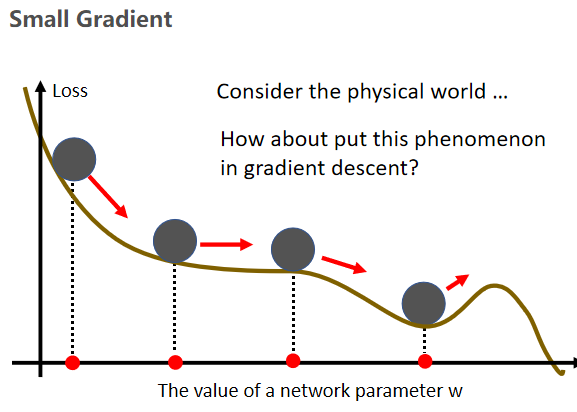
模拟物理世界,把损失曲线想成这个斜坡,模拟这个球,如果说它有惯性,那么它遇到局部最优点的时候,会凭借惯性跨过这个局部最优点或者鞍点
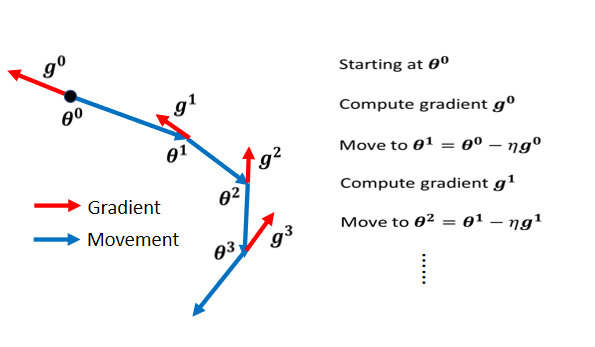
一般来说,我们原来更新梯度的时候,我们计算每个状态的微分,然后根据然后判断方向后,再更新梯度。
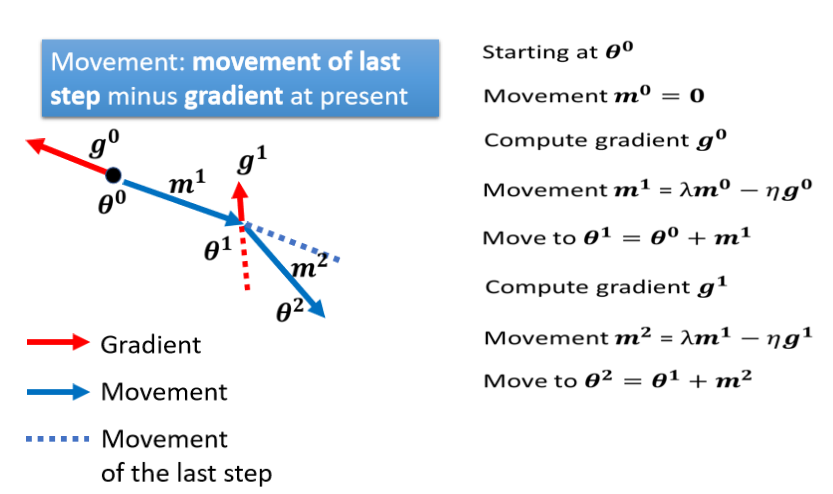
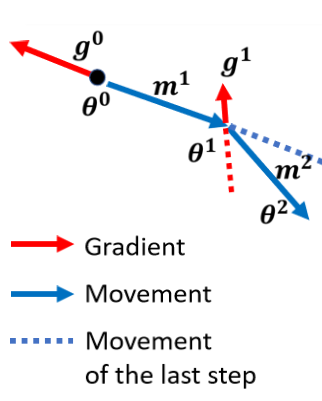
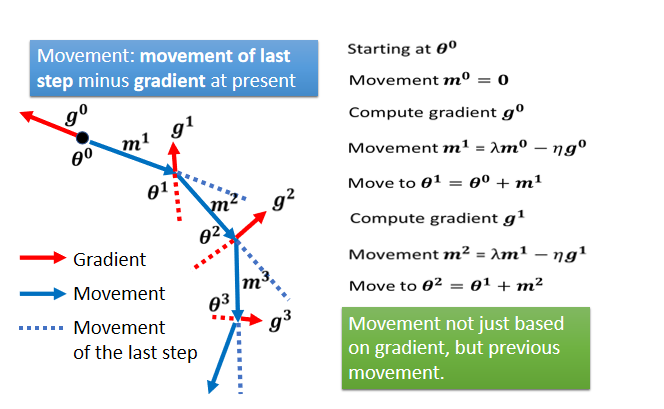
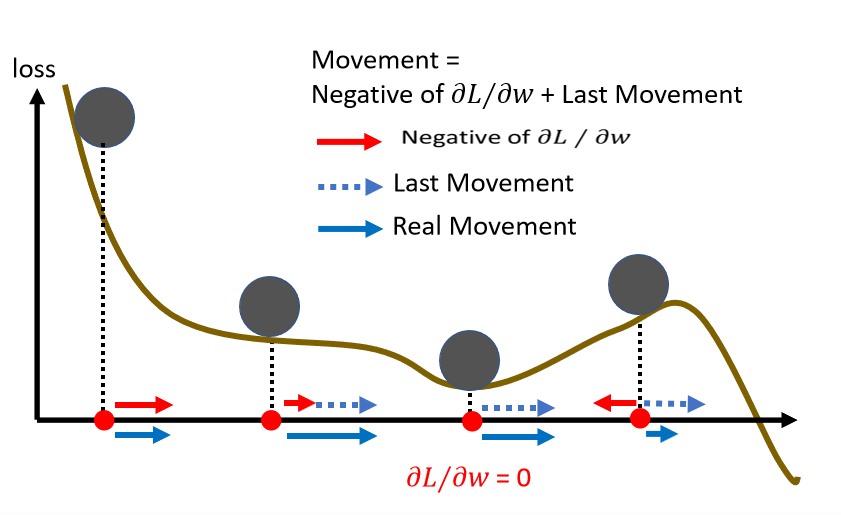
这一部分有点绕,先留个坑,后续再补。
自动调整学习率

临界点不一定是训练过程的阻碍,当loss无法减少的时候,梯度其实不一定为0,
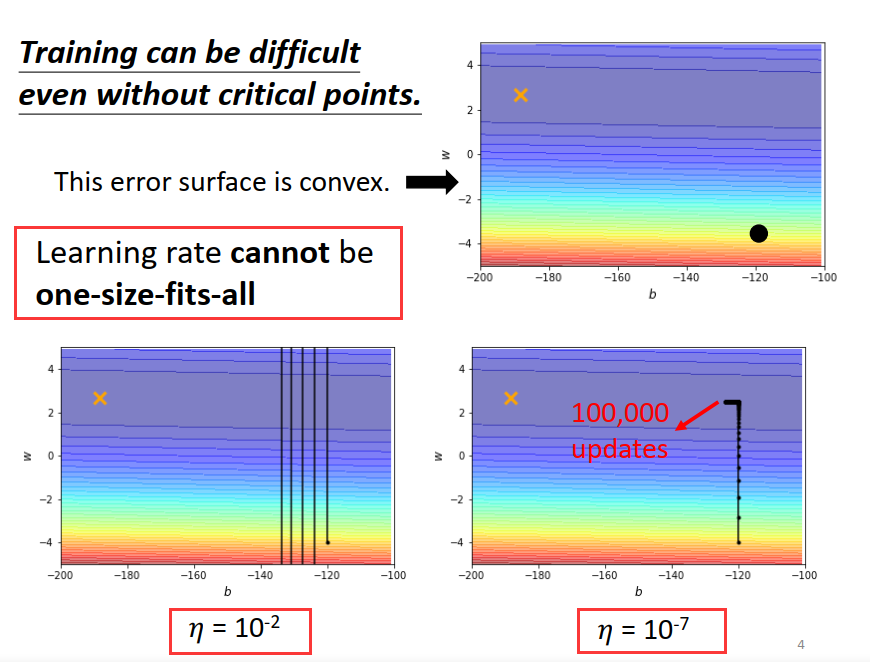
如果所有的参数都设同样的learning rate 会出现下面的情况:步幅过大,无法得到较小的loss步幅过小,无法逼近局部最优点。
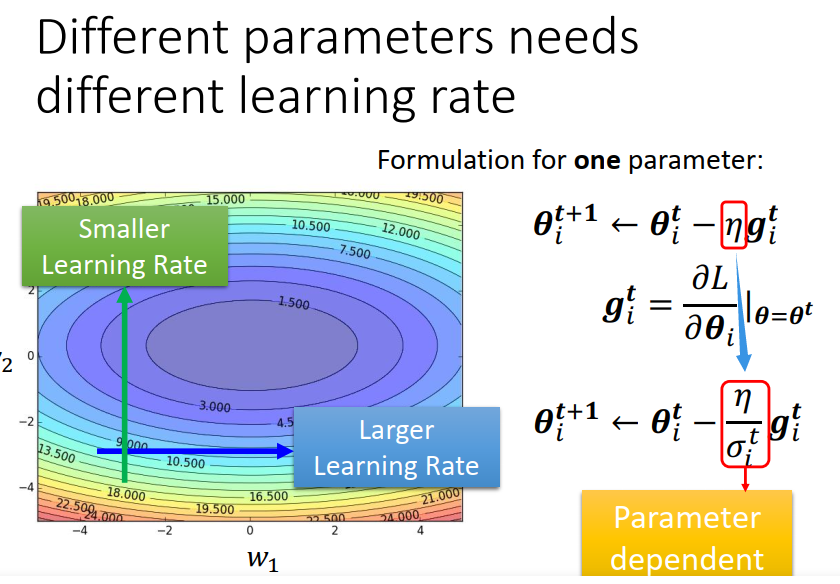
那么这样,我们怎么做好梯度下降呢?
我们可以为每个参数定制learning rate:如果某一方向上坡度很大,我们其实希望learning rate 可以小一点, 如果某一方向上坡度很小,我们可以让learning rate大一点
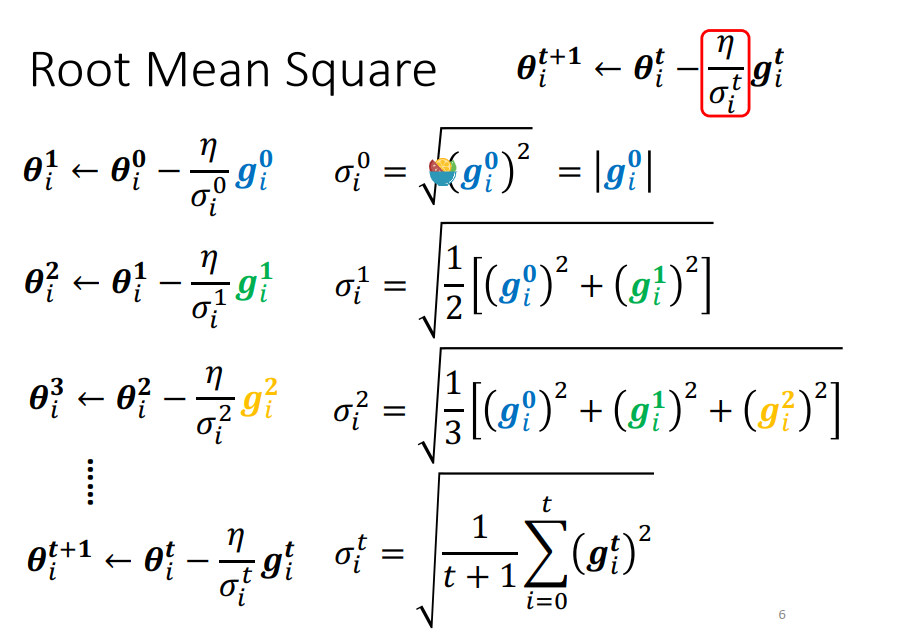
这个最优化方法叫adagrad
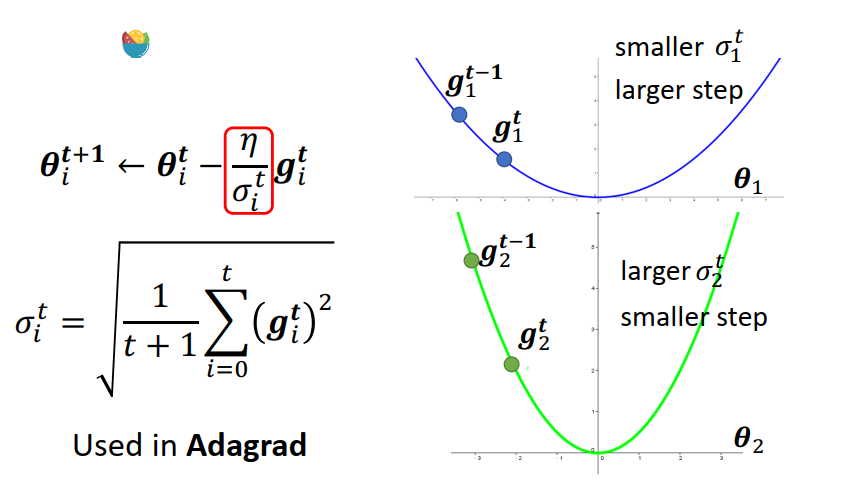
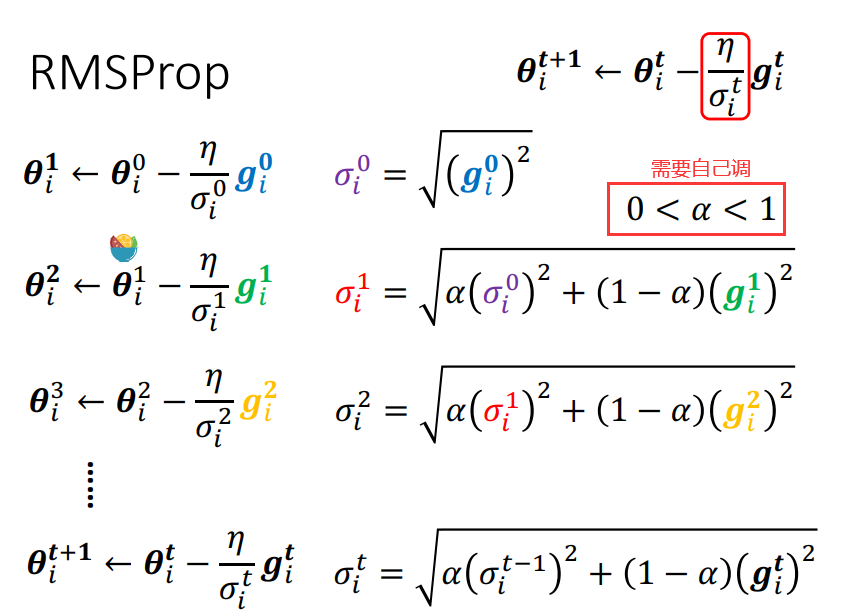
但是就算是同一个参数,他需要的learning rate 也会随着时间而改变
这个时候该怎么办呢?
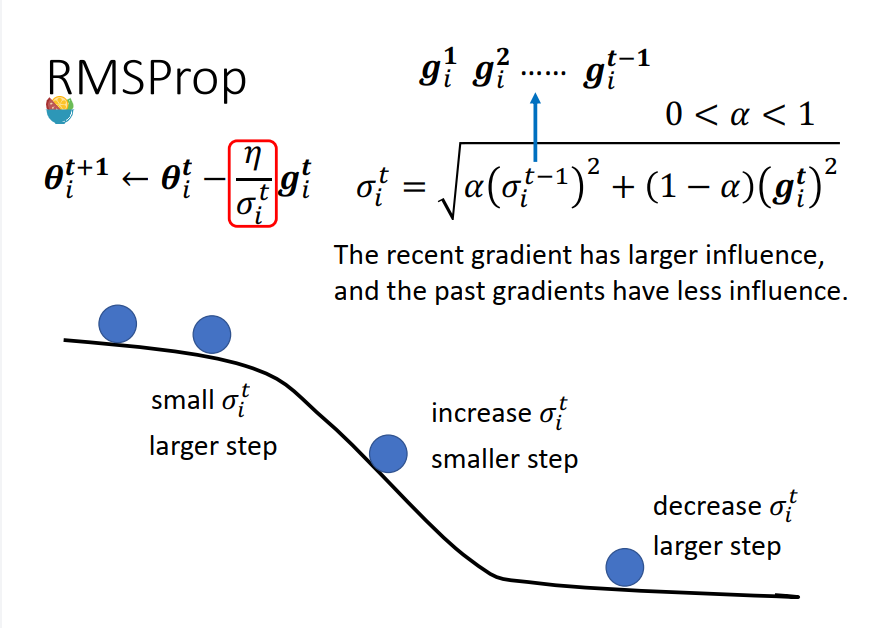
所以一个就有了一个新的招数:RMS Prop;
新增一个hyper parameter: α


损失函数也有影响
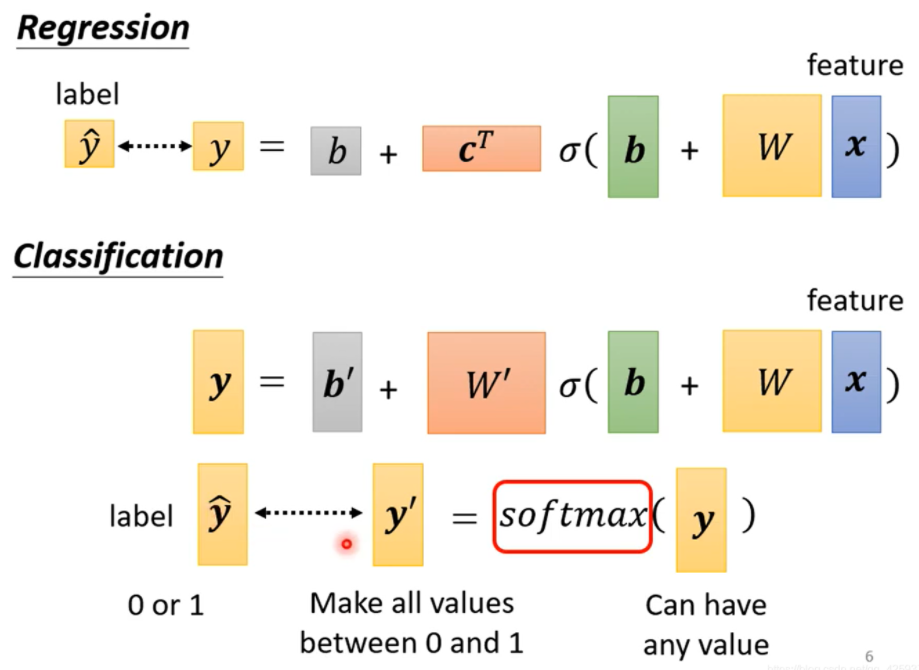
先谈分类,我们可以把分类转换成回归,但是这样是有点问题的。
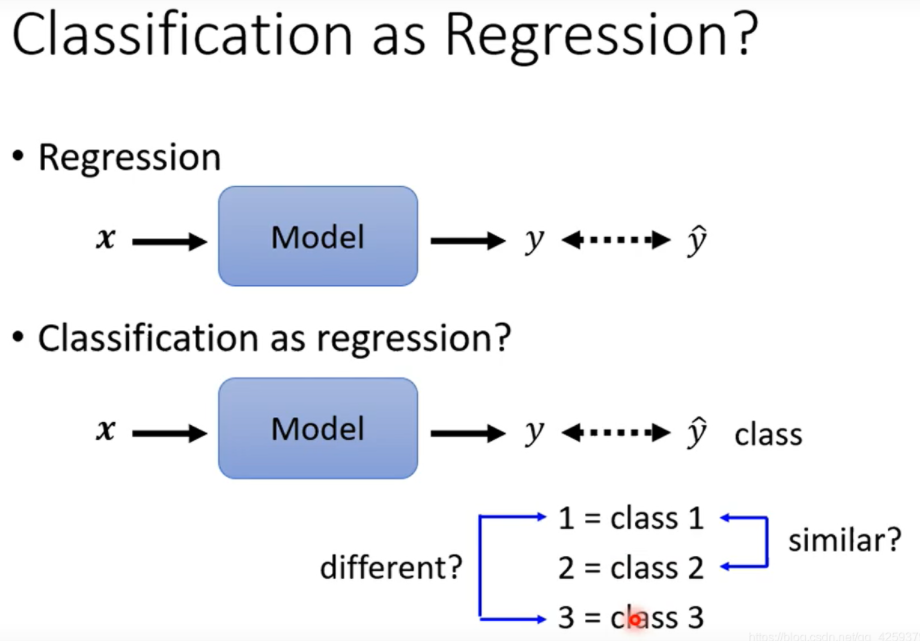
我们输出的通常是一个数值
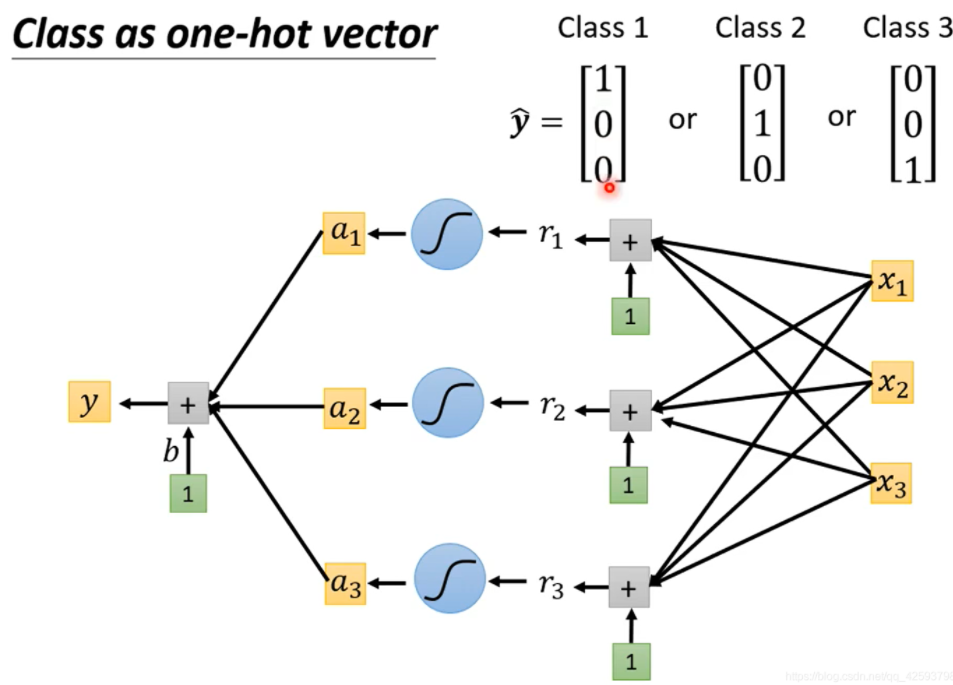
乘以不同的权重就可以输出不同的值。
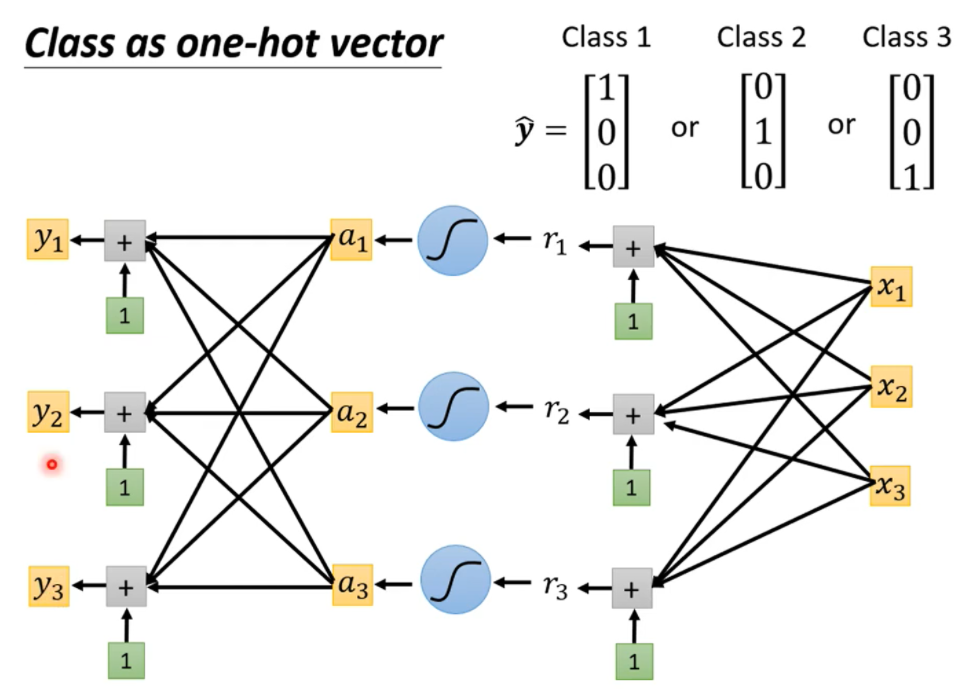
加入了softmax函数后就会输出一个答案
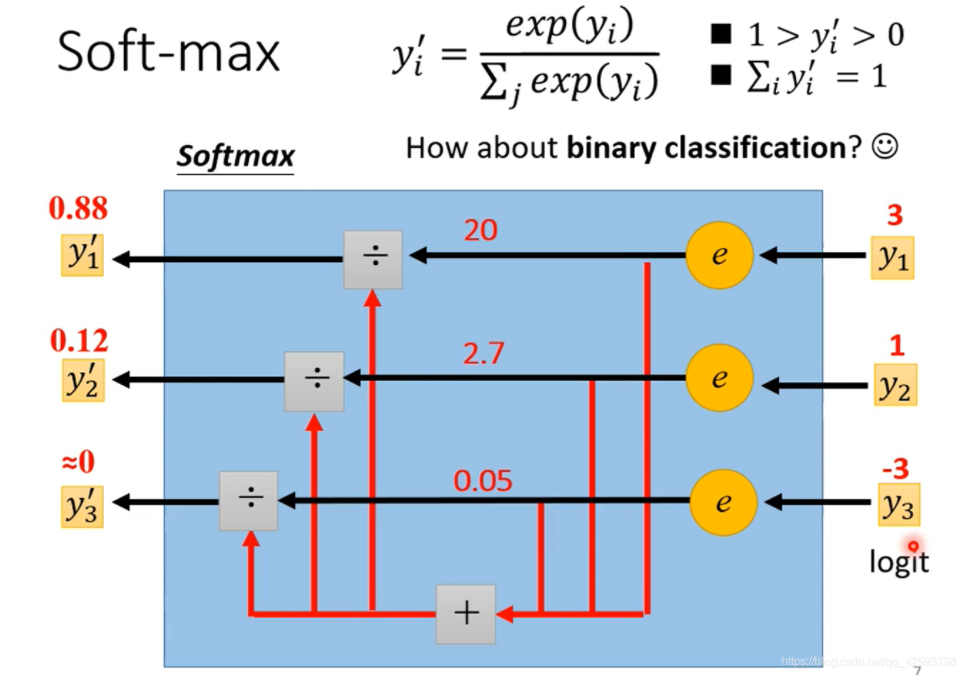
下图是softmax函数的运作方式
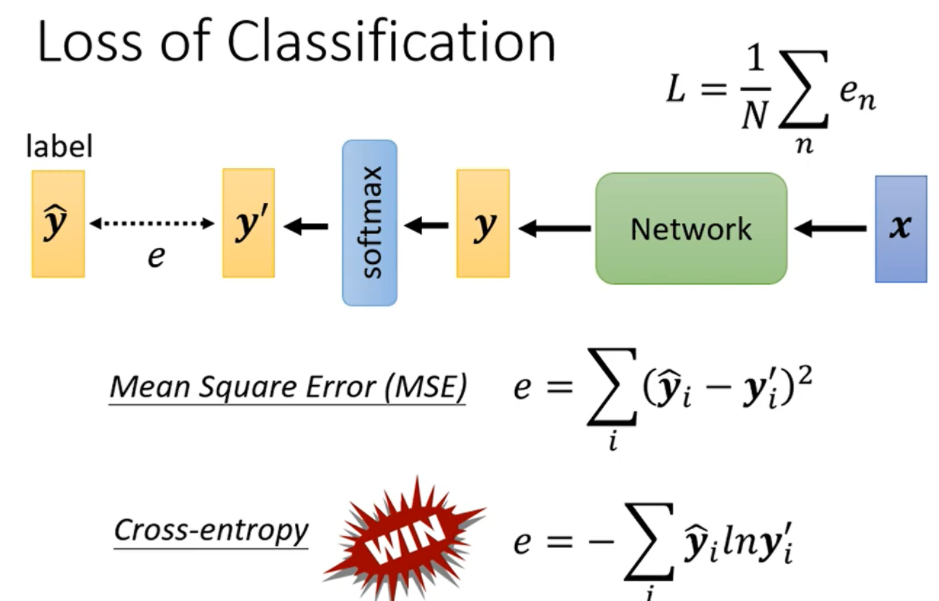
相应的损失函数变成如下形式
批次标准化
我们觉得说error surface 如果很崎岖的时候,它比较难train,就像爬山一样,那么我们能不能先把山铲平呢?
batch normalization就是其中一个把山铲平的想法。
或者可以换一种思路,将error surface 变换一下啊。
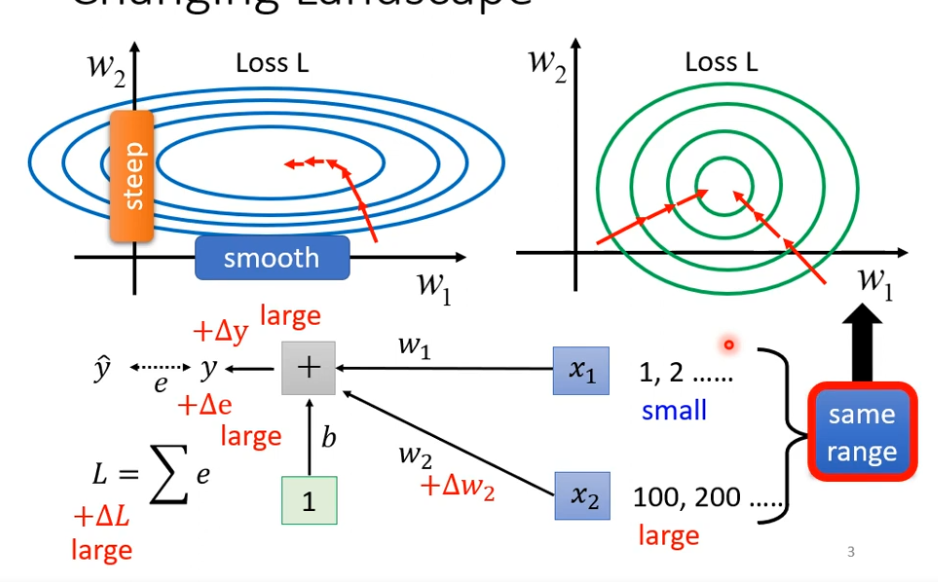
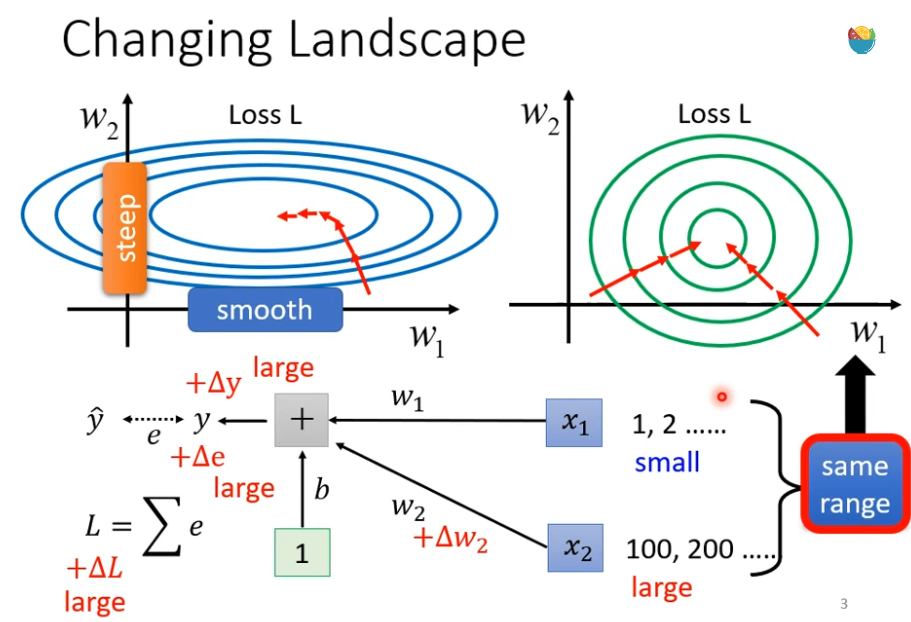
假设我们现在有一个非常简单的 linear model 没有activation function,输入是 x1 ,x2 对应的参数是w1,w2,那什么样的状况我们会产生上面这种比较不好train 的 error surface 呢?
如果 w1或 w2 有改变,y 就有改变,e 随着也有改变,进而 loss 也有改变
当你的 input 很小的时候 ,假设x1的值都很小,w1有一个变化的时候,它对y的影响也是小的,进而 loss 变化也是小的。
当你的 input 很大的时候 ,假设x2的值都很大,w2有一个变化的时候,它对y的影响也是大的,进而 loss 变化也是小的
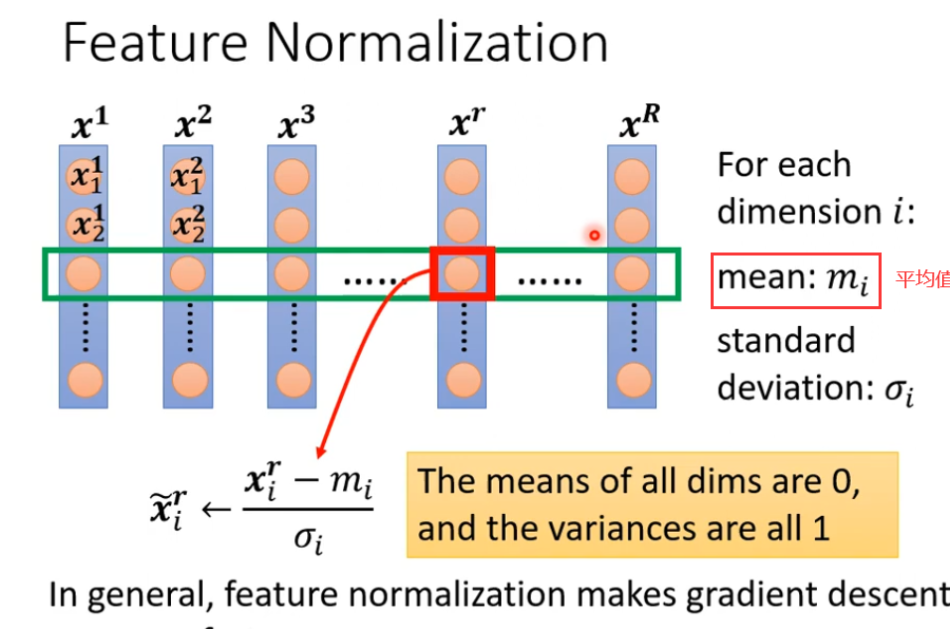
特征归一化,当每个特征都差距较大时,就可以将特征归一化,这样可以使得train更顺利
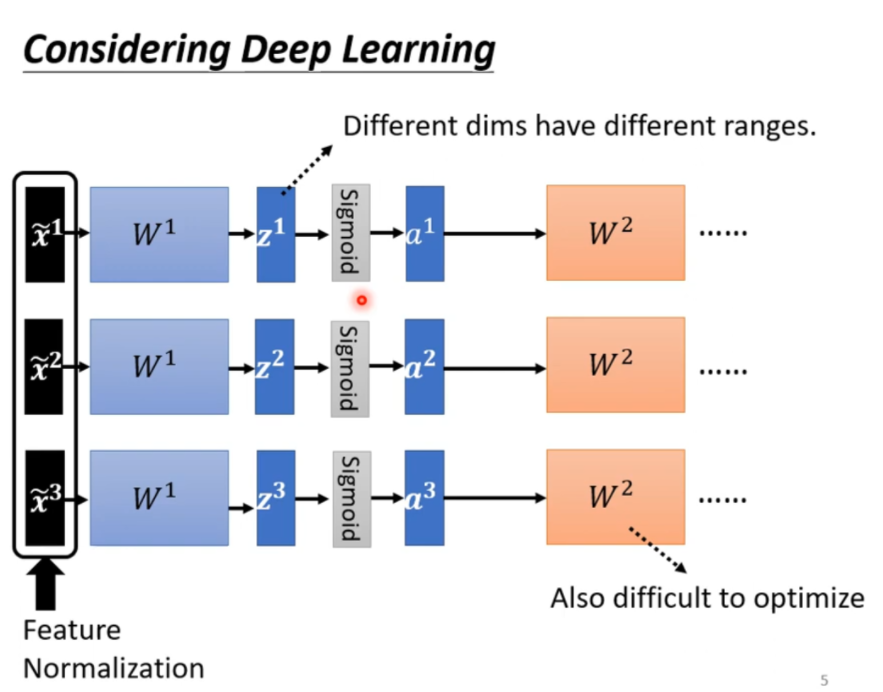
deep learning 也是可以做特征归一化的
对于特征归一化,我们可以选择在激活函数之前和激活函数之后进行。
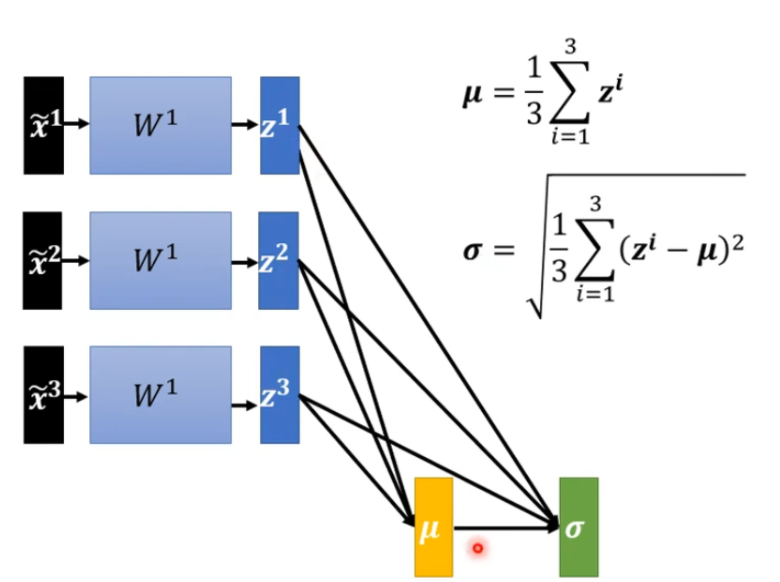
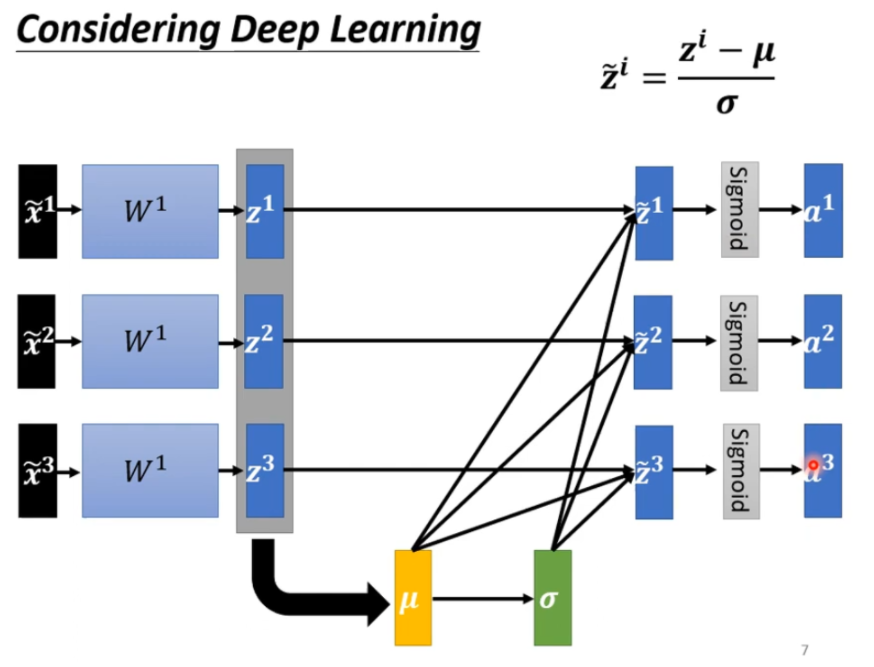
但是当数据很多的话,没有办法将数据全部丢到神经网络中
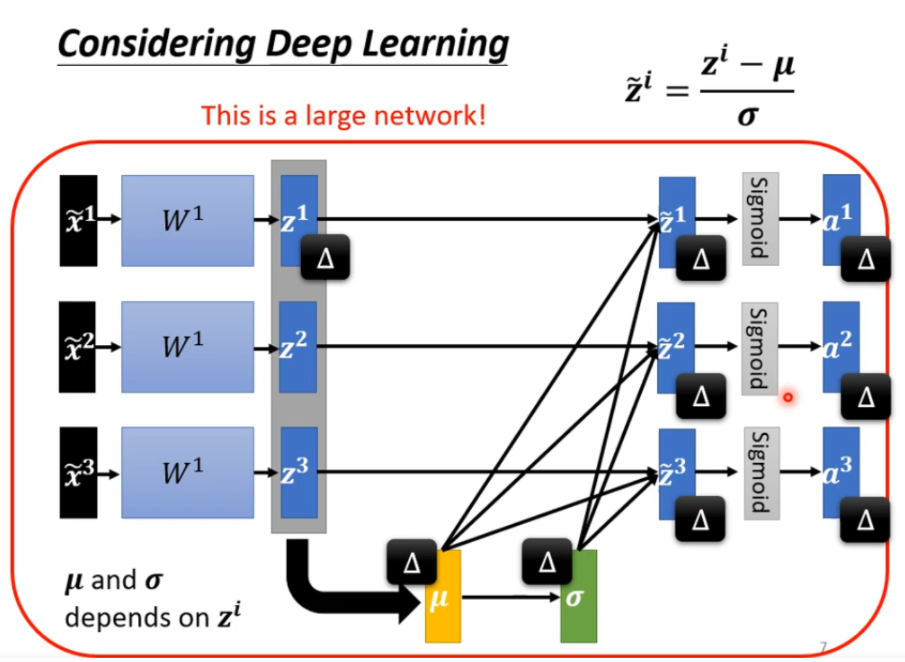
这个时候可以用分批次
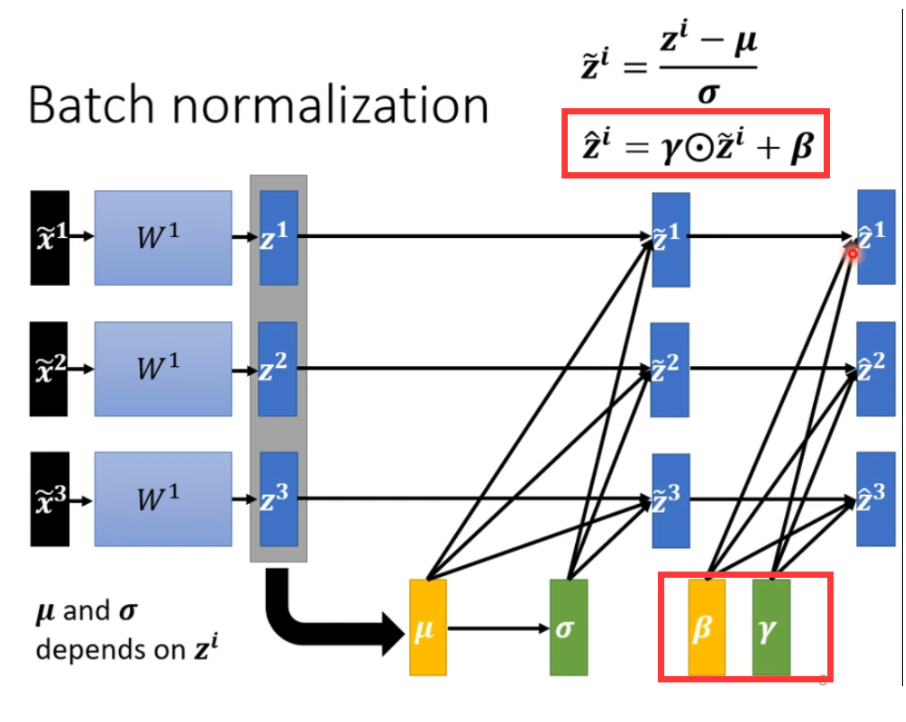
在实际训练过程中,我们在训练了一段时间后,在error surface 走到一个好的地方后,可把γ 和 β和加进去。
测试的时候
在测试的时候,如果batch设置的是64,我们不一定要等64笔资料都进来才做一次运算,这样是不行的。
我们可以用训练好的μ和 σ来代替 ,如下图
其中 p ,通常设为0.1


















 22万+
22万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









