






SQL 实时数据流处理 机器学习 图计算 4大子框架
1图计算GraphX,下面是一栈式解决GraphX和GraphLab的对比 相比之下 虽然GraphX没有GraphLab快 但一栈式解决让整体更好
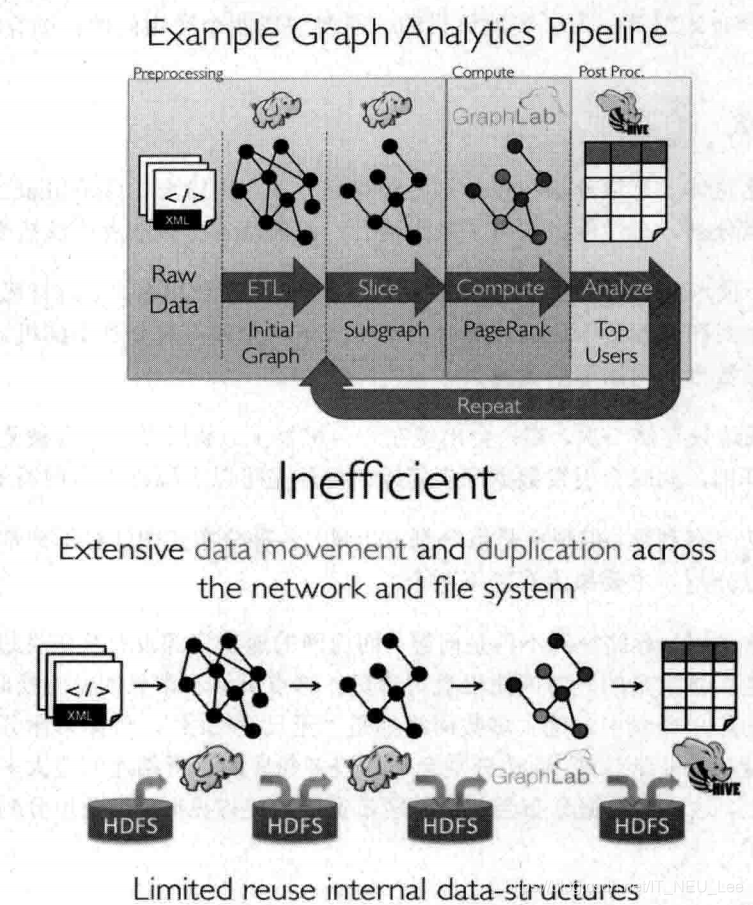
图存储模式:巨型图的存储有边分割(每个顶点都存储一次,但边可能被分到不同的机器,如果基于边的计算,那么跨机器通信变大)和点分割(边只存储一次)
2实时流处理框架spark streaming
spark streaming把输入数据按照batch size分成一段一段的discretized stream(DStream),每一段数据都转换成spark中的RDD
3交互式SQL处理框架 spark SQL
有如下特点:
1 能在Scala代码里写SQL 2 支持parquet文件(列式存储格式的文件系统,使用parquent文件进行读写,可以极大的降低对于cup和磁盘I/O的消耗)的读写,且保留scheme 3支持直接多json格式数据操作 4 能在Scala代码里访问hive元数据,能执行hive语句,并且把结果返回作为rdd
4机器学习框架spark MLlib (机器学习算法库,同时包含相关的测试和数据生成器,支持二元分类·回归·聚类·协同过滤)

















 550
550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









