




 本文详细介绍了在使用Structured Streaming读取Kafka数据时的配置要点,包括必需参数、Kafka特定配置以及不能设置的参数。强调了group.id由查询自动创建,offsets由Structured Streaming内部管理。同时讨论了如何修改offsets以及checkpointLocation中的文件结构,提供了在不丢失数据的情况下管理offset的方法。
本文详细介绍了在使用Structured Streaming读取Kafka数据时的配置要点,包括必需参数、Kafka特定配置以及不能设置的参数。强调了group.id由查询自动创建,offsets由Structured Streaming内部管理。同时讨论了如何修改offsets以及checkpointLocation中的文件结构,提供了在不丢失数据的情况下管理offset的方法。
读取Kafka数据的时候,KafkaSourceProvider 类中的createMicroBatchReader 函数体中有对option() 中设置的Kafka参数进行校验及设置默认参数:

必填参数:duisubscribe,startingOffsets,failOnDataLoss进行判断。
如果要对默认参数进行修改或者添加新的配置,通过 option("Kafka.xx","") 进行设置。由于在KafkaSourceProvider 类对Kafka设置的参数做了过滤处理 因此,设置Kafka参数时,必须以kafka. 前缀开始:

切记!不是所有的Kafka参数都可以设置!
Kafka特定配置
Kafka自己的配置可以通过设置DataStreamReader.option与kafka.前缀,例如 stream.option("kafka.bootstrap.servers", "host:port")。有关可能的kafka参数,请参阅 Kafka使用者配置文档以获取与读取数据相关的参数,以及Kafka生产者配置文档 以获取与写入数据相关的参数。
请注意,无法设置以下Kafka参数,并且Kafka源或接收器将引发异常:
group.id:Kafka源将自动为每个查询创建一个唯一的组ID。
auto.offset.reset:设置源选项startingOffsets以指定从何处开始。结构化流管理在内部管理哪些偏移量,而不是依靠 kafka使用者来执行此操作。这将确保在动态订阅新主题/分区时不会丢失任何数据。请注 意,startingOffsets仅在启动新的流查询时适用,并且恢复将始终从查询中断的地方开始。
key.deserializer:始终使用ByteArrayDeserializer将键反序列化为字节数组。使用DataFrame操作显式反序列化键。
value.deserializer:始终使用ByteArrayDeserializer将值反序列化为字节数组。使用DataFrame操作显式反序列化值。
key.serializer:密钥始终使用ByteArraySerializer或StringSerializer进行序列化。使用DataFrame操作可以将键显式序 列化为字符串或字节数组。
value.serializer:值始终使用ByteArraySerializer或StringSerializer进行序列化。使用DataFrame操作可以将值显式序 列化为字符串或字节数组。
enable.auto.commit:Kafka源不提交任何偏移量。
Interceptor.classes:Kafka源始终将键和值读取为字节数组。使用ConsumerInterceptor是不安全的,因为它可能会 中断查询。
source相关的配置
无论是流的形式,还是批的形式,都需要一些必要的参数:
kafka.bootstrap.servers kafka的服务器配置,host:post形式,用逗号进行分割,如host1:9000,host2:9000
assign,以json的形式指定topic信息
subscribe,通过逗号分隔,指定topic信息
subscribePattern,通过java的正则指定多个topic
assign、subscribe、subscribePattern同时之中能使用一个。
其他比较重要的参数有:
startingOffsets, offset开始的值,如果是earliest,则从最早的数据开始读;如果是latest,则从最新的数据开始读。默认流是latest,批是earliest
endingOffsets,最大的offset,只在批处理的时候设置,如果是latest则为最新的数据
failOnDataLoss,在流处理时,当数据丢失时(比如topic被删除了,offset在指定的范围之外),查询是否报错,默认为true。这个功能可以当做是一种告警机制,如果对丢失数据不感兴趣,可以设置为false。在批处理时,这个值总是为true。
kafkaConsumer.pollTimeoutMs,excutor连接kafka的超时时间,默认是512ms
fetchOffset.numRetries,获取kafka的offset信息时,尝试的次数;默认是3次
fetchOffset.retryIntervalMs,尝试重新读取kafka offset信息时等待的时间,默认是10ms
maxOffsetsPerTrigger,trigger暂时不会用,不太明白什么意思。Rate limit on maximum number of offsets processed per trigger interval. The specified total number of offsets will be proportionally split across topicPartitions of different volume.
写入数据到Kafka
Apache kafka仅支持“至少一次”的语义,因此,无论是流处理还是批处理,数据都有可能重复。比如,当出现失败的时候,structured streaming会尝试重试,但是不会确定broker那端是否已经处理以及持久化该数据。但是如果query成功,那么可以断定的是,数据至少写入了一次。比较常见的做法是,在后续处理kafka数据时,再进行额外的去重,关于这点,其实structured streaming有专门的解决方案。
保存数据时的schema:
key,可选。如果没有填,那么key会当做null,kafka针对null会有专门的处理(待查)。
value,必须有
topic,可选。(如果配置option里面有topic会覆盖这个字段)
下面是sink输出必须要有的参数:
kafka.bootstrap.servers,kafka的集群地址,host:port格式用逗号分隔。
kafka的特殊配置
针对Kafka的特殊处理,可以通过DataStreamReader.option进行设置。
关于(详细的kafka配置可以参考consumer的官方文档](http://kafka.apache.org/documentation.html#newconsumerconfigs)
以及kafka producer的配置
注意下面的参数是不能被设置的,否则kafka会抛出异常:
group.id kafka的source会在每次query的时候自定创建唯一的group id
auto.offset.reset 为了避免每次手动设置startingoffsets的值,structured streaming在内部消费时会自动管理offset。这样就能保证订阅动态的topic时不会丢失数据。startingOffsets在流处理时,只会作用于第一次启动时,之后的处理都会自定的读取保存的offset。
key.deserializer,value.deserializer,key.serializer,value.serializer 序列化与反序列化,都是ByteArraySerializer
enable.auto.commit kafka的source不会提交任何的offset
interceptor.classes 由于kafka source读取数据都是二进制的数组,因此不能使用任何拦截器进行处理。
具体参数官网说明:
http://spark.apache.org/docs/2.3.0/structured-streaming-kafka-integration.html
源码介绍:
org.apache.spark.sql.kafka010.KafkaSourceProvider
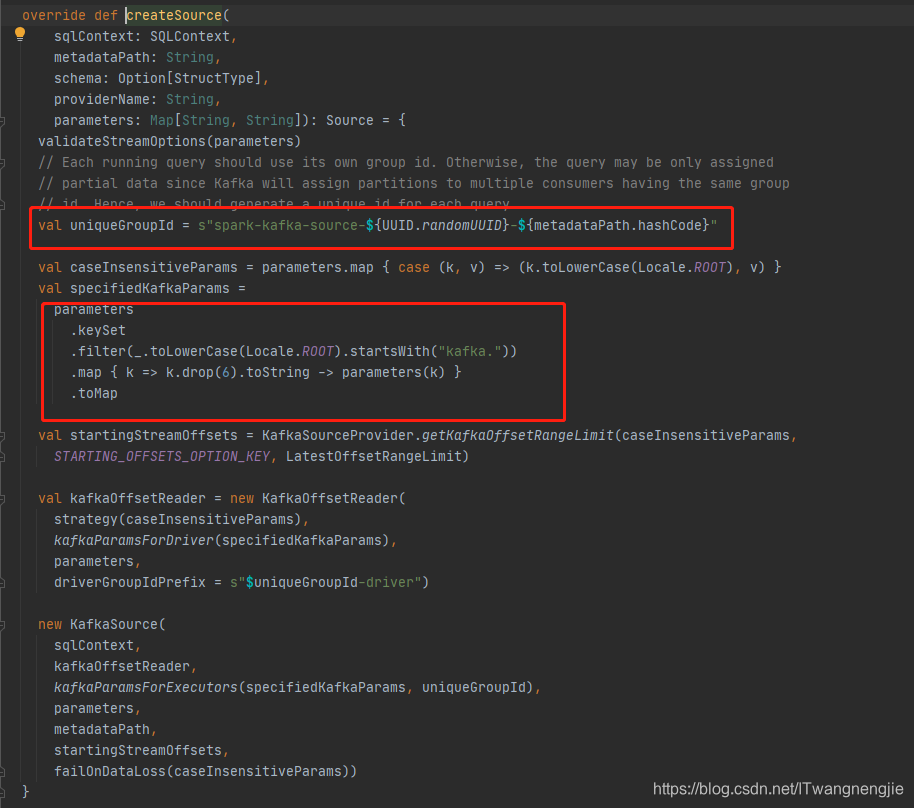
StructuredStreamingKafka的group.id问题:
看上面的源码我们知道:

而且,配置参数里已经不再支持group.id参数了。那offset怎么管理呢?
![]()
所有的Structured Streaming的offset在checkpointLocation管理了,这与传统的spark streaming不同。
我们来看看checkpointLocation的文件结构:

进入offsets:
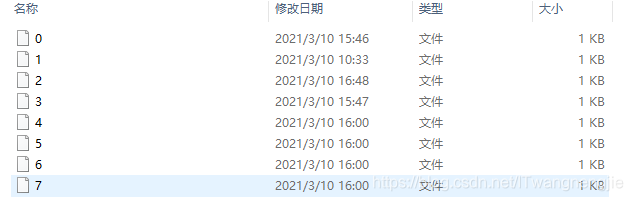
这里为每个每个已经消费过的,产生的batch的offsets位置:

完整信息如下:
v1
{"batchWatermarkMs":0,"batchTimestampMs":1615363236001,"conf":{"spark.sql.shuffle.partitions":"200","spark.sql.streaming.stateStore.providerClass":"org.apache.spark.sql.execution.streaming.state.HDFSBackedStateStoreProvider"}}
{"admin-test":{"2":10,"1":11,"3":16,"0":16}}
当你想修改当前消费的offset时,删除某个已经消费过的文件,比如:删除文件“7”
或者修改文件“7”里面的当前topic的offset
比如:
将{"admin-test":{"2":10,"1":11,"3":16,"0":16}}修改为:{"admin-test":{"2":9,"1":10,"3":15,"0":15}}
那么我们下次启动程序时,会从{"admin-test":{"2":9,"1":10,"3":15,"0":15}}这个offset开始消费。

















 1402
1402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









