




IT Xiao Ang Zai 2019年3月7号

版本:python3.7
编程软件:Pycharm,Sublime Text 3
作者说明:之前向大家介绍过有关网络爬虫的东西,但知识比较分散,内容不算多,却写了很多文章。现在看来,有必要重新进行网络爬虫的总结了,我还会在之后配合python其他的有关知识以及js等网页内容的讲解,python大佬好多都是js大佬,两者有很多相关的地方。本篇文章,是对之前文章的重新讲解,希望大家有任何宝贵的意见,都可以提出来。
一:网页简单模块urllib模块爬取网页源代码
1.网络爬虫:简单讲,网络爬虫(又称为网页蜘蛛),就是可以在互联网上爬来爬去,捕获我们所需要的资源,并存储起来配合其他地方使用。
2.urllib模块简介
(1)这个模块是URl和lib两个单词共同构成的:URL就是网页的地址,lib是library(库)的缩写。可以把这个模块理解为网页地址库。
(2)URL的一般格式为(带方括号[]的为可选项):protocol://hostname[port]/path/[;parameters][?query]#fragment。
(3)URL的组成部分:
a.协议部分(protocol):该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在"HTTP"后面的“//”为分隔符。
b.域名部分(hostname[port]):存放资源的服务器的域名系统(DNS)主机名(也可以使用IP地址作为域名使用)。
c.端口部分(post):跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口80。
d.虚拟目录部分(path):从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。
e.文件名部分[;parameters?]:从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名。
f.锚部分(fragment):从“#”开始到最后,都是锚部分。锚部分也不是一个URL必须的部分。
g.参数部分[query]:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分,不包括?。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。
(4)python3版本把以前版本的urllib2模块(对urllib的补充)等模块合并成为urllib,调用有时看到urllib2类似的代码,可以用urllib模块中的函数代替。
(5)其实urllib里面有很多模块,相当于一个包。
(6)我们代开python的参考文档可以看到:
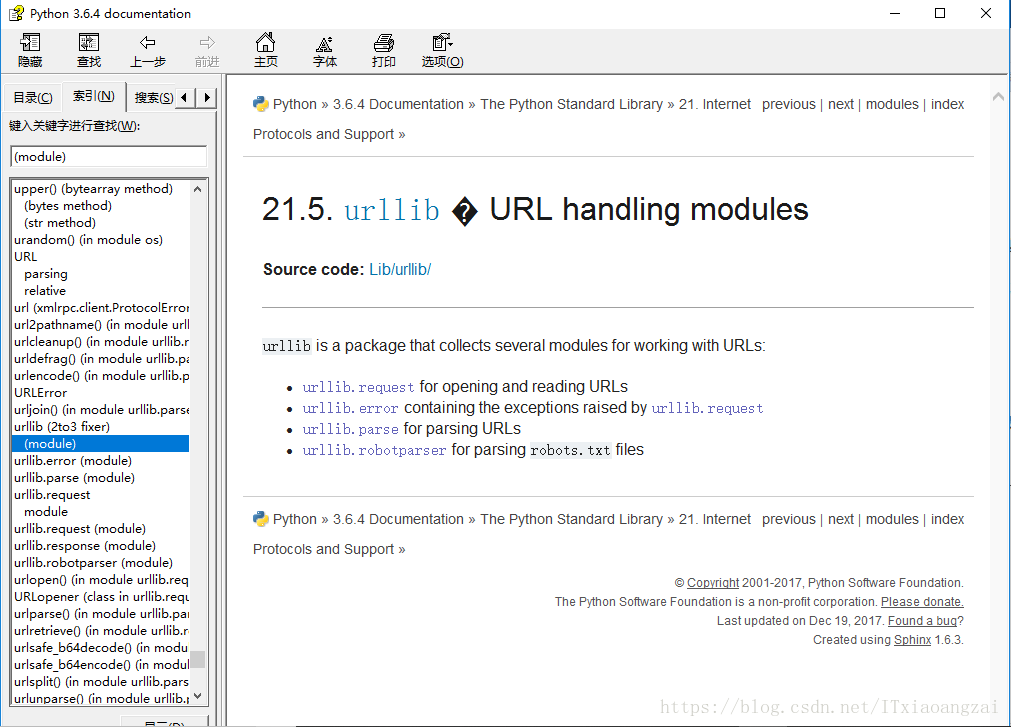
这里可以看到,urllib是一个包,里边总共有四个模块。一般第一个模块是最复杂与最重要的,它包含了对服务器请求的发出,跳转,代理和安全。
3.urllib模块爬取网页源码
我们先来爬取一下网页源码,用urllib.request.urlopen()函数就可以访问网页了:
import urllib.request
response = urllib.request.urlopen("https://baike.baidu.com/item/%E4%B8%8A%E5%8F%A4%E5%8D%B7%E8%BD%B45%EF%BC%9A%E5%A4%A9%E9%99%85/353892?fromtitle=%E4%B8%8A%E5%8F%A4%E5%8D%B7%E8%BD%B45&fromid=290703&fr=aladdin")
html = response.read()
print(html)效果如下:
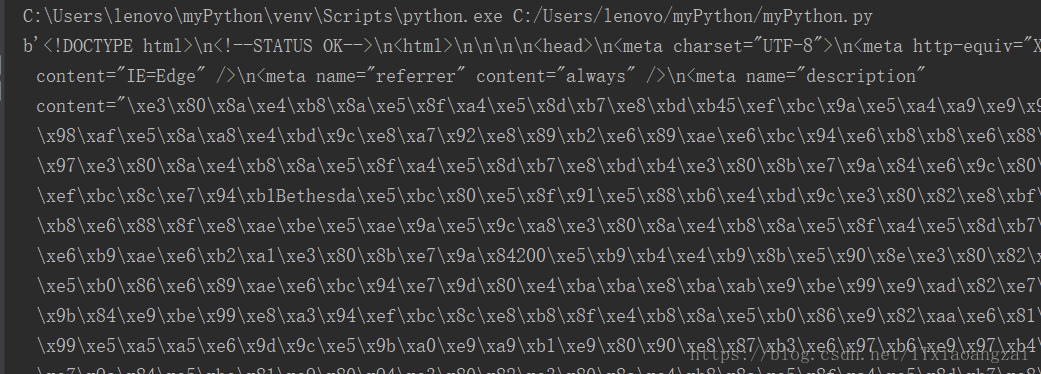
我们发现它并不是HTML代码,其实python爬取的内容是以utf-8编码的bytes对象,上面有个b,表示这是一个bytes对象,要还原为带中文的html代码,需要对其进行解码,将它变成Unicode编码:
html = html.decode("utf-8")
print(html)效果如下:
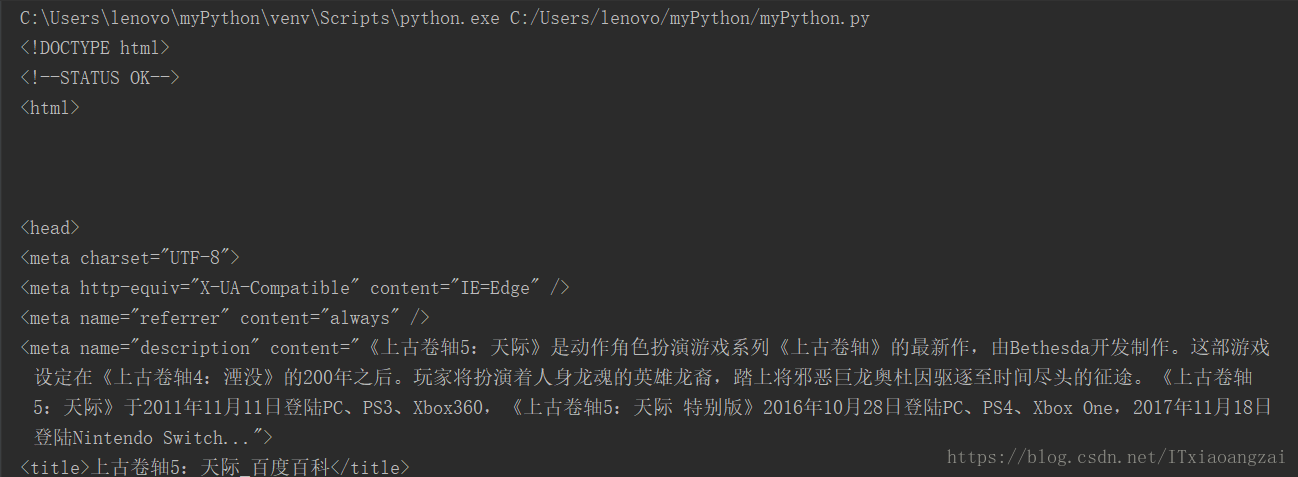
4.实例讲解
(1)下载一只猫
网站:http://placekitten.com/这个网站在后面附上宽度和高度,就可以得到一张对应的图片:
import urllib.request
response = urllib.request.urlopen("http://placekitten.com/408/287")
cat = response.read()
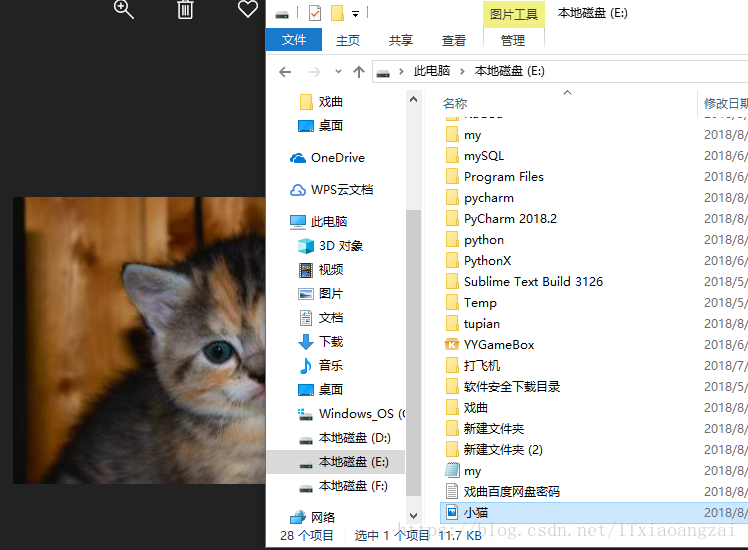
with open('E:\\小猫.jpg',"wb") as f:
f.write(cat)我们可以发现这张图片被下载下来了:
其实,urlopen()的参数既可以是一个字符串也可以是Request对象,先把传入的字符串转换为Request对象,然后再传给urlopen函数。因此代码也可以这样写:
req= urllib.request.Request("http://placekitten.com/408/287")
response = urllib.request.urlopen(req)然后,urlopen()实际上是返回的一个类文件对象,可以用read()读取内容。
(2)文档告诉我们以下三个函数可能以后会用到:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











