







注意:该项目只展示部分功能,如需了解,文末咨询即可。
1.开发环境
发语言:python
采用技术:Spark、Hadoop、Django、Vue、Echarts等技术框架
数据库:MySQL
开发环境:PyCharm
2 系统设计
本文围绕大学生毕业就业全流程数据展开,首先在大屏端呈现“考研—就业—出国—公务员—创业—自由职业”六大去向的整体占比及人数;随后联动展示广州、深圳、北京、上海等热门城市的就业人数分布,并以低、中低、中高、高薪四档刻画学生期望薪资区间;进一步对机械、计算机、金融、临床医学等热门专业的具体去向比例进行可视化,揭示不同专业学生的行业流向差异;通过学历(本硕博)与“有无实习经历”交叉分析,验证实习对就业结果与薪资的影响;利用性别、专业、薪资、城市、行业等多维特征对学生进行 K-Means 聚类,得到若干典型就业画像;同时比较男女在同一专业内的平均薪资差距,为性别公平提供量化依据;以城市×行业热力图直观呈现“互联网+北京”“医疗+上海”等高薪高热区,帮助识别区域机会;通过满意度与去向、学历、专业的关联分析,发现公务员群体满意度最高、创业群体两极分化;最后在管理端提供可按任意字段筛选、查看、修改、删除的就业信息列表,实现个案跟踪与数据维护,为高校、政府、学生三方提供一站式决策参考。
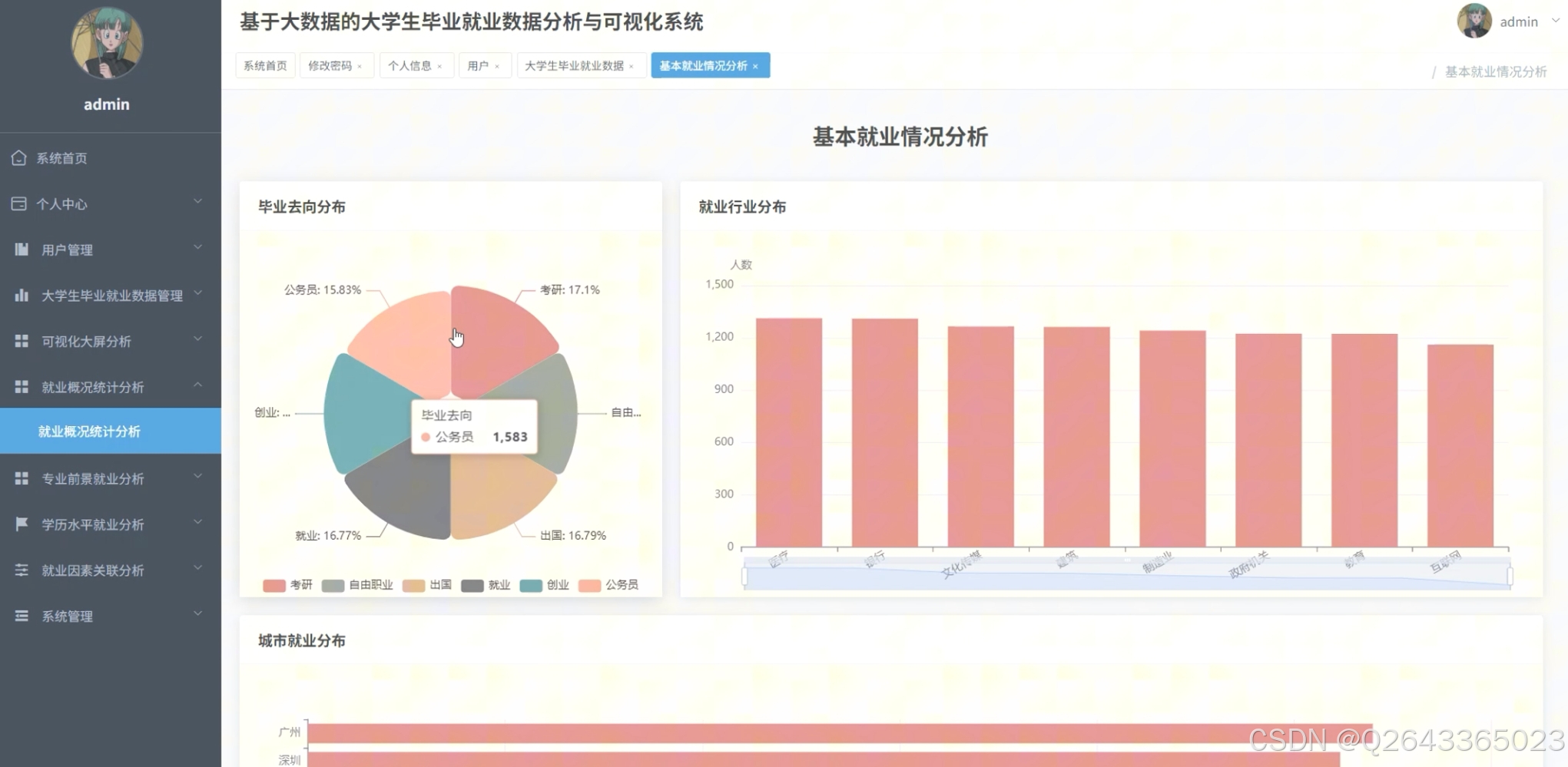
毕业去向全景洞察
从首页大屏可见,系统首先给出“考研、就业、出国、公务员、创业、自由职业”六大去向的占比和人数,帮助管理者一眼看清本届毕业生的总体流向。
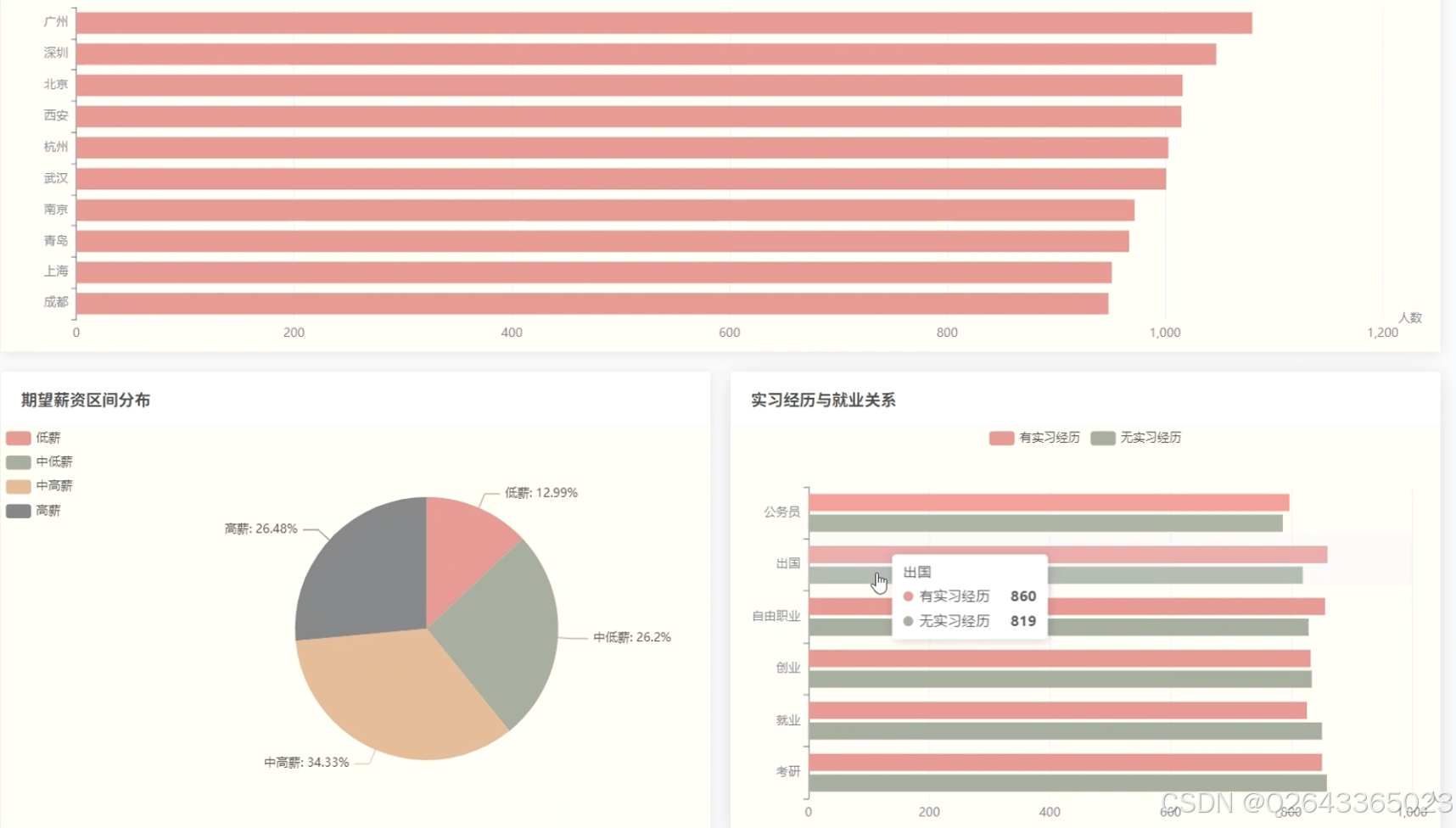
城市-就业地图联动
大屏及“城市就业分布”板块把“广州、深圳、北京、上海、杭州、武汉、成都、南京、青岛、西安”等热门城市的人数柱状图与地图联动,回答“学生都去了哪些城市”。
期望薪资区间画像
系统用“低薪、中低薪、中高薪、高薪”四档展示学生期望薪资的分布比例,并与“是否考研、是否出国、是否公务员”等去向做交叉,揭示“高薪追求者更爱出国,低薪区间集中在公务员”这类规律。
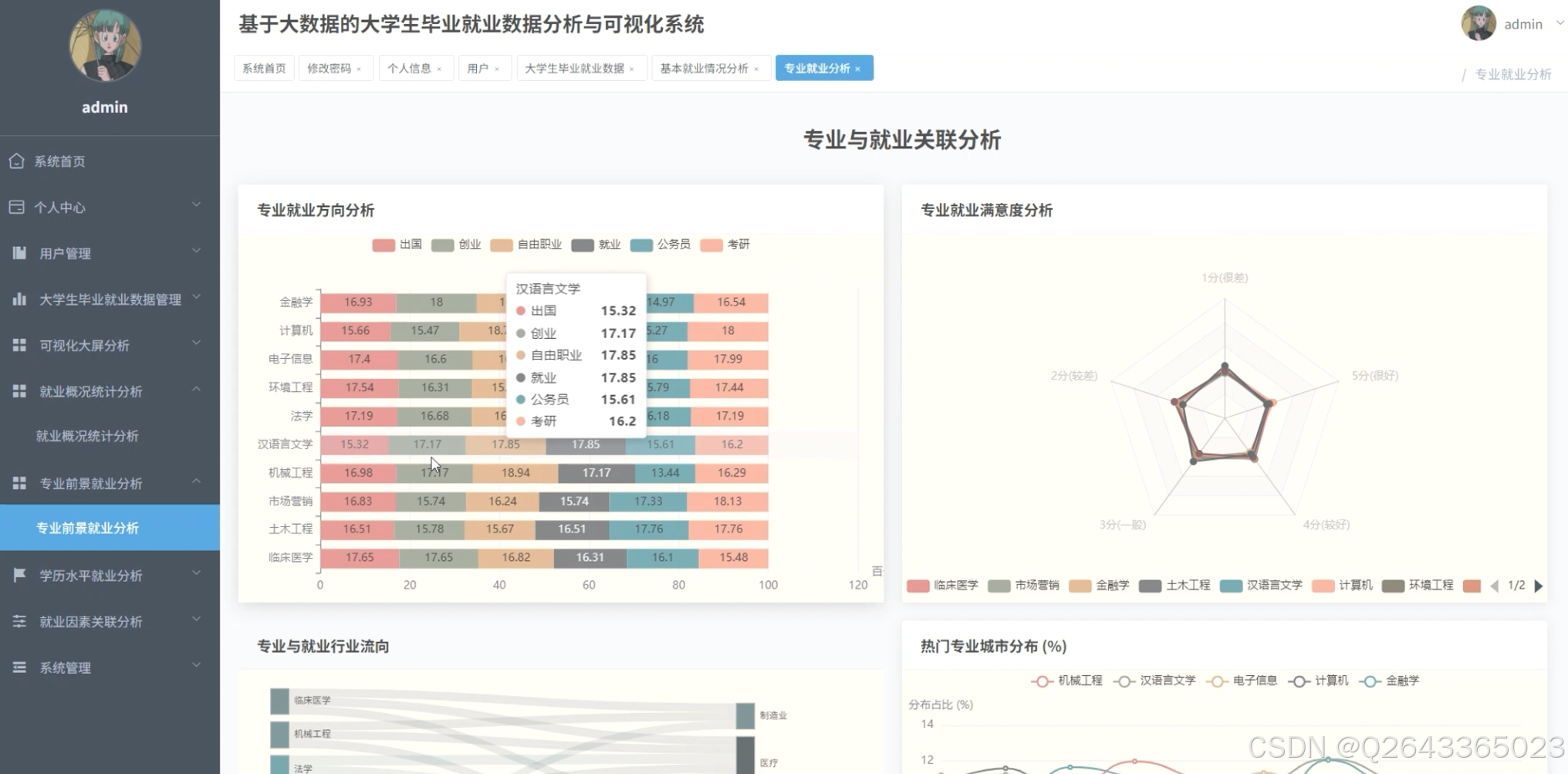
热门专业流向解剖
“热门专业就业方向”模块列出机械、计算机、金融、汉语言文学、临床医学、环境工程等专业的具体去向百分比,直观回答“学计算机的学生有多少去互联网、多少去制造业”。
学历-实习-去向关系
“学历、实习与就业去向关系”板块把“本科、硕士、博士”与“有无实习经历”做矩阵:
• 有实习者 → 就业、高薪比例高;
• 无实习者 → 考研、自由职业比例高。
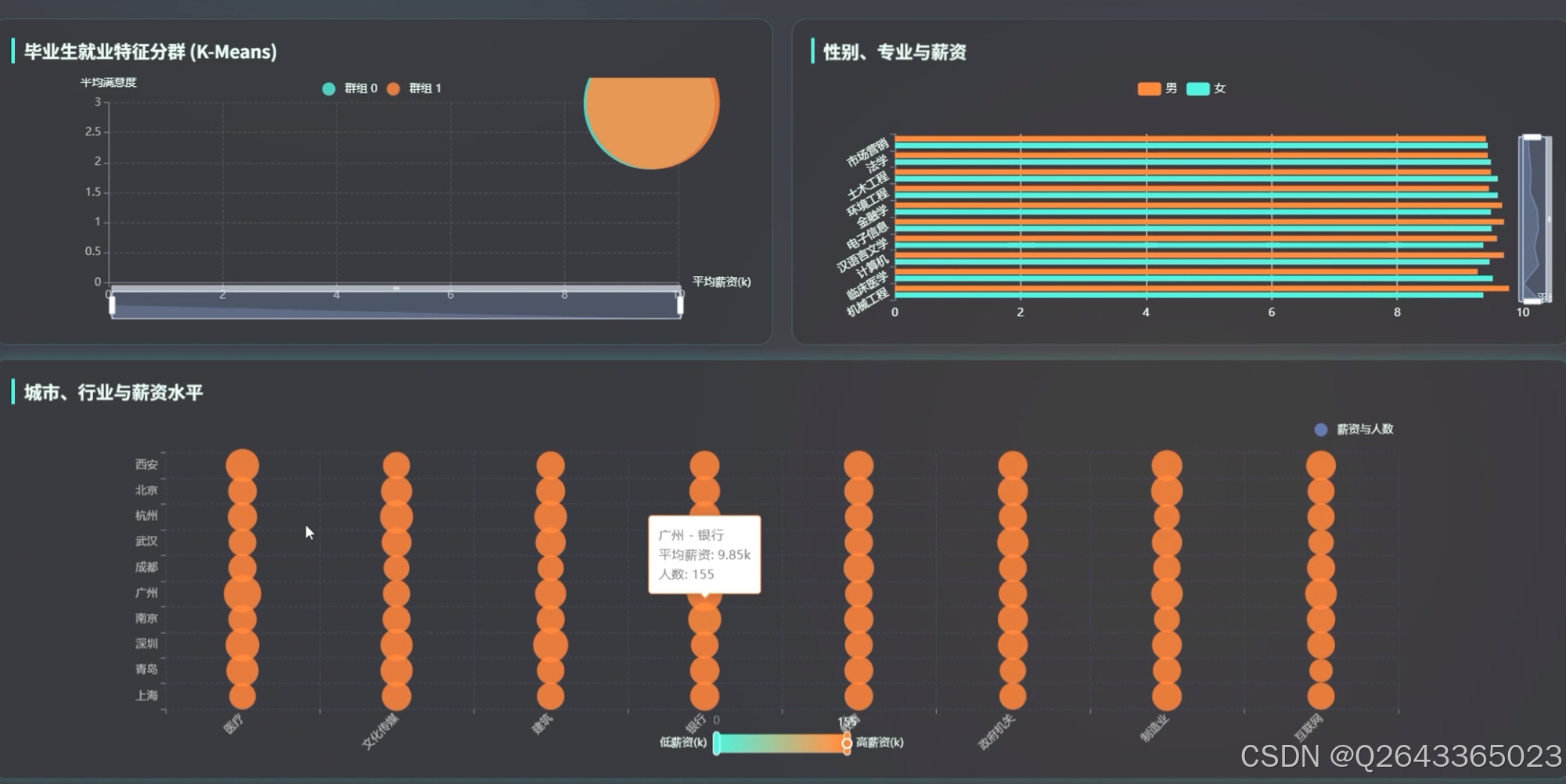
毕业生特征分群
“毕业生就业特征分群(K-Means)”用性别、专业、薪资、城市、行业等字段把学生自动聚成若干群体,例如“群组0:女-医学-高薪-一线”或“群组1:男-工科-中薪-新一线”,方便学校做精细化指导。
性别-专业-薪资差异
“性别、专业与薪资”板块用简单条形图对比“男/女在同一专业的平均薪资差距”,如“汉语言文学女生比男生低 2.25%”,为性别平等干预提供量化依据。
城市-行业-薪资热力图
系统把“城市×行业”生成热力图,一眼看到“互联网+北京”“医疗+上海”处于高薪高热区,“制造业+三线”处于低薪低热区。
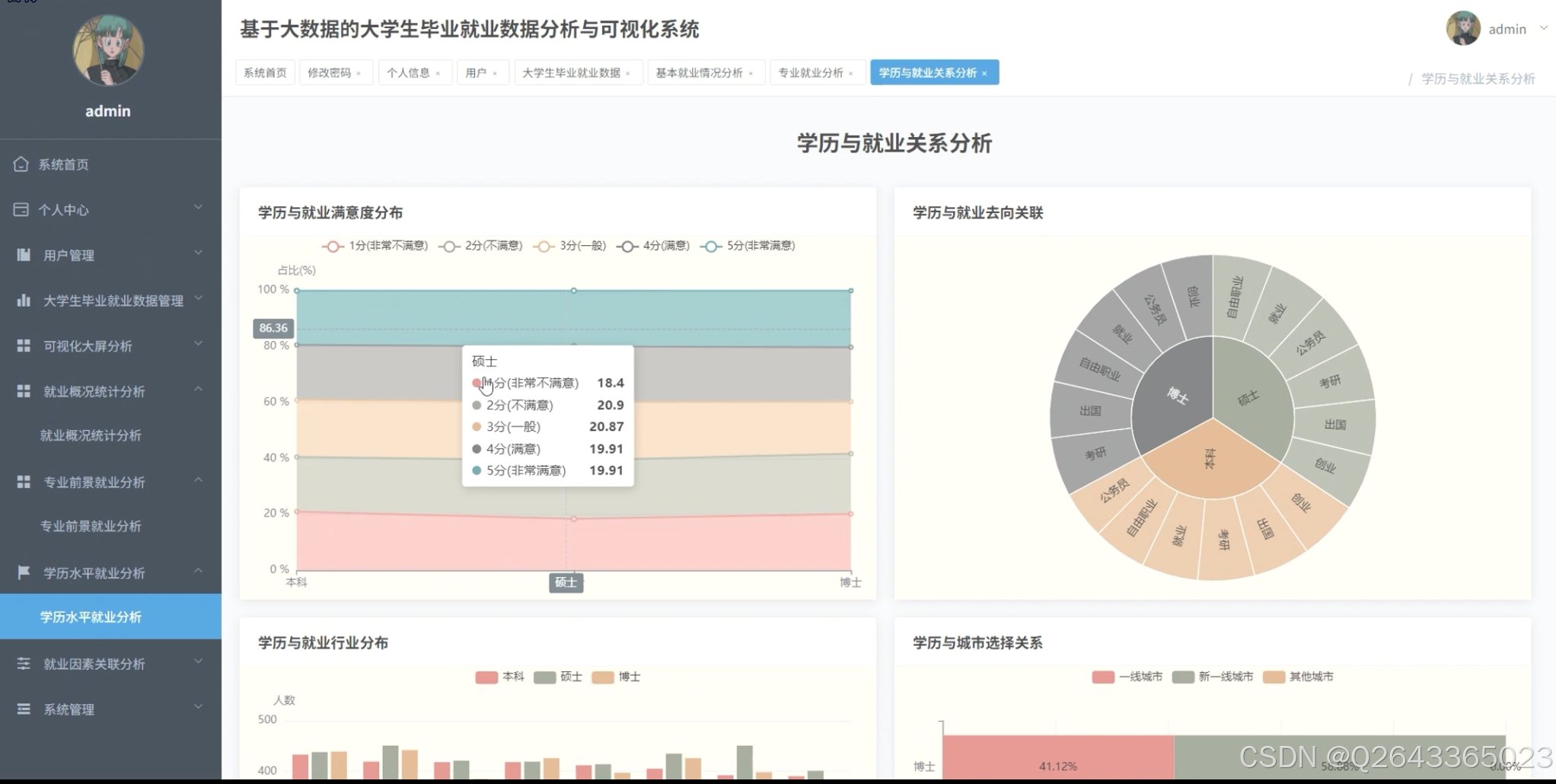
满意度多维度拆解
“专业、学历与满意度关联”“学历与就业满意度分布”等页面将1-5分满意度与去向、学历、专业交叉:
• 公务员群体满意度最高;
• 创业群体满意度两极分化;
• 博士对出国满意度高,对就业满意度低。
就业信息精细化管理
在“就业信息管理”列表里,管理者可按“专业、城市、行业、学历、毕业去向、期望薪资、实习经历”任意筛选、查看、修改或删除单条学生记录,实现个案追踪与数据维护。
3 系统展示
3.1 功能展示视频
基于大数据的大学生毕业就业数据分析与可视化系统Spark源码 !!!请点击这里查看功能演示!!!
3.2 大屏页面

3.3 分析页面


3.4 基础页面

4 更多推荐
计算机毕设选题精选汇总
100个高通过率计算机毕设题目推荐
2025年最全的计算机软件毕业设计选题大全
计算机毕业设计最新Java开发毕业论文参考文献
(2022-2024年)近三年springboot参考文献
基于大数据的B站热门评论情感分析与可视化
5 部分功能代码
# 1. 读取原始 CSV 并做基础清洗(字段名与截图保持一致)
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, when
spark = SparkSession.builder \
.appName("GraduateEmploymentETL") \
.enableHiveSupport() \
.getOrCreate()
df = spark.read.option("header", "true") \
.option("inferSchema", "true") \
.csv("hdfs:///data/graduate_raw.csv")
# 缺失值、异常值处理
df = df.filter(col("salary").isNotNull()) \
.withColumn("salary", when(col("salary") < 2000, None).otherwise(col("salary"))) \
.na.fill({"salary": 0, "city": "未知", "major": "未知"})
# 将类别变量转为索引
from pyspark.ml.feature import StringIndexer
indexers = [StringIndexer(inputCol=col, outputCol=col+"_idx").fit(df) for col in ["gender", "major", "city", "destination"]]
for indexer in indexers:
df = indexer.transform(df)
# 2. 构造特征向量(学历、实习、薪资、索引化类别)
from pyspark.ml.feature import VectorAssembler
feature_cols = ["education_index", "internship_idx", "salary", "major_idx", "city_idx"]
assembler = VectorAssembler(inputCols=feature_cols, outputCol="features")
df_feat = assembler.transform(df)
# 3. K-Means 聚类:把学生分成 4 个就业画像群体
from pyspark.ml.clustering import KMeans
kmeans = KMeans(k=4, seed=42, featuresCol="features", predictionCol="cluster")
model = kmeans.fit(df_feat)
result = model.transform(df_feat)
# 保存结果到 Hive 供可视化读取
result.select("student_id", "gender", "major", "city", "salary", "destination", "cluster") \
.write.mode("overwrite").saveAsTable("employment.cluster_result")
dest_summary = df.groupBy("destination").agg(count("*").alias("num"))\
.withColumn("ratio", _round(col("num")/df.count()*100, 2))
dest_summary.orderBy(col("num").desc())\
.write.mode("overwrite").saveAsTable("employment.dest_distribution")
city_salary = df.groupBy("city")\
.agg(count("*").alias("people"),
avg("salary").alias("avg_salary"))\
.filter(col("city").isNotNull())\
.orderBy(col("people").desc())\
.limit(10)
city_salary.write.mode("overwrite").saveAsTable("employment.city_salary")
city_salary = df.groupBy("city")\
.agg(count("*").alias("people"),
avg("salary").alias("avg_salary"))\
.filter(col("city").isNotNull())\
.orderBy(col("people").desc())\
.limit(10)
city_salary.write.mode("overwrite").saveAsTable("employment.city_salary")
gender_major_salary = df.groupBy("gender", "major")\
.agg(avg("salary").alias("avg_salary"),
count("*").alias("sample_size"))\
.filter(col("sample_size") > 10) # 去掉样本过少专业
gender_major_salary.write.mode("overwrite").saveAsTable("employment.gender_major_salary")
intern_dest = df.groupBy("internship", "destination")\
.agg(count("*").alias("people"))\
.withColumn("internship", when(col("internship")==1, "有实习").otherwise("无实习"))
# 可进一步透视
intern_dest.write.mode("overwrite").saveAsTable("employment.intern_dest")
源码项目、定制开发、文档报告、PPT、代码答疑
希望和大家多多交流 ↓↓↓↓↓

















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









