




 本文介绍如何通过Selenium进行浏览器的高级配置,包括加载用户配置文件、设置编码、添加请求头等,以应对复杂的自动化测试需求。
本文介绍如何通过Selenium进行浏览器的高级配置,包括加载用户配置文件、设置编码、添加请求头等,以应对复杂的自动化测试需求。
目录
前言
做自动化测试过程中,有时需要绕过验证码或如下场景中都可以使用该模块
- 禁止图片和视频的加载:提升网页加载速度。
- 使用请求头:访问移动端的站点,一般这种站点的反爬技术比较薄弱。
- 添加扩展:像正常使用浏览器一样的功能。
- 设置编码:应对中文站,防止乱码。
- 添加代理:用于翻墙访问某些页面,或者应对IP访问频率限制的反爬技术。
加载用户配置文件
说明:此方法加载用户的配置文件,可绕过已登录的网站的登录页面
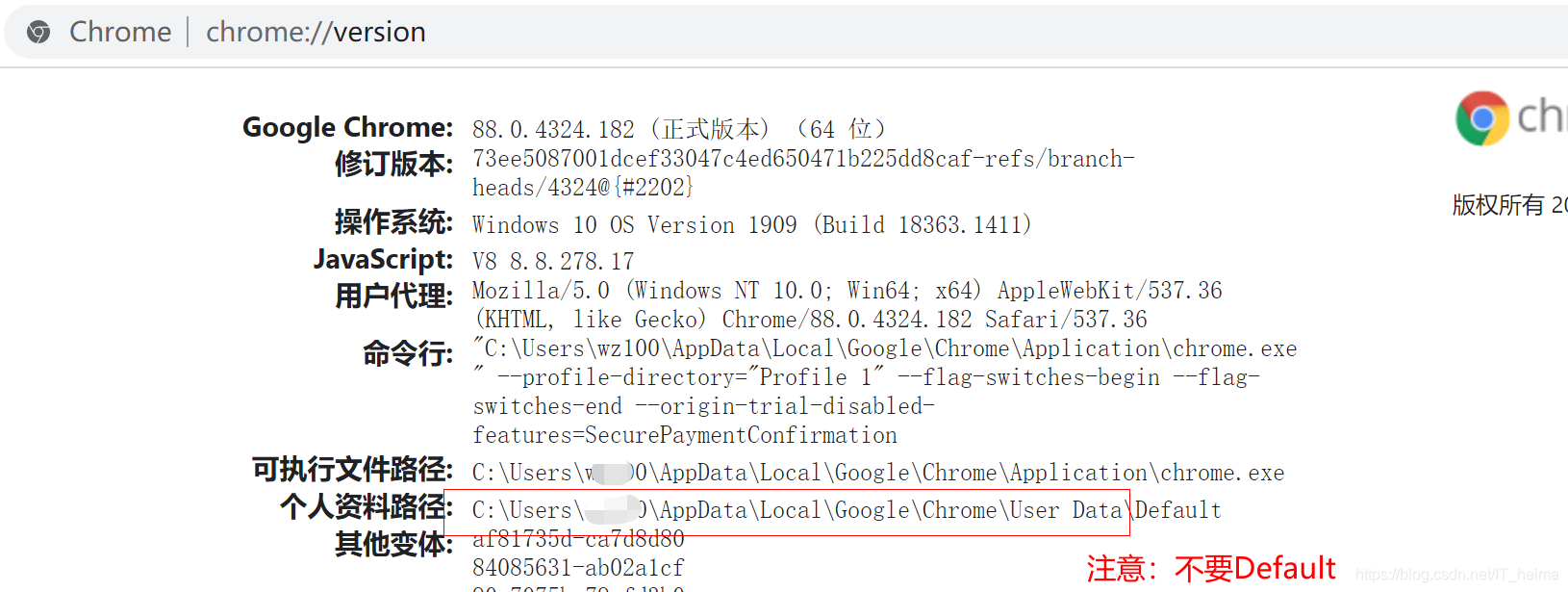
- 在Chrome地址栏输入chrome://version/,查看自己的“个人资料路径
- 注意:1)路径到User Data ,不要后面的Default 2)关闭所有的Chrome进程(必须关闭在运行的浏览器)
# -*- coding: utf-8 -*-
# @Time : 2021/3/4
# @Author : 大海
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
# 设置成用户自己的数据目录
options.add_argument(r'--user-data-dir=C:\Users\<user>\AppData\Local\Google\Chrome\User Data')
url = 'https://blog.youkuaiyun.com/IT_heima'
driver = webdriver.Chrome(options=options)
driver.get(url)
time.sleep(5)
driver.quit()设置编码
# -*- coding: utf-8 -*-
# @Time : 2021/3/4
# @Author : 大海
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
# 设置中文编码格式
options.add_argument('lang=zh_CN.UTF-8')
driver = webdriver.Chrome(options=options)
driver.get('https://blog.youkuaiyun.com/IT_heima')
time.sleep(5)
driver.quit()添加请求头
# -*- coding: utf-8 -*-
# @Time : 2021/3/4
# @Author : 大海
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
# 浏览器
options.add_argument(
'user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"')
driver = webdriver.Chrome(options=options)
driver.get('https://blog.youkuaiyun.com/IT_heima')
time.sleep(5)
driver.quit()禁止加载图片
# -*- coding: utf-8 -*-
# @Time : 2021/3/4
# @Author : 大海
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
# 禁止加载图片
options.add_argument('blink-settings=imagesEnabled=false')
driver = webdriver.Chrome(options=options)
driver.get('https://blog.youkuaiyun.com/IT_heima')
time.sleep(5)
driver.quit()无界面运行
# -*- coding: utf-8 -*-
# @Time : 2021/3/4
# @Author : 大海
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
# 浏览器不提供可视化页面运行
options.add_argument('--headless')
url = 'https://blog.youkuaiyun.com/IT_heima'
driver = webdriver.Chrome(options=options)
driver.get(url)
# 打印title,来确定是否运行
print(driver.title)
driver.quit()设置开发者模式启动
# -*- coding: utf-8 -*-
# @Time : 2021/3/4
# @Author : 大海
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
# 设置开发者模式,一般反爬比较好的网址都会根据这个反爬
options.add_experimental_option('excludeSwitches', ['enable-automation'])
url = 'https://blog.youkuaiyun.com/IT_heima'
driver = webdriver.Chrome(options=options)
driver.get(url)
time.sleep(5)
driver.quit()禁用浏览器弹窗
# -*- coding: utf-8 -*-
# @Time : 2021/3/4
# @Author : 大海
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
# 禁用浏览器弹窗
prefs = {
'profile.default_content_setting_values': {
'notifications': 2
}}
options.add_experimental_option('prefs', prefs)
url = 'https://blog.youkuaiyun.com/IT_heima'
driver = webdriver.Chrome(options=options)
driver.get(url)
time.sleep(5)
driver.quit()禁用JavaScript
# -*- coding: utf-8 -*-
# @Time : 2021/3/4
# @Author : 大海
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
# 禁用JavaScript
options.add_argument("--disable-javascript")
url = 'https://blog.youkuaiyun.com/IT_heima'
driver = webdriver.Chrome(options=options)
driver.get(url)
time.sleep(5)
driver.quit()隐藏滚动条
# -*- coding: utf-8 -*-
# @Time : 2021/3/4
# @Author : 大海
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
# 隐藏滚动条
options.add_argument('--hide-scrollbars')
url = 'https://blog.youkuaiyun.com/IT_heima'
driver = webdriver.Chrome(options=options)
driver.get(url)
time.sleep(5)
driver.quit()
# option.add_argument(r'--user-data-dir=C:\Users\wz100\AppData\Local\Google\Chrome\User Data') # 设置成用户自己的数据目录
# driver = webdriver.Chrome(options=options)
# url = 'https://pan.baidu.com/disk/home?fr=ibaidu#/all?path=%2F&vmode=list'
以最高权限运行
# -*- coding: utf-8 -*-
# @Time : 2021/3/4
# @Author : 大海
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
# 以最高权限运行
options.add_argument('--no-sandbox')
url = 'https://blog.youkuaiyun.com/IT_heima'
driver = webdriver.Chrome(options=options)
driver.get(url)
time.sleep(5)
driver.quit()添加插件
# -*- coding: utf-8 -*-
# @Time : 2021/3/4
# @Author : 大海
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
# 添加插件
extension_path = '你想要加载的插件路径'
options.add_extension(extension_path)
url = 'https://blog.youkuaiyun.com/IT_heima'
driver = webdriver.Chrome(options=options)
driver.get(url)
time.sleep(5)
driver.quit()添加代理
# -*- coding: utf-8 -*-
# @Time : 2021/3/4
# @Author : 大海
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
PROXY = "proxy_host:proxy:port"
options = Options()
desired_capabilities = options.to_capabilities()
desired_capabilities['proxy'] = {
"httpProxy": PROXY,
"ftpProxy": PROXY,
"sslProxy": PROXY,
"noProxy": None,
"proxyType": "MANUAL",
"class": "org.openqa.selenium.Proxy",
"autodetect": False
}
driver = webdriver.Chrome(desired_capabilities = desired_capabilities)
debug模式
- 启动浏览器dbug模式时,需要把其他的已打开浏览器的进程先全部关闭
- 9222是默认端口,可以随意修改。但别使用已经被占用的端口
# -*- coding: utf-8 -*-
# @Time : 2021/3/6
# @Author : 大海
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# 前面打开的浏览器,手动打开百度首页
# 下面的代码是在搜索框输入内容
options = Options()
options.debugger_address = "127.0.0.1:9222"
driver = webdriver.Chrome(options=options)
driver.find_element_by_id('kw').send_keys('测试一下')
driver.quite()



















 1953
1953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











