




前提背景:算法想要工程部署模型推理服务,基于之前的AI平台系统调用模型基于当前的请求特征是未embedding 过的,例子: [{a:‘1’}] ,现在需要调研模型推理工具实现 支持当下业务系统调用模型。
需求: 1.支持pytorch 2.能够后端预处理特征 3.性能满足 4.使用GPU
调研后,torchserver 和 triton 都可以,如果想要看torchserve 的部署可以看我之前的博客
话不多说,下面是trtion 的介绍
Triton Inference Server是一个适用于深度学习与机器学习模型的推理服务引擎,支持将TensorRT、TensorFlow、PyTorch或ONNX等多种AI框架的模型部署为在线推理服务,并支持多模型管理、自定义backend等功能。本文为您介绍如何通过镜像部署的方式部署Triton Inference Server模型服务。
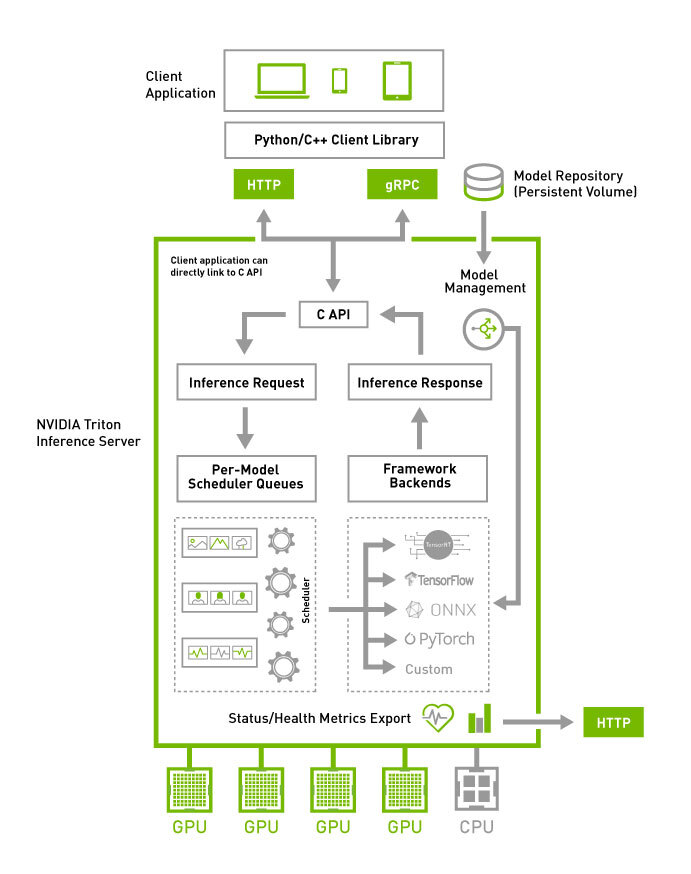
triton的一些优点
通过上述的两个结构图,可以大概知道triton的一些功能和特点:
支持HTTP/GRPC
支持多backend,TensorRT、libtorch、onnx、paddle、tvm啥的都支持,也可以自己custom,所以理论上所有backend都可以支持
单GPU、多GPU都可以支持,CPU也支持
模型可以在CPU层面并行执行
很多基本的服务框架的功能都有,模型管理比如热加载、模型版本切换、动态batch,类似于之前的tensorflow server
开源,可以自定义修改,很多问题可以直接issue,官方回复及时
NVIDIA官方出品,对NVIDIA系列GPU比较友好,也是大厂购买NVIDIA云服务器推荐使用的框架
很多公司都在用triton,真的很多,不管是互联网大厂还是NVIDIA的竞品都在用,用户多代表啥不用我多说了吧
基于算法的需求,我选择backend
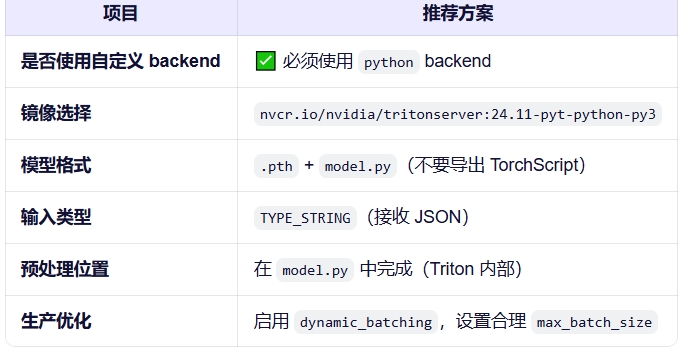
目录结构:
/model_repository
├── 1
│ ├── model.py # 模型对应的脚本文件
│ ├── xxx.pth # 模型文件
└── config.pbtxt # 模型配置文件


model.py
1、必须以 “TritonPythonModel” 为类名
2、需要提供三个接口:
initialize, execute, finalize。
1.其中 initialize 和 finalize 是模型实例初始化、模型实例清理的时候会调用的。如果有 n 个模型实例,那么会调用 n 次这两个函数。
2.execute 为实际的请求接收方法
模型执行函数,必须实现;每次请求推理都会调用该函数,若设置了 batch 参数,还需由用户自行实现批处理功能
Parameters
requests : pb_utils.InferenceRequest类型的请求列表。
Returns
pb_utils.InferenceResponse 类型的返回列表。列表长度必须与请求列表一致。
import json
import os
import time
import numpy as np
import torch
import torch.nn as nn
import triton_python_backend_utils as pb_utils
import logging
import model_preprocess
import data_preprocess
from feature_column import (
int_feature_column,
str_feature_column,
strlist_feature_column,
intlist_feature_column,
label_name,
)
import pandas as pd
# ==============================
# 模型定义:Wide_Deep_DSN
# ==============================
class Wide_Deep_DSN(nn.Module):
xxxxx
return torch.sigmoid(output)
# ==============================
# Triton Python Backend
# ==============================
class TritonPythonModel:
def initialize(self, args):
self.model_path = "/models/dsn/1/best_model_8.pth"
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.config = {
"num_unique_int": 210,
"num_list_int": 0,
"num_unique_strs": [31, 3, 5, 7, 6, 14, 31, 191, 6, 15, 17, 50, 43, 420, 253, 188, 17, 10, 10],
"num_list_strs": 331,
"str_embedding_dim": [4, 4],
"list_embedding_dims": 6,
"list_embedding_num": 2,
"factor_dim": 10,
}
try:
self.model = Wide_Deep_DSN(**self.config)
state_dict = torch.load(self.model_path, map_location="cpu")
self.model.load_state_dict(state_dict)
self.model.to(self.device)
self.model.eval()
self.int_feature_column = int_feature_column
self.str_feature_column = str_feature_column
self.strlist_feature_column = strlist_feature_column
self.intlist_feature_column = intlist_feature_column
self.label_name = label_name
pb_utils.Logger.log_info(f"[INFO] Model loaded successfully on {self.device}")
except Exception as e:
pb_utils.Logger.log_error(f"[ERROR] Failed to load model: {e}")
raise
def execute(self, requests):
responses = []
start_time = time.time()
pb_utils.Logger.log_info(f"Received {len(requests)} requests")
pb_utils.Logger.log_info(f"----- requests: {requests}")
# ----------------------------
# 1. 解析输入:获取 input_json tensor
# ----------------------------
responses = []
# if len(responses) == len(requests): # 全部解析失败
# return responses
# 预处理
try:
# ----------------------------
for request in requests:
try:
input_list = []
# 1. 解析 input_json
in_tensor = pb_utils.get_input_tensor_by_name(request, "input_json")
np_array = in_tensor.as_numpy()
pb_utils.Logger.log_info(f"----- np_array: {np_array}")
for row in np_array:
json_str = row[0].decode('utf-8') # 假设每行只有一个元素
input_list.append(json.loads(json_str))
except Exception as e:
pb_utils.Logger.log_error(f"Request parsing failed: {e}")
responses.append(
pb_utils.InferenceResponse(
error=pb_utils.TritonError(message=str(e), code=400)
)
)
processed_results = self.preprocess(input_list)
final_output= self.inference(processed_results)
final_output = np.array(final_output, dtype=np.float32).reshape(-1, 1) # [B, 1]
pb_utils.Logger.log_info(f"----- final_output: {final_output}")
# 每个请求对应一个 response
# ✅ 关键:转为 numpy array
# 构造输出 tensor(支持 N 个结果)
out_tensor = pb_utils.Tensor("output", final_output)
response = pb_utils.InferenceResponse(output_tensors=[out_tensor])
responses.append(response)
except Exception as e:
pb_utils.Logger.log_error(f"Inference failed: {e}")
# 返回统一错误(可选:每个请求都返回错误)
error_resp = pb_utils.InferenceResponse(
error=pb_utils.TritonError(message=str(e), code=500)
)
responses = [error_resp] * len(requests)
pb_utils.Logger.log_info(f"execute completed in {time.time() - start_time:.4f}s")
return responses
def finalize(self):
pb_utils.Logger.log_info("[INFO] Finalizing model...")
if hasattr(self, 'model'):
del self.model
torch.cuda.empty_cache()
def preprocess(self, input_batch):
"""
input_batch: List[dict] or List[List[dict]]
返回: 所有特征张量(已to(device)),形状为 [B, ...]
"""
start_time = time.time()
pb_utils.Logger.log_info(f"Preprocessing {len(input_batch)} samples")
pb_utils.Logger.log_info(f"-----preprocess input_batch data: {input_batch}")
features_dicts = []
valid_indices = []
error_flags = []
for idx, item in enumerate(input_batch):
# data
raw = item
if raw is None:
pb_utils.Logger.log_warn(f"Missing 'data' in sample {idx}")
error_flags.append(True)
continue
if isinstance(raw, str):
try:
raw = json.loads(raw)
except Exception as e:
pb_utils.Logger.log_warn(f"JSON decode failed for sample {idx}: {e}")
error_flags.append(True)
continue
if isinstance(raw, dict):
features_dicts.append(raw)
valid_indices.append(idx)
error_flags.append(False)
elif isinstance(raw, list):
for d in raw:
if isinstance(d, dict):
features_dicts.append(d)
valid_indices.append(idx)
error_flags.append(False)
else:
error_flags.append(True)
else:
error_flags.append(True)
pb_utils.Logger.log_info(f"features_dicts {features_dicts}")
if not features_dicts:
pb_utils.Logger.log_warn("No valid input after preprocessing")
return None, error_flags
df = pd.DataFrame(features_dicts)
pb_utils.Logger.log_info(f"-----converted batch DataFrame: {df}" )
processed_df = data_preprocess.process_data(
df,
self.intlist_feature_column,
self.str_feature_column,
self.strlist_feature_column,
self.int_feature_column,
self.label_name,
label="eval"
)
processor = model_preprocess.DataProcessor(
processed_df, self.str_feature_column, self.strlist_feature_column
)
int_feats, intlist_feats, str_feats, list_feats = processor.process_all_features(
processed_df,
self.int_feature_column,
self.intlist_feature_column,
self.str_feature_column,
self.strlist_feature_column
)
processed_results = []
# 构造特征 dict,异常位置填 None
feature_idx = 0
for idx in range(len(features_dicts)):
processed_results.append({
"int_feats": int_feats[feature_idx:feature_idx+1].to(self.device),
"intlist_feats": intlist_feats[feature_idx:feature_idx+1].to(self.device),
"str_feats": str_feats[feature_idx:feature_idx+1].to(self.device),
"list_feats": list_feats[feature_idx:feature_idx+1].to(self.device)
})
feature_idx += 1
pb_utils.Logger.log_info(f"processed_results: {processed_results}")
pb_utils.Logger.log_info(f"preprocess completed in {time.time() - start_time} seconds",)
return processed_results
def inference(self, data):
pb_utils.Logger.log_info(f"inference {len(data)} samples")
"""
批量推理:输入为 list,每个元素为特征 dict。对 None 或异常条目输出 None。
依次将每条 dict(若为合法 dict)送 self.model 独立打分,输出与输入顺序一一对应的 [分数1, 分数2, ...]。
"""
start_time = time.time()
if not isinstance(data, list):
pb_utils.Logger.log_error("Inference input must be list of dicts")
return []
pred_list = []
with torch.no_grad():
if self.device == 'cuda':
cmgr = torch.amp.autocast("cuda")
else:
class DummyContext:
def __enter__(self): pass
def __exit__(self, a, b, c): pass
cmgr = DummyContext()
for idx, sample in enumerate(data):
if not isinstance(sample, dict):
pred_list.append(None)
continue
try:
with cmgr:
outputs = self.model(
sample["int_feats"],
sample["intlist_feats"],
sample["str_feats"],
sample["list_feats"]
)
outputs = outputs.cpu().detach().numpy()
if outputs.size == 1:
pb_utils.Logger.log_info("-----------outputs.size == 1")
pred = float(outputs.item())
pb_utils.Logger.log_info(f"-----------pred: {pred}",)
else:
pb_utils.Logger.log_info("-----------outputs.size >1")
pred = outputs.squeeze().tolist()
pb_utils.Logger.log_info(f"-----------pred: {pred}",)
pred_list.append(pred)
except Exception as e:
pb_utils.Logger.log_error(f"Inference failed at idx {idx}: {e}")
pred_list.append(None)
pb_utils.Logger.log_info(f"Inference completed in {time.time() - start_time} seconds",)
pb_utils.Logger.log_info(f"Inference outputs {pred_list}")
return pred_list
config.pbtxt 配置
name: "dsn" 模型名称
platform: "python" # Python Backend! 重点!!!
max_batch_size: 512 # 与你的 batch_size 一致
# 输入
input [
{
name: "input_json"
data_type: TYPE_STRING
dims: [ 1 ] # 每个请求传一个 JSON 字符串
}
]
# 输出
output [
{
name: "output" # TorchScript 输出的默认名称,可用 netron 查看
data_type: TYPE_FP32
dims: [ 1 ] # 输出预测值 [0,1]
}
]
# 关键配置:动态批处理
dynamic_batching {
# 最大等待时间(微秒),攒够一批再推理
preferred_batch_size: [ 8, 16, 32, 64, 128, 256, 512 ]
# 可选:限制 batch size
max_queue_delay_microseconds: 10000 # 10ms
}
# 使用GPU推理
instance_group [
{
kind: KIND_GPU
# 起几个实例
count: 4
}
]
启动命令
docker
docker run -it \
--gpus device=6 \
-p 18000:8000 -p 18001:8001 -p 18002:8002 \
-v /opt/triton_inference_serve/model_repository:/models \
--name triton-pytorch-dsn \
nvcr.io/nvidia/tritonserver:23.12-pyt-python-py3 \
bash
–gpus device=6
选择gpu号
-p 18000:8000 -p 18001:8001 -p 18002:8002
暴露接口
-v /opt/triton_inference_serve/model_repository:/models
挂载模型目录
安装 torch 到 python backend 环境
pip install torch==2.3.1 torchvision==0.18.1 --extra-index-url https://download.pytorch.org/whl/cu121 -i https://pypi.tuna.tsinghua.edu.cn/simple
# 其他依赖
pip install pandas numpy scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
triton
nohup tritonserver \
--model-repository=/models \
--backend-directory=/opt/tritonserver/backends \
--backend-config=python,execution_mode=enabled \
--log-verbose=2 \
--log-file=/models/dsn/logs/triton.log \
> /models/dsn/logs/nohup.out 2>&1 &
–model-repository=/models
指定模型执行地址
–backend-directory=/opt/tritonserver/backends
指定后端启动的python 库
–log-verbose=2 >1 表示开启日志
–log-file=/models/dsn/logs/triton.log
/models/dsn/logs/nohup.out 2>&1 &
nohup启动日志
————————————————
验证是否部署成功
curl http://localhost:8000/v2/models/dsn
{"name":"dsn","versions":["1"],"platform":"python","inputs":[],"outputs":[]}root@238a42bf5042:/models/dsn#
调用推理接口
curl -i -X POST \
-H "Content-Type:application/json; charset=UTF-8" \
-d \
'{
"inputs": [
{
"name": "input_json",
"shape": [1, 1],
"datatype": "BYTES",
"data": [
"{\"yumid\": \"mobile_8xxx\", xxxxx}"
]
}
]
}' \
'http://ip:18000/v2/models/dsn/infer'




















 2788
2788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











