




一、分词简介
分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符, 分词过程就是找到这样分界符的过程。
举个栗子:
工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作
==>
[‘工信处’, ‘女干事’, ‘每月’, ‘经过’, ‘下属’, ‘科室’, ‘都’, ‘要’, ‘亲口’, ‘交代’, ‘24’, ‘口’, ‘交换机’, ‘等’, ‘技术性’, ‘器件’, ‘的’, ‘安装’, ‘工作’]
分词的作用:
词作为语言语义理解的最小单元,是人类理解文本语言的基础。因此也是 AI 解决 NLP 领域高阶任务,如自动问答、机器翻译、文本生成的重要基础环节。
(1)中英文分词的 3 个典型区别:
1)分词方式不同,中文更难英文有天然的空格作为分隔符,但是中文没有。所以如何切分是一个难点,再加上中文里一词多意的情况非常多,导致很容易出现歧义。
2)英文单词有多种形态
英文单词存在丰富的变形变换。为了应对这些复杂的变换,英文NLP相比中文存在一些独特的处理步骤,我们称为词形还原(Lemmatization)和词干提取(Stemming)。中文则不需要
词性还原:does,done,doing,did 需要通过词性还原恢复成 do。词干提取:cities,children,teeth 这些词,需要转换为 city,child,tooth”这些基本形态
3)中文分词需要考虑粒度问题
例如「中国科学技术大学」就有很多种分法:
中国科学技术大学
中国 \ 科学技术 \ 大学中国 \ 科学 \ 技术 \ 大学
粒度越大,表达的意思就越准确,但是也会导致召回比较少。所以中文需要不同的场景和要求选择不同的粒度。这个在英文中是没有的。

(2)中文分词的3大难点
1)没有统一的标准目前中文分词没有统一的标准,也没有公认的规范。不同的公司和组织各有各的方法和规则。
2)歧义词如何切分
例如「兵乓球拍卖完了」就有2种分词方式表达了2种不同的含义:
乒乓球 \ 拍卖 \ 完了 乒乓 \ 球拍 \ 卖 \ 完了 难点
3)新词的识别
信息爆炸的时代,三天两头就会冒出来一堆新词,如何快速的识别出这些新词是一大难点。比如当年「蓝瘦香菇」大火,就需要快速识别。

二、常用分词工具
1、jieba
jieba 的特性:
1)支持多种分词模式
精确模式
全模式
搜索引擎模式2)支持中文繁体分词
3)支持用户自定义词典
(1)jieba 的安装:
pip install jieba
(2)精确模式分词
试图将句子最精确地切开,适合文本分析。
>>> import jieba >>> content = "工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作" >>> jieba.cut(content, cut_all=False) # cut_all默认为False # 将返回一个生成器对象 <generator object Tokenizer.cut at 0x7f065c19e318> # 若需直接返回列表内容, 使用jieba.lcut即可 >>> jieba.lcut(content, cut_all=False) ['工信处', '女干事', '每月', '经过', '下属', '科室', '都', '要', '亲口', '交代', '24', '口', '交换机', '等', '技术性', '器件', '的', '安装', '工作']
(3)全模式分词
把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能消除歧义。
>>> import jieba >>> content = "工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作" >>> jieba.cut(content, cut_all=True) # cut_all默认为False # 将返回一个生成器对象 <generator object Tokenizer.cut at 0x7f065c19e318> # 若需直接返回列表内容, 使用jieba.lcut即可 >>> jieba.lcut(content, cut_all=True) ['工信处', '处女', '女干事', '干事', '每月', '月经', '经过', '下属', '科室', '都', '要', '亲口', '口交', '交代', '24', '口交', '交换', '交换机', '换机', '等', '技术', '技术性', '性器', '器件', '的', '安装', '安装工', '装工', '工作']
(4)搜索引擎模式分词
在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
>>> import jieba >>> content = "工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作" >>> jieba.cut_for_search(content) # 将返回一个生成器对象 <generator object Tokenizer.cut at 0x7f065c19e318> # 若需直接返回列表内容, 使用jieba.lcut_for_search即可 >>> jieba.lcut_for_search(content) ['工信处', '干事', '女干事', '每月', '经过', '下属', '科室', '都', '要', '亲口', '交代', '24', '口', '交换', '换机', '交换机', '等', '技术', '技术性', '器件', '的', '安装', '工作'] # 对'女干事', '交换机'等较长词汇都进行了再次分词. ```
(5)中文繁体分词
针对中国香港,台湾地区的繁体文本进行分词。
>>> import jieba >>> content = "煩惱即是菩提,我暫且不提" >>> jieba.lcut(content) ['煩惱', '即', '是', '菩提', ',', '我', '暫且', '不', '提'] ```
(6)使用用户自定义词典
添加自定义词典后,jieba能够准确识别词典中出现的词汇,提升整体的识别准确率。
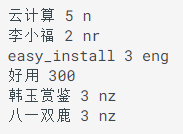
词典格式:每一行分三部分,
词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。jieba 词性对照表如下, 将该词典存为 userdict.txt,方便之后加载使用。
有无使用自定义词典对比:>>> import jieba >>> jieba.lcut("八一双鹿更名为八一南昌篮球队!") # 没有使用用户自定义词典前的结果: >>> ['八', '一双', '鹿'
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5633
5633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









